使用Structured Streaming构建易用、可扩展、容错的流处理
需积分: 9 37 浏览量
更新于2024-07-18
收藏 2.8MB PDF 举报
"Easy, Scalable, Fault-tolerant stream processing with Structured Streaming-TD - Spark iteblog - BigDataStreamingMeetup Beijing, 2018 - Tathagata “TD” Das"
在大数据处理领域,流处理已经成为了一个重要的部分,特别是在实时分析和快速响应的应用场景中。Tathagata "TD" Das在2018年北京的大数据流处理 meetup 中,介绍了Spark的Structured Streaming,这是一个旨在简化、扩展并确保容错性的流处理框架。本文将深入探讨Structured Streaming的关键特性以及它如何解决传统流处理中的复杂性问题。
一、Structured Streaming简介
Structured Streaming是Spark SQL的一部分,它利用Spark的高性能和强大的SQL支持,提供了一种结构化的、声明式的API来处理连续的数据流。这个框架的设计目标是让开发者能够像处理静态数据表一样处理数据流,从而简化了编程模型,并提高了开发效率。
二、解决传统流处理的复杂性
1. 复杂数据:Structured Streaming支持多种数据格式,如JSON、Avro和二进制等。它能够处理脏数据、迟到数据和乱序数据,这在实时数据流中是常见的问题。
2. 复杂系统:通过丰富的生态系统与各种存储系统(如SQL数据库、NoSQL数据库和Parquet文件)集成,允许无缝地读写数据,增强了系统的灵活性。
3. 系统故障:基于Spark的分布式架构,Structured Streaming提供了内置的容错机制,确保即使在节点故障的情况下也能持续处理数据流。
4. 复杂工作负载:支持事件时间处理,可以应对复杂的业务逻辑,同时能够与交互式查询和机器学习任务结合,满足多样化的应用场景。
三、核心特性
1. 易用性:通过统一的SQL API,开发者可以轻松地编写处理流数据的查询,而无需关心底层的流处理细节。
2. 扩展性:Structured Streaming可以水平扩展以处理大量数据流,保持低延迟的同时,实现高吞吐量。
3. 容错性:基于微批处理模型,Structured Streaming能够自动处理系统故障,保证数据不丢失。
4. 持续更新答案:当新数据到达时,查询结果会自动更新,提供实时的结果视图。
四、无界数据表的概念
在Structured Streaming中,数据流被视为无界的表格,这意味着数据流没有固定的结束点,可以无限地持续流入。这种抽象使得开发者可以使用SQL查询语言处理无界数据,就像处理静态表一样。
Structured Streaming为开发者提供了一个强大且易用的工具,用于构建健壮的流处理应用,它可以处理复杂的数据和工作负载,同时保证系统的可扩展性和容错性。通过Spark的Structured Streaming,大数据实时分析的门槛被大大降低,使得更多企业和开发者能够轻松地驾驭实时数据洪流。
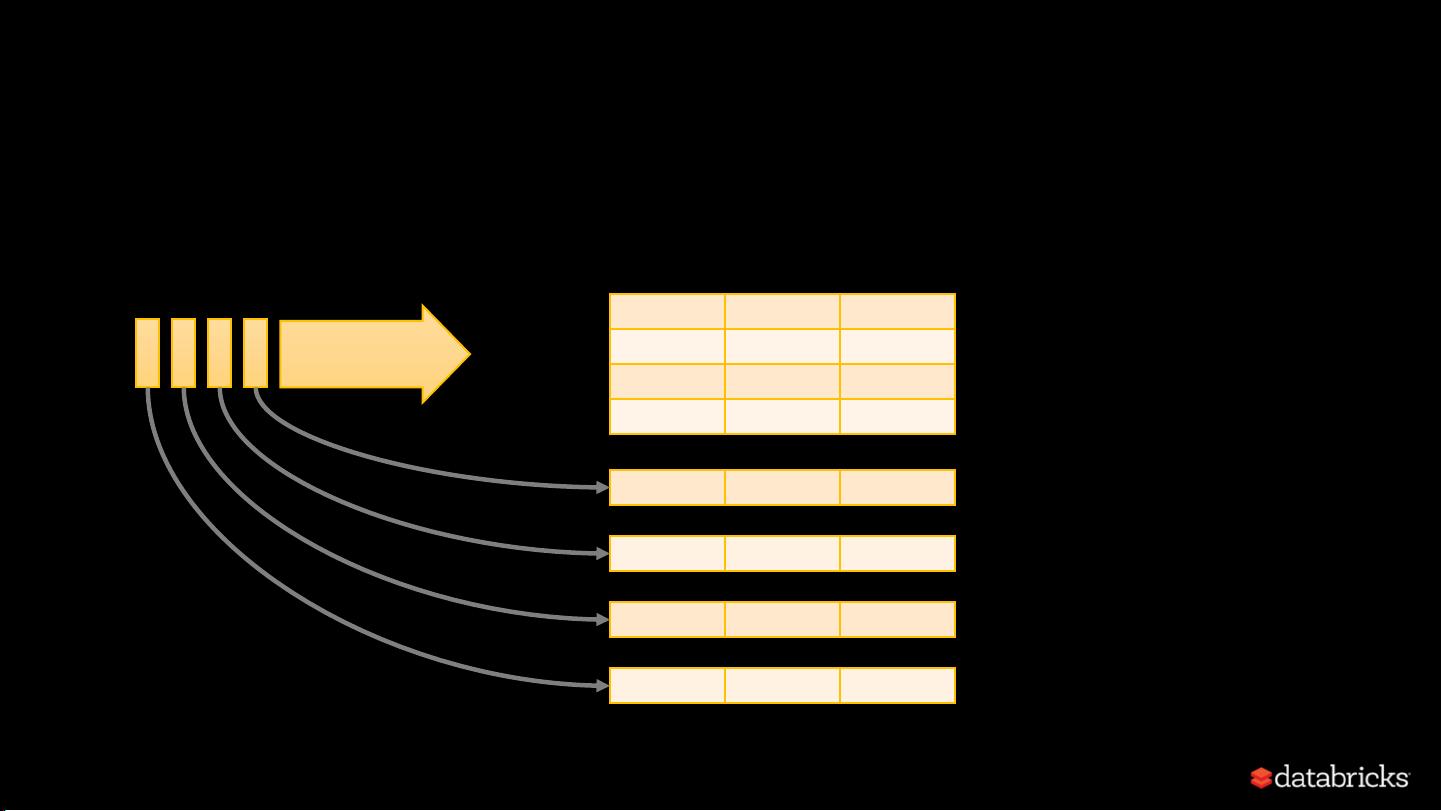
Treat Streams as Unbounded Tables
data stream
unbounded input table
new data in the
data stream
=
new rows appended
to a unbounded table
剩余41页未读,继续阅读
2023-08-30 上传
2023-08-30 上传
2018-10-07 上传
2021-03-31 上传
2018-01-31 上传
2018-01-26 上传
2021-04-26 上传
2010-10-11 上传
2021-05-04 上传

过往记忆
- 粉丝: 4376
- 资源: 275
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
