Kettle数据增量同步实战指南
需积分: 47 76 浏览量
更新于2024-09-07
收藏 859KB DOC 举报
"kettle数据增量同步实现 - 数据库同步工具Kettle的使用教程,包括创建转换,设置数据源,配置数据对比,流程判断,以及定时任务的生成与执行。"
Kettle,又称Pentaho Data Integration (PDI),是一款强大的ETL(提取、转换、加载)工具,适用于数据仓库的构建和维护。本教程将指导你如何利用Kettle实现数据增量同步,确保在源数据库和目标数据库之间进行高效、准确的数据更新。
首先,你需要下载并安装Kettle。解压缩后,启动Spoon.bat,这将是你的图形化工作台。在这里,你可以创建、编辑和测试转换和作业。
1. **创建转换**:
- 在“单机文件”菜单下选择“新建”> “转换”,这将开启一个新的转换设计界面。
2. **设置数据源和目标数据源**:
- 拖拽“表输入”组件到设计界面,分别命名为“数据源”和“目标数据源”。这些组件用于连接到你的源数据库和目标数据库,并从中读取数据。
3. **配置数据源**:
- 双击每个“表输入”组件,输入相应的数据库连接信息,包括数据库URL、用户名、密码等。
4. **添加数据对比空间**:
- 这是为了比较源数据和目标数据的差异。Kettle提供了多种比较策略,例如基于主键或时间戳。
5. **流程判断**:
- 使用流程判断组件来确定数据是否需要被插入、更新或删除。根据比较结果,配置不同的分支。
6. **处理新增、更新和删除**:
- 对于新增数据,可以使用“插入/更新”步骤将新记录插入目标数据库;对于已存在但需要更新的记录,使用“更新”步骤;而对于需要删除的记录,使用“删除”步骤。
7. **创建定时任务**:
- 在“文件”菜单下选择“新建”> “作业”,创建一个作业来调度你的数据同步转换。使用“Start”步骤开始作业,然后添加“执行转换”步骤,选择你的数据同步转换。
8. **配置定时任务**:
- 根据需求设置定时计划,例如每天、每周或按需运行。
9. **部署与运行**:
- 在Windows上配置好转换和作业后,可以将其移植到Linux环境。使用Kettle的命令行工具`kitchen.sh`执行定时任务,如示例中的命令所示。
这个教程提供了一个基础的Kettle数据增量同步的实现步骤,实际应用中可能需要根据具体的业务需求和数据库结构进行调整。记住,Kettle的强大之处在于它的灵活性和丰富的数据处理组件,你可以根据需要自定义复杂的转换逻辑。在实际操作中,务必确保对源数据库和目标数据库的影响最小,并做好数据备份,以防止意外数据丢失。
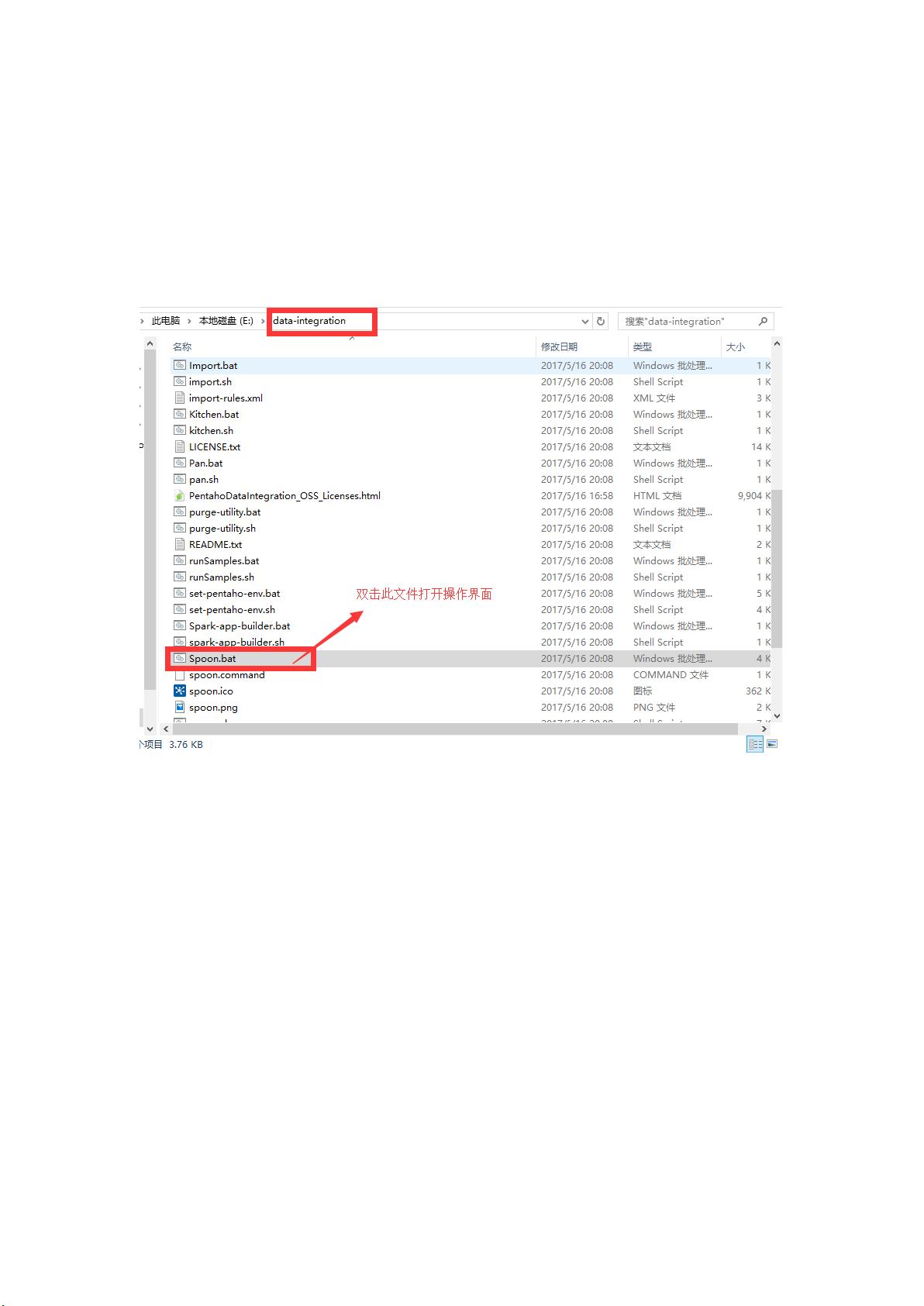
Kele 使用手册
一、。
二、单机文件》新建》转换菜单。
最终生成如下图!
下载后可阅读完整内容,剩余8页未读,立即下载
252 浏览量
356 浏览量
282 浏览量
103 浏览量
116 浏览量
2025-01-08 上传

wyazyf
- 粉丝: 39
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Ember.js用户活跃度跟踪,实现高效交互检测
- 如何在Android中实现Windows风格的TreeView效果
- Android开发:实现自定义标题栏的统一管理
- DataGridView源码实现条件过滤功能
- Angular项目中Cookie同意组件的实现与应用
- React实现仿Twitter点赞动画效果示例
- Exceptionless.UI:Web前端托管与开发支持
- 掌握Ruby 1.9编程技术:全面英文指南
- 提升效率:在32位系统中使用RamDiskPlus创建内存虚拟盘
- 前端AI写作工具:使用AI生成内容的深度体验
- 综合技术源码包:ASP学生信息管理系统
- Node.js基础爬虫教程:入门级代码实践
- Ruby-Vagrant:简化虚拟化开发环境的自动化工具
- 宏利用与工厂模式实践:驱动服务封装技巧
- 韩顺平Linux学习资料包:常用软件及数据库配置
- Anime-Sketch-Colorizer:实现动漫草图自动化上色
