StanfordCoreNLP:自然语言处理工具包解析
"StanfordCoreNLP2014.pdf"
StanfordCoreNLP是斯坦福大学开发的一个强大的自然语言处理(NLP)工具包,专注于提供核心的文本分析功能。这个工具集由Christopher D. Manning等人编写,旨在为研究者和实践者提供一个易于使用且可扩展的管道,用于执行各种NLP任务。StanfordCoreNLP被广泛应用于学术界、商业界以及政府机构,其受欢迎程度得益于其简单的设计、直观的接口、稳定高效的分析组件,以及对大量额外依赖的低需求。
工具包的核心功能包括:
1. **分词**:将连续的文本分割成单词或词汇单元,这是大多数NLP任务的基础。
2. **词性标注**:识别每个词的语法角色,如名词、动词、形容词等,有助于理解句子结构。
3. **命名实体识别**(NER):识别文本中的专有名词,如人名、地名、组织名等,这对于信息提取和知识图谱构建至关重要。
4. **句法分析**:分析句子的结构,包括依存关系分析和共指消解,揭示词与词之间的关系。
5. **情感分析**:检测文本中的情绪倾向,可用于评价评论、社交媒体帖子的情感色彩。
6. **核心ference resolution**:识别并解决文本中指代的歧义,如“他”指代的是哪个人物。
7. **文本摘要**:生成文本的简短概述,保留主要信息。
8. **实体链接**:将文本中的实体与知识库中的实体对应起来,增强信息的理解。
StanfordCoreNLP的灵活性在于它允许用户选择需要的组件,构建自定义的处理流程。此外,由于它是用Java编写的,因此可以在多个平台上运行,并且与其他Java应用程序集成方便。同时,它还支持通过XML、JSON等格式进行输入输出,方便与其他系统交互。
为了提高性能,StanfordCoreNLP采用了批处理和流处理两种模式,以适应不同规模的数据。对于大型文本数据,可以使用分布式计算框架,如Hadoop,来加速处理速度。
尽管StanfordCoreNLP在许多NLP任务上表现出色,但它也有局限性,比如对于非英语文本的支持可能不那么完善,而且对于某些特定领域的复杂语言现象可能处理不够理想。然而,随着持续的更新和社区的贡献,这些问题正在逐步得到改善。
StanfordCoreNLP是NLP领域的一个重要工具,为研究人员和开发者提供了强大的基础,使得处理自然语言变得更加便捷高效。无论是学术研究还是实际应用,它都是一个值得信赖的伙伴。
The Stanford CoreNLP Natural Language Processing Toolkit
Christopher D. Manning
Linguistics & Computer Science
Stanford University
manning@stanford.edu
Mihai Surdeanu
SISTA
University of Arizona
msurdeanu@email.arizona.edu
John Bauer
Dept of Computer Science
Stanford University
horatio@stanford.edu
Jenny Finkel
Prismatic Inc.
jrfinkel@gmail.com
Steven J. Bethard
Computer and Information Sciences
U. of Alabama at Birmingham
bethard@cis.uab.edu
David McClosky
IBM Research
dmcclosky@us.ibm.com
Abstract
We describe the design and use of the
Stanford CoreNLP toolkit, an extensible
pipeline that provides core natural lan-
guage analysis. This toolkit is quite widely
used, both in the research NLP community
and also among commercial and govern-
ment users of open source NLP technol-
ogy. We suggest that this follows from
a simple, approachable design, straight-
forward interfaces, the inclusion of ro-
bust and good quality analysis compo-
nents, and not requiring use of a large
amount of associated baggage.
1 Introduction
This paper describe the design and development of
Stanford CoreNLP, a Java (or at least JVM-based)
annotation pipeline framework, which provides
most of the common core natural language pro-
cessing (NLP) steps, from tokenization through to
coreference resolution. We describe the original
design of the system and its strengths (section 2),
simple usage patterns (section 3), the set of pro-
vided annotators and how properties control them
(section 4), and how to add additional annotators
(section 5), before concluding with some higher-
level remarks and additional appendices. While
there are several good natural language analysis
toolkits, Stanford CoreNLP is one of the most
used, and a central theme is trying to identify the
attributes that contributed to its success.
2 Original Design and Development
Our pipeline system was initially designed for in-
ternal use. Previously, when combining multiple
natural language analysis components, each with
their own ad hoc APIs, we had tied them together
with custom glue code. The initial version of the
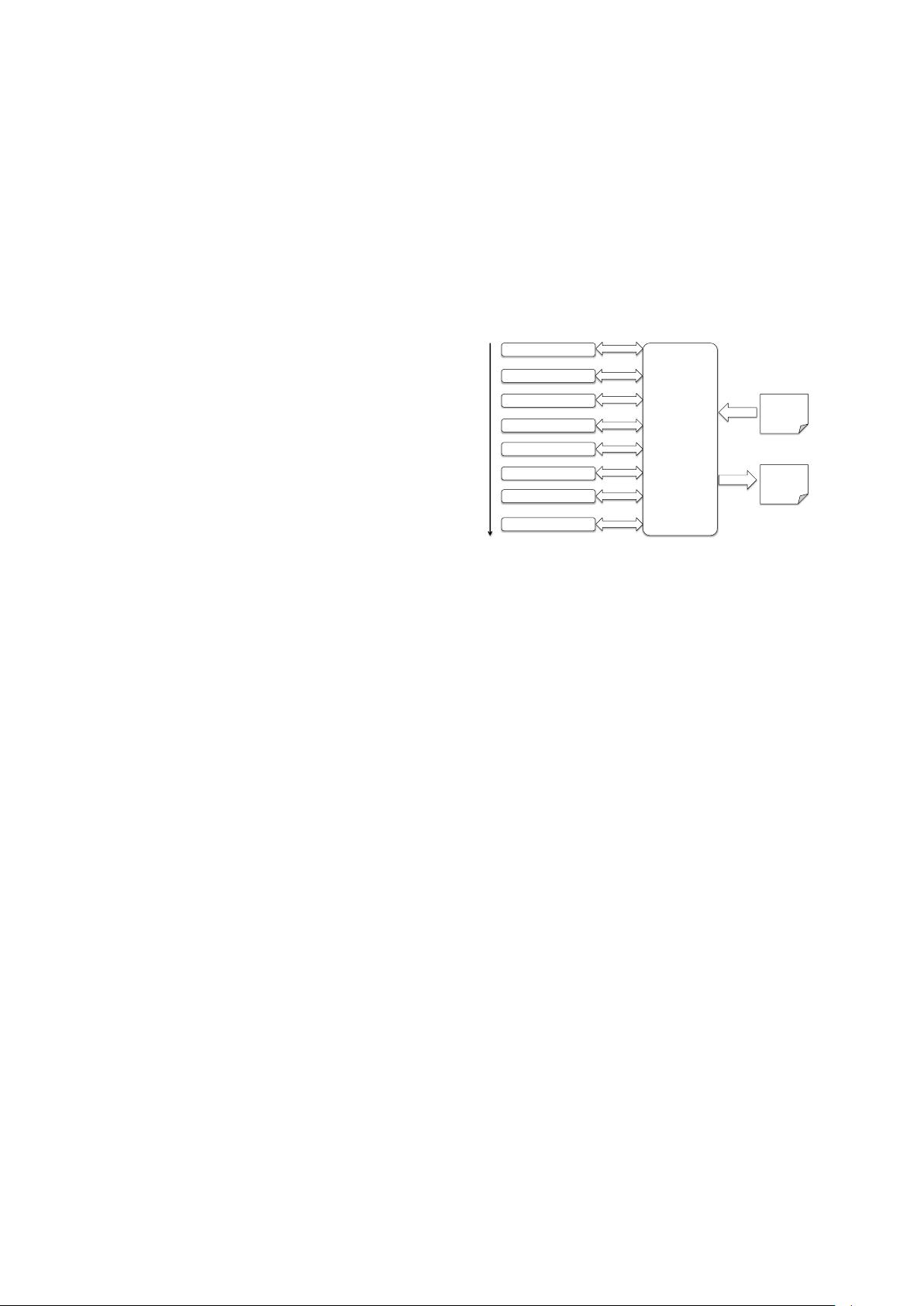
!"#$%&'()"%*
+$%,$%-$*+./&0%1*
2(3,4"546.$$-7*!(11&%1*
8"3.7"/"1&-(/*9%(/:6&6*
;(<$=*>%),:*?$-"1%&)"%*
+:%,(-)-*2(36&%1*
@,7$3*9%%",(,"36*
A"3$5$3$%-$*?$6"/B)"%**
?(C*
,$D,*
>D$-B)"%*E/"C*
9%%",()"%*
@FG$-,*
9%%",(,$=*
,$D,*
HtokenizeI*
HssplitI*
HposI*
HlemmaI*
HnerI*
HparseI*
HdcorefI*
(gender, sentiment)!
Figure 1: Overall system architecture: Raw text
is put into an Annotation object and then a se-
quence of Annotators add information in an analy-
sis pipeline. The resulting Annotation, containing
all the analysis information added by the Annota-
tors, can be output in XML or plain text forms.
annotation pipeline was developed in 2006 in or-
der to replace this jumble with something better.
A uniform interface was provided for an Annota-
tor that adds some kind of analysis information to
some text. An Annotator does this by taking in an
Annotation object to which it can add extra infor-
mation. An Annotation is stored as a typesafe het-
erogeneous map, following the ideas for this data
type presented by Bloch (2008). This basic archi-
tecture has proven quite successful, and is still the
basis of the system described here. It is illustrated
in figure 1. The motivations were:
• To be able to quickly and painlessly get linguis-
tic annotations for a text.
• To hide variations across components behind a
common API.
• To have a minimal conceptual footprint, so the
system is easy to learn.
• To provide a lightweight framework, using plain
Java objects (rather than something of heav-
ier weight, such as XML or UIMA’s Common
Analysis System (CAS) objects).
下载后可阅读完整内容,剩余5页未读,立即下载
2021-02-04 上传
2023-06-13 上传
2021-12-05 上传
2020-12-04 上传
点击了解资源详情
2023-03-16 上传
2023-11-15 上传

Hannah111
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- NIST REFPROP问题反馈与解决方案存储库
- 掌握LeetCode习题的系统开源答案
- ctop:实现汉字按首字母拼音分类排序的PHP工具
- 微信小程序课程学习——投资融资类产品说明
- Matlab犯罪模拟器开发:探索《当蛮力失败》犯罪惩罚模型
- Java网上招聘系统实战项目源码及部署教程
- OneSky APIPHP5库:PHP5.1及以上版本的API集成
- 实时监控MySQL导入进度的bash脚本技巧
- 使用MATLAB开发交流电压脉冲生成控制系统
- ESP32安全OTA更新:原生API与WebSocket加密传输
- Sonic-Sharp: 基于《刺猬索尼克》的开源C#游戏引擎
- Java文章发布系统源码及部署教程
- CQUPT Python课程代码资源完整分享
- 易语言实现获取目录尺寸的Scripting.FileSystemObject对象方法
- Excel宾果卡生成器:自定义和打印多张卡片
- 使用HALCON实现图像二维码自动读取与解码
