Hadoop伪分布式实验报告:使用WordCount分析维基百科页面
需积分: 0 160 浏览量
更新于2024-08-04
收藏 1.05MB DOCX 举报
"MPLab1-151220129-吴政亿1 实验报告:使用Hadoop伪分布式环境运行WordCount程序分析维基百科页面"
在这个实验中,学生吴政亿按照指导完成了在本地计算机上安装和运行伪分布式Hadoop系统的过程。他首先下载了MapReduce课程的安装操作手册和课件,然后在自己的机器上成功搭建了Hadoop环境。通过执行`jps`命令,他确认了Hadoop服务已经正常启动和运行。同时,他使用`ls`命令检查了Hadoop工作目录,发现包括测试数据集`test-in`,以及两个输出目录`test-out`和`lab1-out`。
实验的第二阶段,吴政亿选择了三个来自维基百科的英文网页作为数据源:闪电侠、神盾局特工和超女的相关页面。他将这些页面的文字部分复制到文本文件中,并去除了HTML标签以准备进行词频统计。这三个网页的URL分别为:
1. https://en.wikipedia.org/wiki/Flash_(comics)
2. https://en.wikipedia.org/wiki/Agents_of_S.H.I.E.L.D.
3. https://en.wikipedia.org/wiki/Supergirl
为了进行实验,吴政亿运行了Hadoop自带的WordCount程序。WordCount是一个经典的MapReduce示例,用于计算文本文件中各个单词出现的次数。在Hadoop的Web作业状态查看界面上,他记录了作业的运行状态,这有助于监控任务的进度和是否成功完成。
实验的输出结果显示了一些最常见的单词及其在输入数据中的出现次数。例如,单词“4,722”出现了两次,单词“Agents”出现了八次,而“S.H.I.E.L.D.”出现了一次。这些结果揭示了输入数据中的主要主题和词汇。
最后,吴政亿的实验报告还包括了他的观察和体会,这部分可能涉及他在安装过程中遇到的问题、解决问题的方法、对Hadoop系统和WordCount程序的理解,以及他对大数据处理和MapReduce模型的实际应用的思考。
这个实验是一个很好的实践案例,它不仅帮助学生熟悉了Hadoop的安装和配置,还让他们亲手体验了MapReduce的工作流程,理解了如何利用Hadoop进行大规模文本数据的分析。通过分析维基百科页面,学生可以直观地看到WordCount程序如何在分布式环境中处理和统计文本数据,进一步加深了对大数据处理技术的理解。
实验内容与要求
1. 每人在自己本地电脑上正确安装和运行伪分布式 Hadoop 系统
安装操作手册和本课程课件请从 MapReduce 课程目录下载。
2. 安装完成后,自己寻找一组英文网页数据,在本机上运行 Hadoop 系统自带的 WordCount 可执
行程序文件,并产生输出结果
3. 实验结果提交:要求书写一个实验报告,其中包括:
(1)系统安装运行的情况
(2)实验数据说明(下载的什么网页数据,多少个 HTML 或 text 文件)
(3)程序运行后在 Hadoop Web 作业状态查看界面上的作业运行状态屏幕拷贝
(4)实验输出结果开头部分的屏幕拷贝
(5)实验体会
实验报告
151220129 计科 吴政亿 nju_wzy@163.com
一、系统安装运行的情况
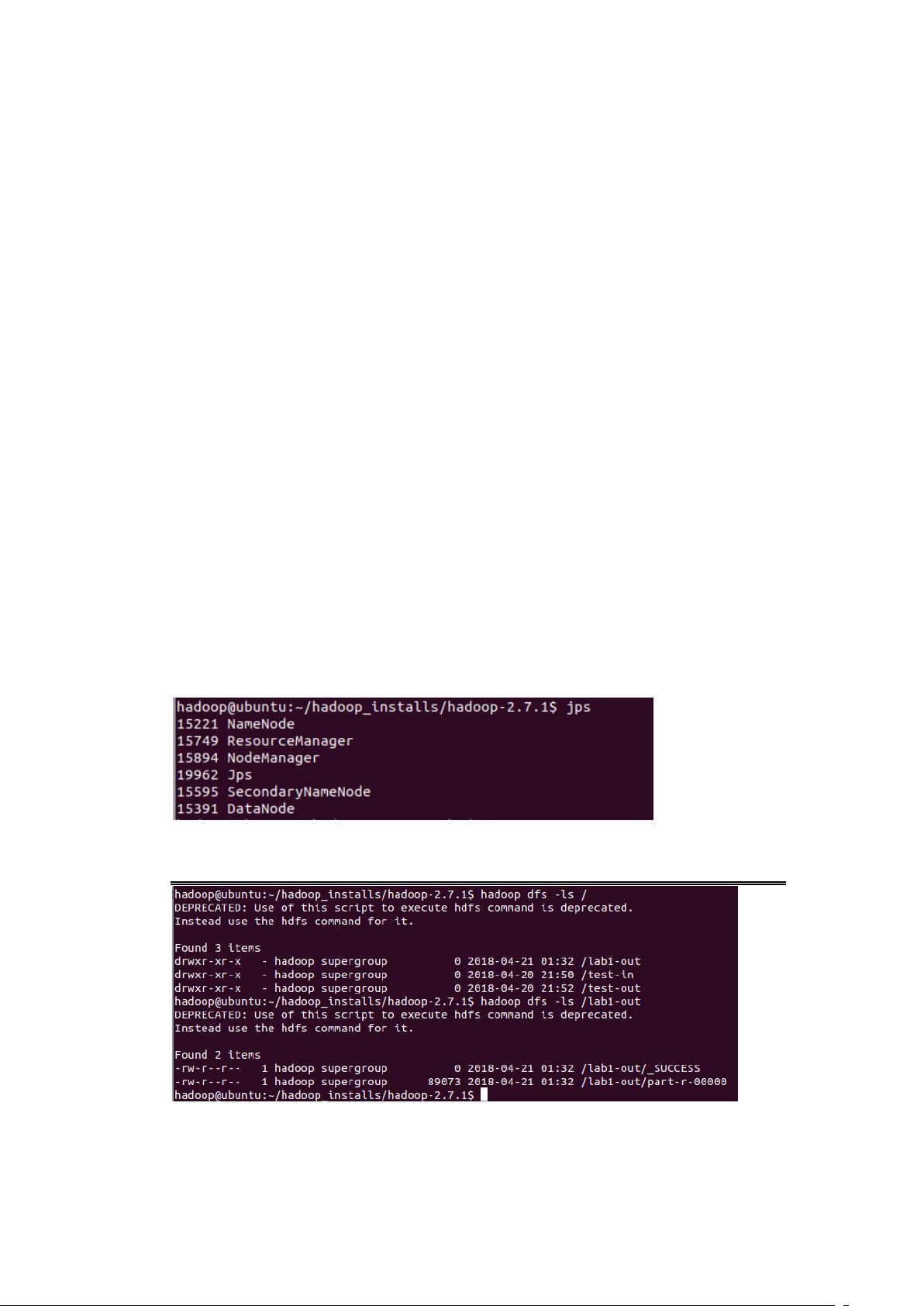
通过 jps 指令得到 hadoop 已正确运行
通过 ls 指令查询,其中 test-in 为我的 test 数据集,test-out 是测试样例输出,lab1-
out 为本次实验输出
下载后可阅读完整内容,剩余5页未读,立即下载
2010-08-16 上传
2023-11-25 上传
2023-07-04 上传
2023-09-27 上传
2023-06-12 上传
2023-10-18 上传
2023-09-07 上传

张博士-体态康复
- 粉丝: 34
- 资源: 307
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
