使用SVM与随机森林对wine数据集进行葡萄酒类别识别
需积分: 0 121 浏览量
更新于2024-08-03
收藏 279KB DOCX 举报
"ml-pro-repo"
在"ml-pro-repo"这个项目中,主要探讨的是使用机器学习,特别是支持向量机(SVM)和随机森林算法对葡萄酒数据集"Wine"进行分析和分类。这个数据集源自UCI机器学习库,包含178个样本,每个样本有14个特征,用于描述不同类型的葡萄酒。第一列是类别标签,用1、2、3来区分三种葡萄酒,其余13列则表示13种不同的葡萄酒成分。
在进行分析时,首先对数据进行预处理,包括变量命名、处理相关性强的数据(可能考虑去除相关性过高的特征以防止过拟合),接着对数据进行混洗并按5:3:2的比例划分成训练集、验证集和测试集。数据预处理还包括归一化,确保所有特征在同一尺度上。接下来,尝试了四种不同的核函数:线性核、多项式核、RBF高斯核和sigmoid核,通过比较不同核函数下的分类准确率来选择最优的核函数类型。同时,通过调整SVM的参数C和gamma,寻找最佳的模型配置。
在选定核函数和参数后,会在训练集上构建SVM模型,并在验证集和测试集上评估其性能。此外,还利用训练集构建了随机森林模型,这是一种集成学习方法,由多棵决策树组成。随机森林通过在训练过程中引入随机性,如随机抽取子集样本和特征,提高了模型的泛化能力。通过测试集,可以评估随机森林模型的性能,并获得特征的重要性排序,这有助于理解哪些特征对分类影响最大和最小。
评价指标通常包括准确率、精确率、召回率、F1分数等,这些指标可以帮助评估模型在识别不同类别葡萄酒上的表现。在SVM中,可能还会关注间隔(margin)和误分类率。随机森林中,特征重要性是通过观察各个特征在所有决策树中的平均信息增益或减少不纯度来计算的。
"ml-pro-repo"项目展示了如何运用机器学习技术,尤其是SVM和随机森林,对非线性数据进行有效分类,并提供了数据预处理、模型选择、参数调优以及性能评估的全面流程。通过这种方法,可以实现计算机对葡萄酒成分的自动识别,为类似的问题提供了一个实用的解决方案。
1、wine 数据集的描述
本文 Wine 数据来自 UCI 数据库中下载的 wine.data 文件,并且使用核函数
SVM 支持向量机的方式进行机器学习分析,从而实现计算机对三种葡萄酒的成分
分析并且进行自动识别类别。
分析 wine.data 文件我们可以看出,wine.data 文件中分为 178 行、14 列,
分别对应着 178 行的不同葡萄酒的成分数据;第 1 列葡萄酒的种类,使用 1/2/3
来进行区分,后 13 列分别代表 13 种不同的葡萄酒的成分数据,分别为 1)
Alcohol,2) Malic acid,3) Ash,4) Alcalinity of ash,5) Magnesium,6)
Total phenols,7) Flavanoids,8) Nonflavanoid phenols,9)
Proanthocyanins,10)Color intensity,11)Hue,12)OD280/OD315 of diluted
wines,13)Proline,然后进行训练与分类。
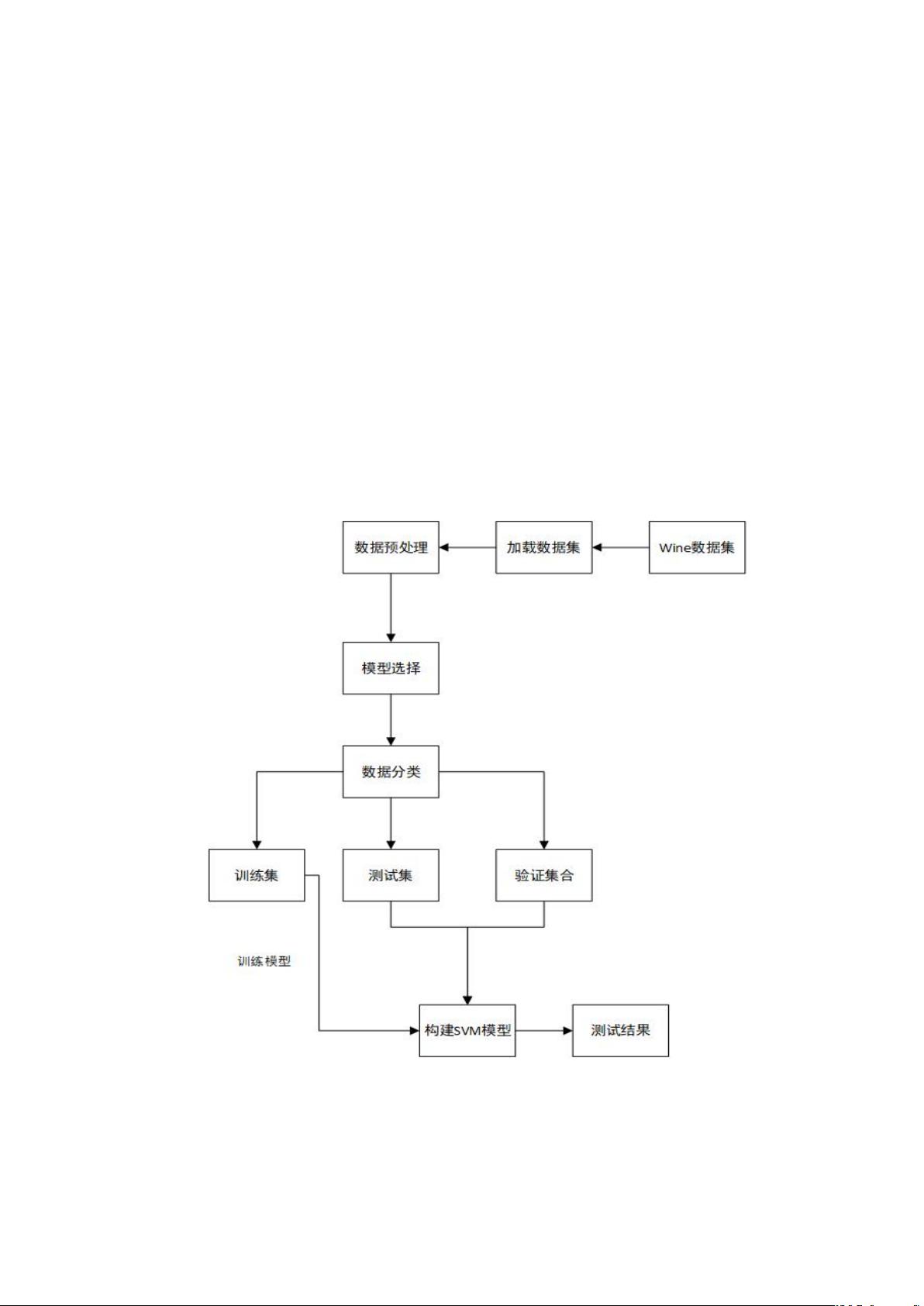
2、分类系统流程图,并简述怎样训练怎样识别
本文先处理 wine.data 数据,将各个变量进行命名,然后处理关联性较高的
数据进行取舍,减小过拟合的可能;接着将数据随机混合并且按照 5:3:2 的比
例分割为训练集、验证集和测试集,然后进行归一化处理;之后从线性核函数、
多项式核函数、RBF 高斯核函数和 sigmoid 核函数 4 个不同的核函数 kernel 选
下载后可阅读完整内容,剩余6页未读,立即下载
2022-01-01 上传
2021-03-20 上传
2021-02-14 上传
2021-02-14 上传
2021-06-04 上传
2021-02-06 上传
2021-05-13 上传

liuere
- 粉丝: 12
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
