FPGA加速卷积神经网络:超详细教程与源码解析
版权申诉
该资源是一个关于使用FPGA加速卷积神经网络(CNN)运算的超详细教程,包含源代码,主要关注卷积核参数的更新方法,并提供了在FPGA上实现加速的具体步骤和性能提升。
在卷积神经网络中,卷积核参数的更新是训练过程的关键部分。在传统的深度学习框架中,如TensorFlow或PyTorch,这些参数通常通过反向传播算法和梯度下降等优化方法进行更新。在FPGA环境下,更新过程可以更加高效,因为FPGA的硬件可编程性允许定制化的并行计算,从而加速卷积操作。
教程首先指出,许多开发者对利用FPGA进行CNN加速感兴趣,作者基于自己的本科毕设经验分享了相关知识。教程展示了采用FPGA加速后的性能提升,例如对于VIPLFaceNet人脸识别算法的7个卷积层,相比4核ARM A53处理器,加速系统实现了45至75倍的运算速度提升。
项目特点包括易于移植,使用Xilinx SDSOC工具,可以直接将C/C++代码转化为FPGA电路,只需要修改与卷积层结构相关的参数即可适应其他CNN模型。此外,项目还应用了多种高性能加速策略:
1. 输入体复用架构:通过复用输入数据,提高计算效率。
2. 数据的低精度转换:降低数据精度,减少计算量,同时保持模型性能。
3. 16通道并行计算单元及加法树结构:利用并行计算提高处理速度。
4. 流水线策略:通过流水线技术,使得各个计算阶段可以重叠执行。
5. 片上存储BRAM的partition及卷积层间共享:有效利用片上存储资源,减少数据传输延迟。
6. 多层卷积的加速实施策略:针对多个卷积层进行优化,进一步提高整体加速效果。
为了进行该项目,开发者需要准备的硬件是Xilinx Ultrascale+ MPSOC ZCU102开发板,软件则包括Ubuntu 16.04操作系统、Xilinx SDSOC 2018.2开发套件以及Xilinx reVISION platform,后者用于支持OpenCV库的xfopencv。
教程的详细内容不仅涵盖了理论知识,还提供了实际操作指南,对于想要利用FPGA优化CNN运算的开发者来说是一份宝贵的资源。通过遵循教程,开发者不仅可以理解卷积核参数更新的基本原理,还能学会如何在FPGA上实现这些更新,以达到显著的计算性能提升。
卷积神经⽹络的卷积核参数如何更新_【超详细教程(附源
码)】如何⽤FPGA加速卷积神经⽹络C。。。
最近发现很多⼩伙伴都想⽤FPGA加速卷积神经⽹络运算,⽽恰好我刚做完的本科毕设就是这个题⽬,所以就有了写这个教程的想法,希望
能给还没开始的⼩伙伴⼀点思路与帮助,更希望⼤神们给出⼀些进⼀步优化的建议。
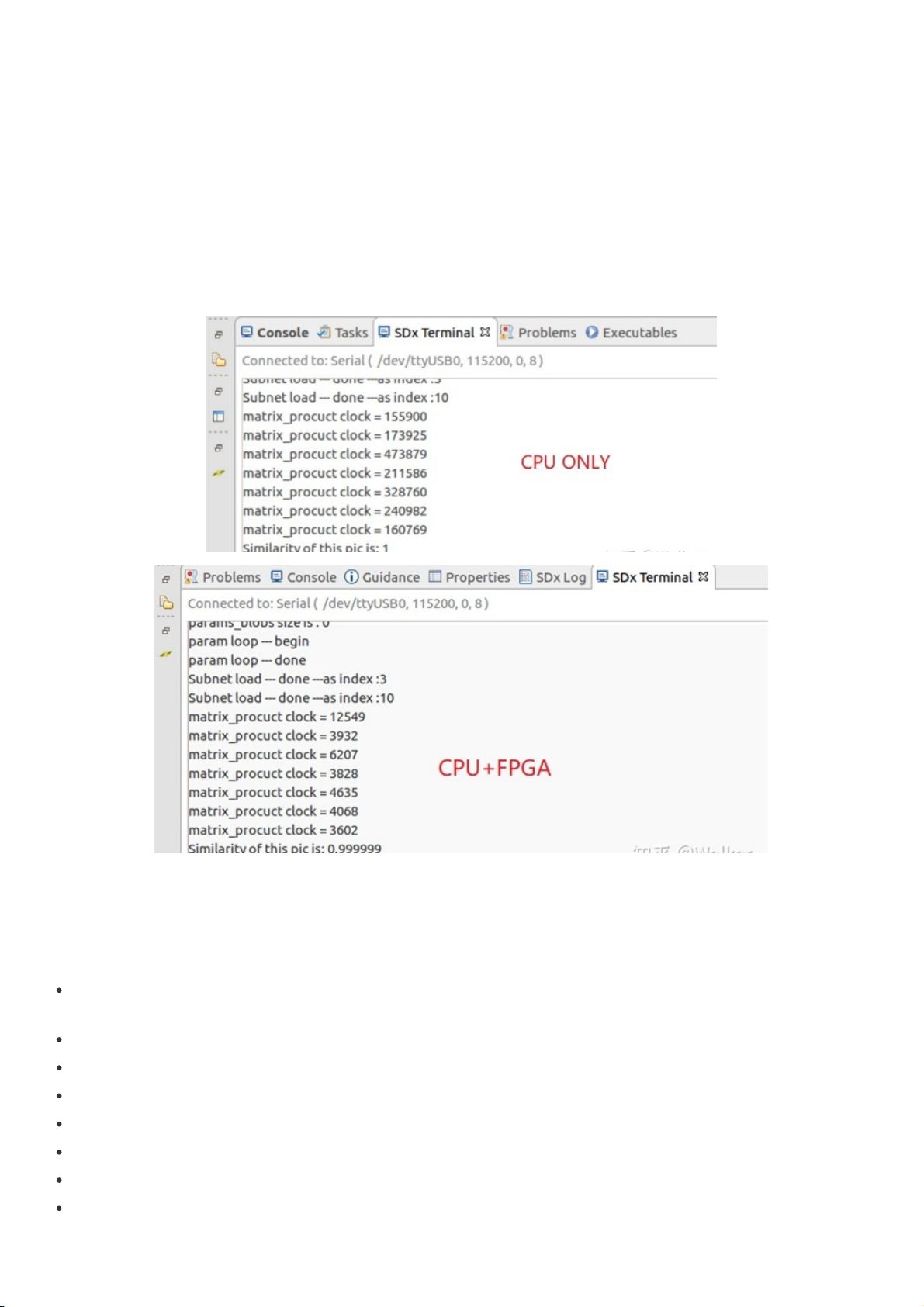
最终加速性能最终加速性能
话不多说,先看最终的加速效果。本加速系统仅加速卷积层的运算,下图展⽰了仅采⽤CPU仅采⽤CPU和采⽤CPU+FPGA加速系统采⽤CPU+FPGA加速系统来处理
VIPLFaceNet⼈脸识别算法时,计算7个卷积层所耗费的时钟数的对⽐。由图可见,相⽐于4核ARM A53处理器,本加速系统最终可以对
VIPLFaceNet的⼤部分卷积层实现45~75倍的运算加速。
项⽬描述及特点项⽬描述及特点
本加速系统采⽤中科院计算所的SeetaFace⼈脸识别项⽬进⾏加速功能的验证,所⽤的卷积神经⽹络模型是VIPLFaceNet。本项⽬的设计
⼯具是Xilinx SDSOC,个⼈认为这是个⼈或⼩团队进⾏FPGA嵌⼊式开发最⾼效的⼯具,因此不会涉及HDL的编写。本加速系统具有以下
特点:
容易移植:本项⽬采⽤Xilinx SDSOC进⾏设计,可以直接把C/C++代码综合成FPGA电路,只需修改FPGA加速模块的代码中卷积层
结构相关的参数就可以移植到别的卷积神经⽹络算法中。
⾼性能,采⽤了如下⼏种加速策略,具体原理见最后⼀节:
独创的输⼊体复⽤架构
数据的低精度转换
16通道并⾏计算单元及加法树结构
流⽔线策略
⽚上存储BRAM的partition及卷积层间共享
多层卷积的加速实施策略
下载后可阅读完整内容,剩余6页未读,立即下载
2024-12-07 上传
159 浏览量
362 浏览量
113 浏览量
2024-12-03 上传
182 浏览量
182 浏览量
173 浏览量
2024-05-12 上传

_webkit
- 粉丝: 31
 我的内容管理
展开
我的内容管理
展开







最新资源
- 昆仑通态MCGS嵌入版_XMTJ温度巡检仪软件包解压教程
- MultiBaC:掌握单次与多次组批处理校正技术
- 俄罗斯方块C/C++源代码及开发环境文件分享
- 打造Android跳动频谱显示应用
- VC++实现图片处理的小波变换方法
- 商城产品图片放大镜效果的实现与用户体验提升
- 全新发布:jQuery EasyUI 1.5.5中文API及开发工具包
- MATLAB卡尔曼滤波运动目标检测源代码及数据集
- DoxiePHP:一个PHP开发者的辅助工具
- 200mW 6MHz小功率调幅发射机设计与仿真
- SSD7课程练习10答案解析
- 机器人原理的MATLAB仿真实现
- Chromium 80.0.3958.0版本发布,Chrome工程版新功能体验
- Python实现的贵金属追踪工具Goldbug介绍
- Silverlight开源文件上传工具应用与介绍
- 简化瀑布流组件实现与应用示例
