CentOS下Hadoop集群详细搭建教程
"Hadoop集群搭建涉及Linux操作系统安装、虚拟机配置以及Hadoop环境的准备与配置。本教程提供了一种简明方法,适用于初学者快速上手Hadoop集群的搭建。"
在搭建Hadoop集群的过程中,首先需要安装Linux操作系统,这里推荐使用CentOS。通过VMware Workstation 8.0.0作为虚拟机平台,安装CentOS 6.2的x86_64位版本。部署架构设定为一主两从的模式,即一个Master节点(Hadoopm)和两个Slave节点(Hadoopm和Hadoops)。在虚拟机的创建过程中,应选择自定义安装选项,并指定Linux作为操作系统类型,进一步细化到CentOS的对应版本。
接下来是虚拟机的配置,包括设置虚拟机名称、选择安装位置,以及调整硬件参数如CPU数量(通常设置为至少1个)、内存大小(建议1GB),确保足够运行Hadoop服务。在网络设置上,推荐使用NAT模式,而非桥接模式。NAT模式允许虚拟机共享主机的网络连接,而无需独立的IP地址,适合没有静态IP环境的情况。
在Linux环境中,你需要进行以下基本操作:
1. 更新系统:使用`yum update`命令更新系统软件包。
2. 安装必要的工具:如`vim`编辑器、`wget`下载工具等,用以编辑配置文件和下载Hadoop相关文件。
3. 关闭防火墙和SELinux:`systemctl stop firewalld` 和 `setenforce 0`,以避免网络通信问题。
接下来是Hadoop的安装:
1. 下载Hadoop二进制包,通常是tar.gz格式。
2. 解压Hadoop到指定目录,如 `/usr/local/hadoop`。
3. 配置环境变量:在`~/.bashrc`或`~/.bash_profile`文件中添加Hadoop的路径,并设置HADOOP_HOME。
4. 修改Hadoop配置文件:`core-site.xml`、`hdfs-site.xml`、`mapred-site.xml`和`yarn-site.xml`,配置包括NameNode、DataNode、ResourceManager、NodeManager等相关参数。
5. 初始化NameNode:`hadoop namenode -format`。
6. 启动Hadoop服务:`start-dfs.sh`和`start-yarn.sh`。
在多节点集群中,还需要在每个Slave节点上配置Hadoop环境,并将Master节点作为NameNode和ResourceManager。在Slave节点上执行`jps`命令确认Hadoop守护进程是否正常启动,如DataNode和NodeManager。
为了验证集群是否正常工作,可以尝试执行一个简单的Hadoop MapReduce任务,例如WordCount程序,以此测试数据的读取、处理和写回。
Hadoop集群的搭建涉及多个步骤,包括虚拟机的配置、Linux环境的准备、Hadoop的安装与配置,以及最后的验证。这个过程对于理解和掌握分布式计算及Hadoop生态系统至关重要。在实际操作中,可能会遇到各种问题,需要根据错误提示进行排查,同时熟悉Linux命令行操作和网络配置,这对提升Hadoop技能是非常有帮助的。
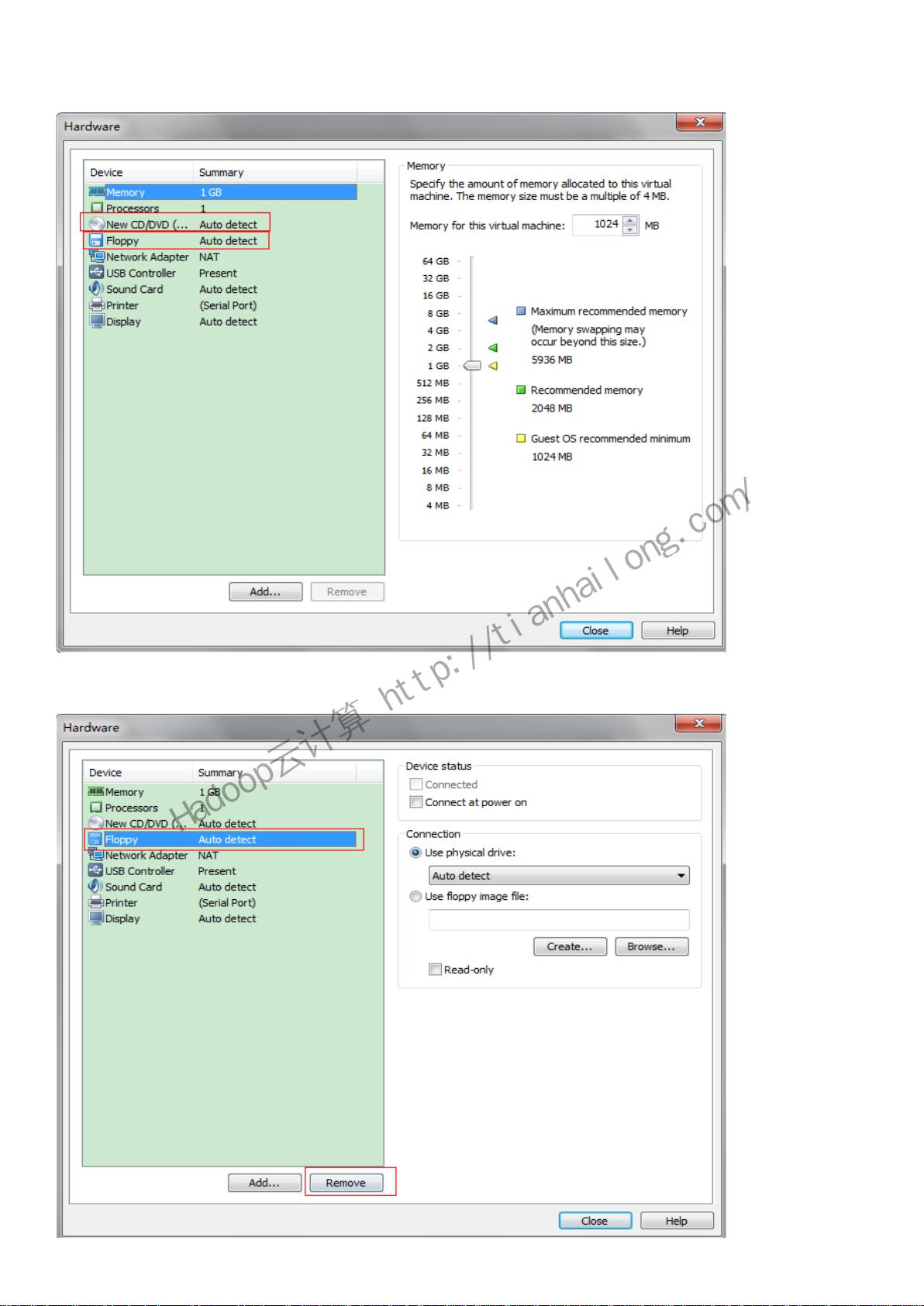
会出现虚拟机硬件清单,我们要修改的,主要关注“光驱”和“软驱”,如下图:
选择“软驱”,点击“remove”移除软驱:
Hadoop云计算
http://tianhailong.com/
9
Hadoop云计算
http://tianhailong.com/
9
Hadoop云计算 http://tianhailong.com/

剩余49页未读,继续阅读
376 浏览量
2022-11-21 上传
135 浏览量
点击了解资源详情
376 浏览量
点击了解资源详情
466 浏览量
点击了解资源详情

kunfeng
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Avogadro:跨平台分子编辑器的开源实力
- 冰点文库下载工具Fish-v327-0221功能介绍
- 如何在Android手机上遍历应用程序并显示详细信息
- 灰色极简风格的html5项目资源包
- ISD1820语音模块详细介绍与电路应用
- ICM-20602 6轴MEMS运动追踪器英文数据手册
- 嵌入式学习必备:Linux公社问答精华
- Fry: Ruby环境管理的简化解决方案
- SimpleAuth:.Net平台的身份验证解决方案和Rest API调用集成
- Linux环境下WTRP MAC层协议的C代码实现分析
- 响应式企业网站模板及多技术项目源码包下载
- Struts2.3.20版发布,迅速获取最新稳定更新
- Swift高性能波纹动画实现与核心组件解析
- Splash:Swift语言的快速、轻量级语法高亮工具
- React Flip Toolkit:实现高效动画和布局转换的新一代库
- 解决Windows系统Office安装错误的i386 FP40EXT文件指南
