Spark 2.0展望与应用开发:深度解析与实战指导
需积分: 9 23 浏览量
更新于2024-07-20
收藏 18.59MB PDF 举报
"本次演讲由亚马逊AWS首席云计算技术顾问费良宏分享,主要探讨Spark的未来发展及应用开发,特别是Spark 2.0的新特性,如DataFrame、SparkR、StreamingML和Dataset API。此外,还讨论了如何使用Python进行Spark实时数据流和批处理任务的开发。"
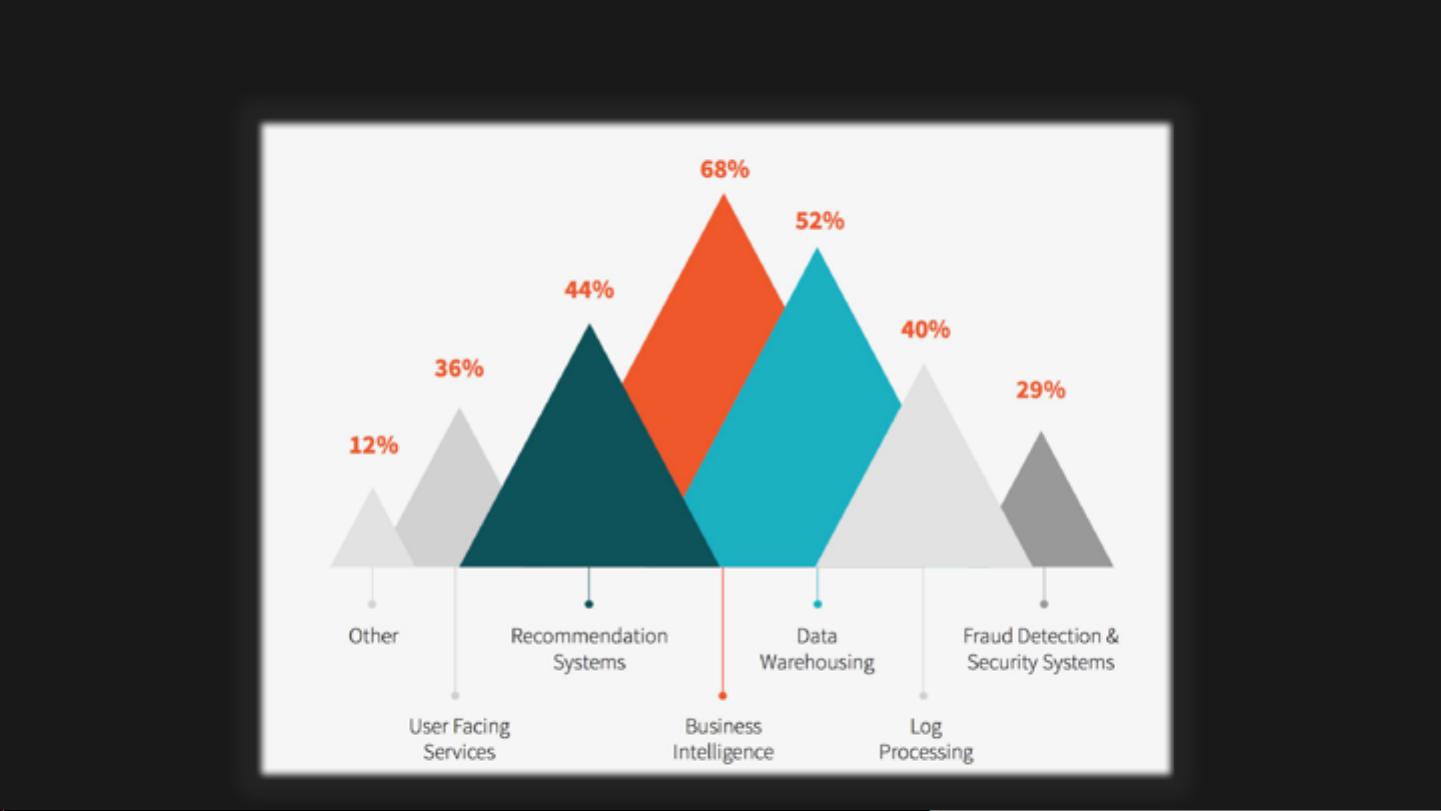
Apache Spark是一个强大的开源大数据处理框架,自2009年诞生以来,因其高效、易用和丰富的功能,已成为大数据市场上的热门选择。Spark的核心设计理念是提供一个统一的引擎来处理各种工作负载,包括批处理、交互式查询、流处理和机器学习,这使得它在MapReduce之上提供了更高的性能和更广的应用范围。
Spark的核心组件包括:
1. **DataFrame**:在Spark 2.0中,DataFrame作为一个高性能且用户友好的数据抽象层,提供了SQL-like的查询能力,同时保持了Spark的分布式计算效率。
2. **SparkR**:SparkR是Spark对R语言的支持,让R用户能够利用Spark的大规模并行计算能力,进行大规模的数据分析。
3. **StreamingML**:这是Spark MLlib库的一部分,专注于流处理中的机器学习算法,使得实时分析和预测成为可能。
4. **Dataset API**: Dataset API结合了DataFrame的易用性和RDD(弹性分布式数据集)的性能,提供了类型安全和编译时检查,提高了开发效率和代码质量。
Spark的理论基础源于两篇关键论文,这两篇论文阐述了Spark的设计理念,即通过工作集(working sets)实现集群计算,并提出了Resilient Distributed Datasets (RDDs)的概念,这是一种容错的内存计算抽象。Apache Spark的创始人之一Matei Zaharia后来成为了Databricks的联合创始人和CTO。
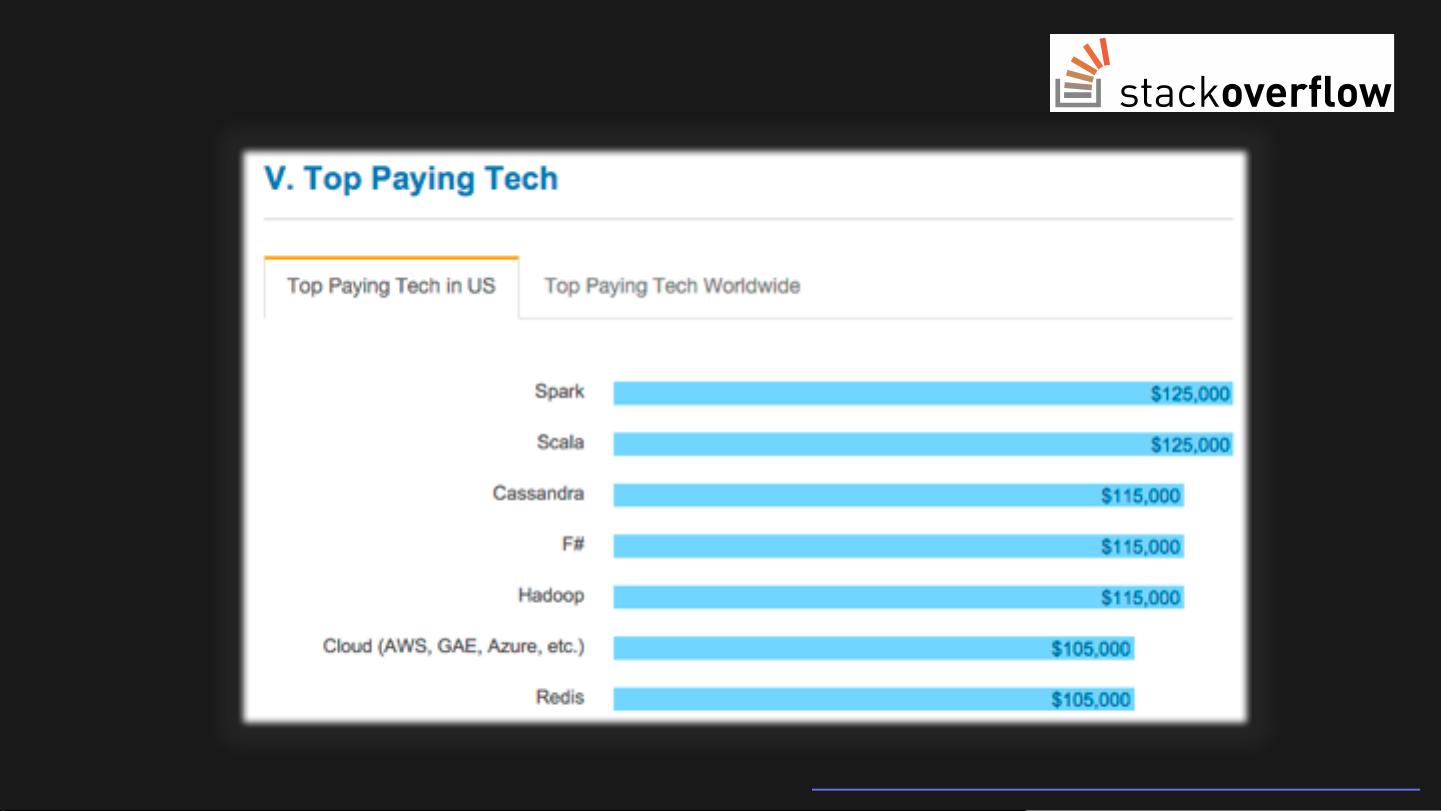
Apache Spark在2015年达到了一个里程碑,成为开源大数据项目中最活跃的一个,吸引了超过1000名代码贡献者,并且开始支持R语言,得到了更广泛产业界的接纳和应用。StackOverflow的年度开发者调查也显示,Spark的受欢迎程度持续增长,成为开发者们越来越关注的技术。
在实际开发中,Python被广泛用于Spark应用程序的编写,因为它具有丰富的库和简洁的语法。通过PySpark,开发者可以构建实时数据流处理和批处理任务,处理数据密集型应用,实现高效的数据分析和处理。
总结起来,Spark的吸引力在于其高度的可扩展性、容错机制、多语言支持以及丰富的标准库。随着Spark 2.0及其新特性的引入,Spark继续巩固其在大数据处理领域的领导地位,为开发者提供了更强大、更灵活的工具来应对不断增长的数据挑战。

点击了解资源详情
点击了解资源详情
点击了解资源详情
2011-11-06 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

jason5186
- 粉丝: 74
- 资源: 42
 我的内容管理
展开
我的内容管理
展开







