




监督学习与无监督学习:深度学习解析及去噪自编码器
需积分: 0 161 浏览量
更新于2024-08-03
收藏 1.54MB DOCX 举报
"assignment16 51215901019梁天一1"
本文主要讨论了机器学习的基础概念,特别是有监督学习和无监督学习的区别,以及深度学习的相关知识,包括损失函数、过拟合和欠拟合的定义,深度学习的基本步骤,以及图像去噪中的编码器技术。同时,还提到了一些拓展性的网络模型和去噪新方法。
一、机器学习基础
有监督学习是基于已有的输入-输出数据对(x和y)来训练模型,目标是使预测输出y_hat尽可能接近真实值y。这种学习方式常用于分类和回归问题。
无监督学习则不同,它处理的数据没有预知的输出标签。算法需要自己发现数据中的结构和模式,如聚类(Clustering)是无监督学习的一个典型应用。
二、损失函数
损失函数是评估模型预测效果好坏的标准,它衡量模型预测与真实结果之间的差距。在训练神经网络时,我们会优化损失函数以提高模型的性能。
三、模型拟合问题
过拟合是指模型在训练数据上表现优异,但在未见过的数据上表现糟糕,这通常是因为模型过于复杂,过度学习了训练数据的噪声。欠拟合则是模型无法捕捉到数据的复杂性,导致训练数据和未知数据上的表现都不理想。
四、深度学习步骤
1. 定义一组函数:构建神经网络结构,定义模型的前向传播过程。
2. 模型和数据拟合:通过反向传播和优化算法(如梯度下降)调整模型参数,使其尽可能地拟合数据。
3. 选择最优函数:在验证集上比较不同模型或超参数设置,选择性能最佳的模型。
五、图像去噪编码器
去噪自编码器(Denoising AutoEncoder, DAE)是用于图像去噪的一种特殊自编码器,它通过在输入中引入随机噪声,训练模型学习恢复原始无噪声输入的能力。合同自编码器(Contractive AutoEncoder)则通过正则化手段增强模型的鲁棒性。
六、拓展作业
1. 常见网络模型如VGG(Visual Geometry Group)网络,以其深度和重复的卷积层结构著称,用于图像识别和分类。
2. 文献“Restormer: Efficient Transformer for High-Resolution Image Restoration”探讨了如何利用Transformer架构进行高分辨率图像修复,展示了Transformer在图像处理领域的潜力,尤其是在CNN的基础上提升性能。
本资源涵盖了机器学习的基础概念,深度学习的核心要素,以及图像处理领域的最新进展。无论是对于初学者还是深入研究者,这些都是理解现代AI技术不可或缺的知识点。
一、基础作业
1. 什么是有监督学习,什么是无监督学习
有监督学习:利用一组已知输入 x 和输出 y 的数据对模型进行学习,在学习过程中尽量 使输
出标记 y_hat 和真实标记 y 相接近
无监督学习:是用来学习的数据不包含输出目标,需要学习算法自动学习到一些有价 值的信
息。一个典型的无监督学习问题就是聚类(Clustering)
2. 什么是损失函数
在训练神经网络之前,需要定义一个标准,来衡量网络的性能(质量)是否达到要求
3. 什么是过拟合,什么是欠拟合
过拟合: 在训练数据上表现良好,在未知数据上表现差
欠拟合: 在训练数据和未知数据上表现都很差
4. 深度学习的三个步骤是什么?
定义一组函数
模型和数据拟合
选择最优函数
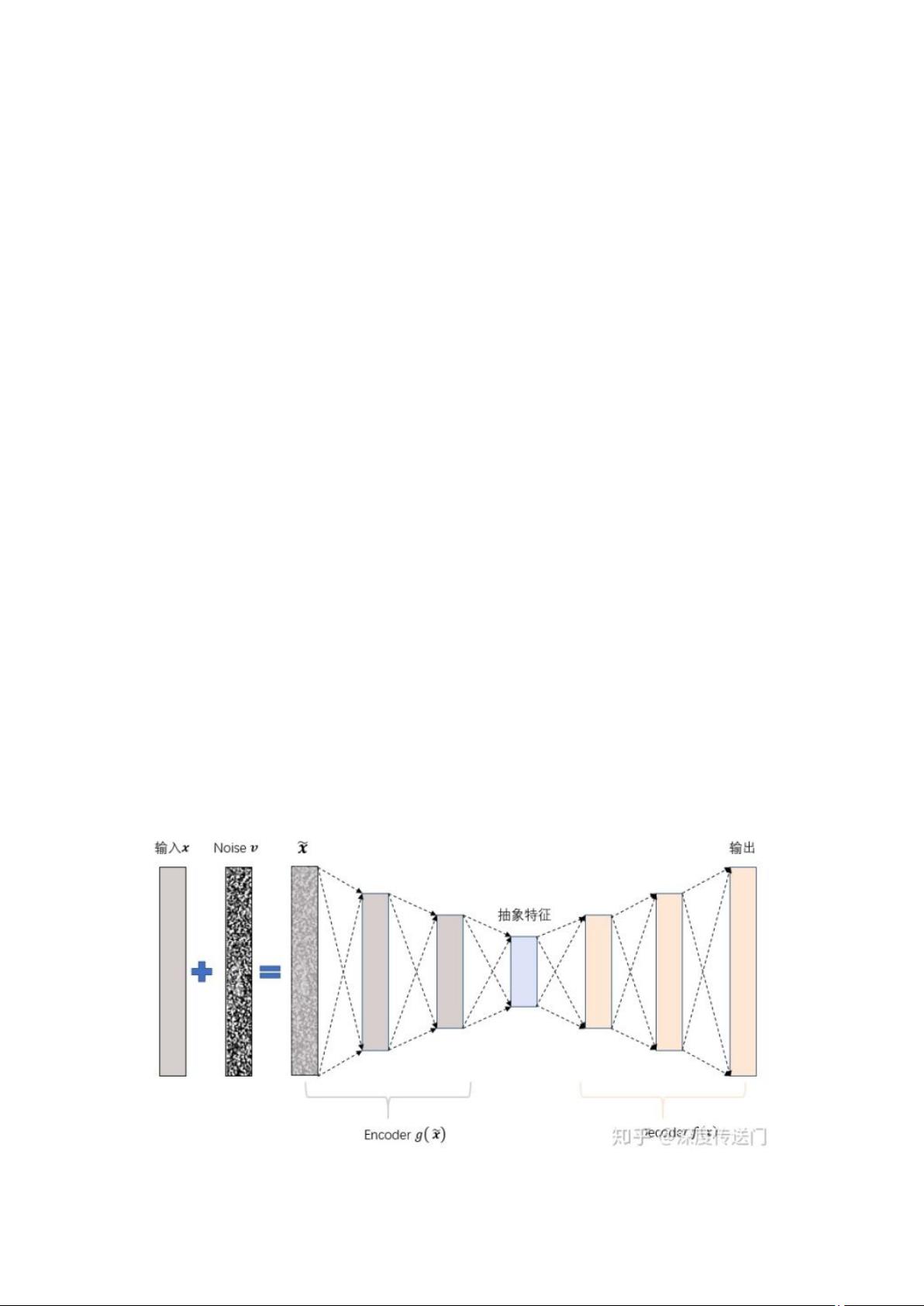
5. 有哪些常见的编码器,可以用于图像去噪?
去噪自编码器
为了缓解经典 AutoEncoder 容易过拟合的问题,一个办法是在输入中加入随机噪声;Vincent
等人[3]提出了 Denoising AutoEncoder,在传统 AutoEncoder 输入层加入随机噪声来增强模型
的鲁棒性。另一个办法就是结合正则化思想,Rifai 等人[4]提出了 Contractive AutoEncoder,
通过在 AutoEncoder 目标函数中加上 encoder 的 Jacobian 矩阵范式来约束使得 encoder 能够
学到具有抗干扰的抽象特征。
下图是 Denoising AutoEncoder 的模型框架。目前添加噪声的方式大多分为两种:添加服从特
定分布的随机噪声;随机将输入 x 中特定比例置为 0。有没有觉得第二种方法跟现在广泛石
红的 Dropout 很相似,但是 Dropout 方法是 Hinton 等人在 2012 年才提出来的,而第二种加
噪声的方法在 08 年就已经被应用了。
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
104 浏览量
点击了解资源详情
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传

申增浩
- 粉丝: 691
 我的内容管理
展开
我的内容管理
展开







最新资源
- Go语言开发的网络流量查看工具
- 圣诞节海报PSD模板下载
- SpringBoot任务管理实战教程与源码解析
- 深入Java源码:新零售系统实战解析
- 全面记录跟踪:条码进销存系统v3.1优化采购与管理
- 离线在线预算追踪器:JavaScript实现的高效财务管理
- Go语言开发工具:高效管理多个Git仓库
- 使用HTML5 canvas制作的JavaScript贪吃蛇游戏
- Java开发者必备:JettBrain-Hyperskill实战指南
- 使用ecole-directe-api进行课程任务管理
- 《中国营销难题解决大纲》:提升营销管理与经营绩效
- 掌握Android动画制作与Java游戏开发实战
- 第2章ARM体系结构的嵌入式系统设计要点
- 宠物医院专业网站模板发布
- Heroku Buildpack for Sp语言的开发与部署
- 自动更新DNS记录的JavaScript项目指南





















