Spark分布式计算原理与RDD详解
需积分: 13 114 浏览量
更新于2024-08-04
收藏 883KB DOC 举报
"Spark学习笔记,涵盖了Spark的基本概念、RDD的工作原理、特性和编程模型,强调了其在大数据处理中的重要角色。"
Spark是大数据处理领域的一个重要工具,以其高效、易用和灵活性著称。分布式计算是Spark的核心,它通过将任务分解成多个子任务并分布到多个Executor上进行并行计算,从而提高了处理速度。在Spark中,Resilient Distributed Dataset (RDD) 是核心的数据结构,它是一个不可变、分区的记录集合,具备容错能力。
RDD的特性包括:
1. 弹性:RDD支持存储弹性,能自动在内存和磁盘之间切换,确保数据的持久性和可用性。同时,它有容错机制,当数据丢失时可以自动恢复。计算弹性意味着计算失败时可以重试,确保任务最终完成。分区的弹性允许用户动态调整分区数量以适应不同的并行度需求。
2. 不保存数据:RDD自身并不存储数据,而是存储计算逻辑。这意味着每次对RDD的操作都会生成新的RDD,而原RDD保持不变,遵循了函数式编程的不变性原则。
3. 抽象类:RDD作为一个抽象类,需要通过子类化来具体实现数据处理逻辑。
4. 分区和并行计算:RDD的分区列表是实现并行计算的关键,每个分区都有自己的计算函数,通过这些函数在Executor上执行任务。
5. 依赖关系:RDD之间存在依赖关系,这种关系定义了数据的转换路径,有助于Spark优化执行计划。
6. 分区器和首选位置:用户可以通过设定分区器来控制数据的分布,首选位置策略则能确保任务尽可能在数据所在节点执行,减少网络传输,提高效率。
RDD的编程模型主要包括转换方法和动作方法。转换方法(如map、filter)创建新的RDD而不立即执行,动作方法(如count、collect)触发实际计算。例如,`groupByKey()` 方法将相同键的值聚集在一起,但请注意,这会导致数据的shuffle,即数据在不同分区间重新分布。虽然分区和分组不直接关联,但经过`groupByKey()` 后,相同键的值会被分配到同一分区,不过一个分区可能包含多个分组。
理解Spark的RDD机制对于有效地编写Spark程序至关重要,因为它可以帮助开发者充分利用Spark的并行计算能力和容错机制,从而高效地处理大规模数据。
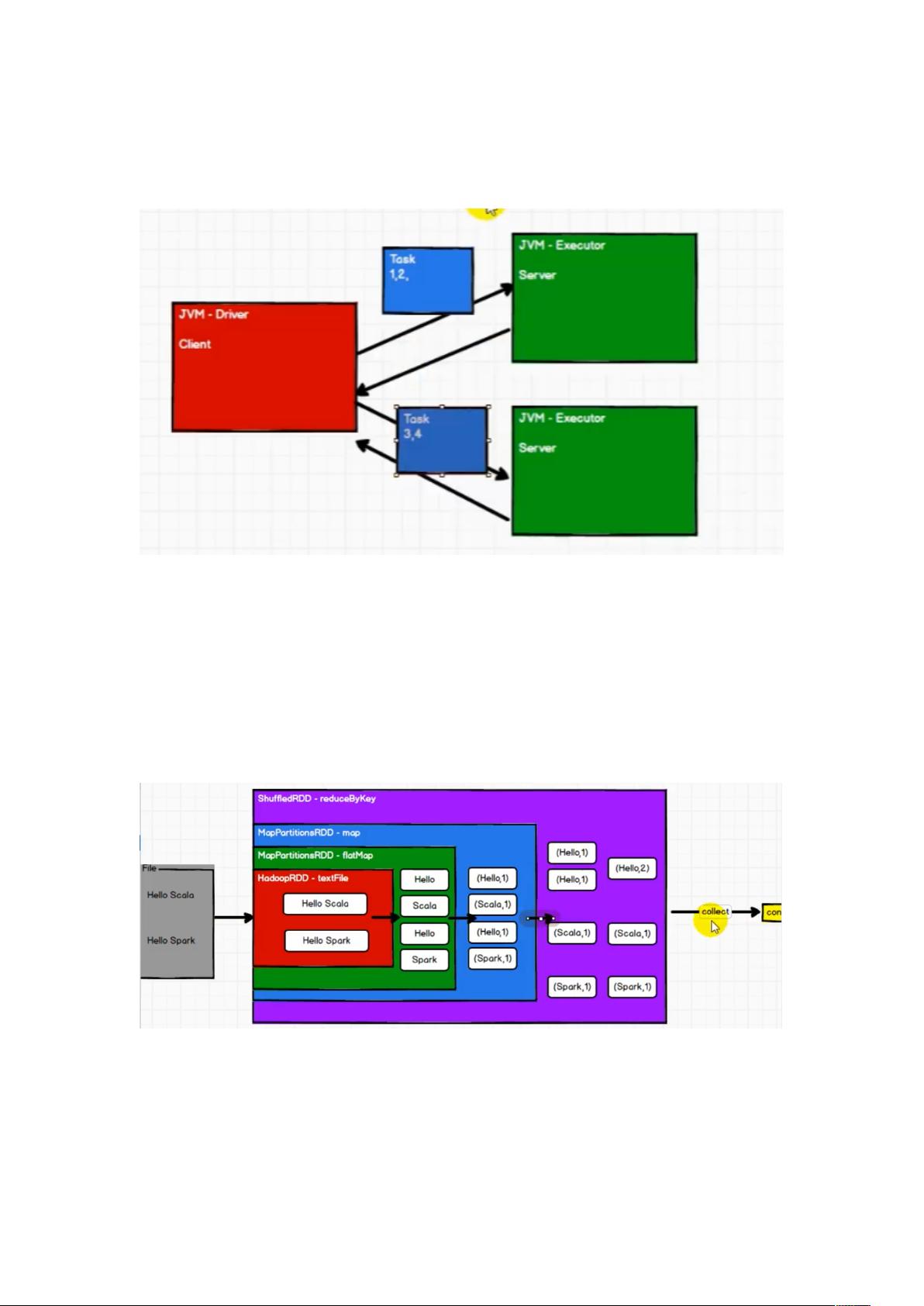
1. 分布式计算原理
我们将任务提交到 Driver 端,Driver 端将我们提交的任务分解成多个子任务,然后将数据拆
分,发送给 Executor, 真正的计算在 Executor。在 Spark 中,RDD 就是 spark 为我们封装好的
数据结构,driver 将 RDD 以及算子和函数发送给 Driver 让它去执行,然后再返回给 Driver。
2. RDD 与 IO 的关系
以 wordcount 为例
RDD 的数据处理方式类似于 IO 流,也是利用了装饰着设计模式,采用了延迟加载的原理,
在只有在发生 action 操作的时候才会进行真正的计算。
RDD 是不保存数据的,只保存计算逻辑,IO 流会缓存数据。
RDD 是最小的计算单元,不会封装太复杂的逻辑,复杂的功能需要多个 RDD 的组合实现。
下载后可阅读完整内容,剩余4页未读,立即下载
192 浏览量
105 浏览量
111 浏览量
142 浏览量
209 浏览量
117 浏览量
153 浏览量
608 浏览量

_leon1999
- 粉丝: 33
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android PRDownloader库:支持文件下载暂停与恢复功能
- Xilinx FPGA开发实战教程(第2版)精解指南
- Aprilstore常用工具库的Java实现概述
- STM32定时开关模块DXP及完整项目资源下载指南
- 掌握IHS与PCA加权图像融合技术的Matlab实现
- JSP+MySQL+Tomcat打造简易BBS论坛及配置教程
- Volley网络通信库在Android上的实践应用
- 轻松清除或修改Windows系统登陆密码工具介绍
- Samba 4 2级免费教程:Ubuntu与Windows整合
- LeakCanary库使用演示:Android内存泄漏检测
- .Net设计要点解析与日常积累分享
- STM32 LED循环左移项目源代码与使用指南
- 中文版Windows Server服务卸载工具使用攻略
- Android应用网络状态监听与质量评估技术
- 多功能单片机电子定时器设计与实现
- Ubuntu Docker镜像整合XRDP和MATE桌面环境
