"基于Scrapy的分布式网络爬虫系统实现及技术概述"
需积分: 0 132 浏览量
更新于2024-02-01
收藏 1.52MB PDF 举报
网络爬虫技术是一种自动化获取和提取网页信息的技术,可以用于数据挖掘、信息处理和存储历史数据等一系列任务。本文简要介绍了一个基于Scrapy、Redis和Scrapyd的分布式网络爬虫系统,该系统实现了从智联招聘、智联卓聘、Boss直聘和51招聘等网站上爬取职位招聘信息,并将数据存入MongoDB数据库。
Scrapy是一个用于爬取网站数据、提取结构化数据的应用框架。最初设计用于页面抓取,也适用于获取API返回的数据或通用的网络爬虫。Scrapy使用Twisted异步网络库来处理网络通讯。整体架构包括Scrapy Engine引擎、Scheduler调度器、Downloader下载器、Spider爬虫、Item Pipeline数据管道和Middleware中间件等组件。
在这个分布式网络爬虫系统中,引擎从Spider中获取第一个要爬取的URL,并通过调度器获取下一个要爬取的URL。调度器返回下一个URL后,引擎再次向调度器请求下一个URL,并循环执行爬取任务。每个Spider负责解析页面,提取所需的数据,并将数据传递给Item Pipeline进行处理和存储。
该网络爬虫系统通过Redis实现分布式任务调度和管理。Redis是一个开源的高性能键值对存储数据库,可以用于缓存、消息队列、任务调度等应用。通过Redis,可以实现多个爬虫节点之间的任务分发和结果交换,提高爬取效率和可扩展性。
在爬取过程中,网络爬虫系统会通过Scrapyd进行部署和管理。Scrapyd是一个用于部署Scrapy项目的工具,可以实现项目的远程部署和管理,方便进行任务调度和监控。
爬取的职位招聘信息包括职位名称、职位链接、公司名称、工作地点、职位发布日期、职位招聘人数、职位类型、公司简介、职位具体信息、公司规模、公司类型、公司行业、公司地址、公司主页、专业要求等相关信息。通过对这些信息的获取和分析,可以为用户提供准确、全面的招聘信息,帮助他们找到合适的工作机会。
最终,爬取的数据会被存储到MongoDB数据库中。MongoDB是一个开源的文档型数据库,适用于存储大量的非结构化数据。通过将爬取的数据存入MongoDB,可以方便地进行数据查询、分析和展示。
总之,该分布式网络爬虫系统基于Scrapy、Redis和Scrapyd实现了从多个网站上爬取职位招聘信息,并将数据存储到MongoDB数据库中。通过高效的任务调度和分布式处理,可以提高爬取效率和可扩展性。该系统可以为用户提供全面、准确的职位招聘信息,帮助他们快速找到合适的工作机会。
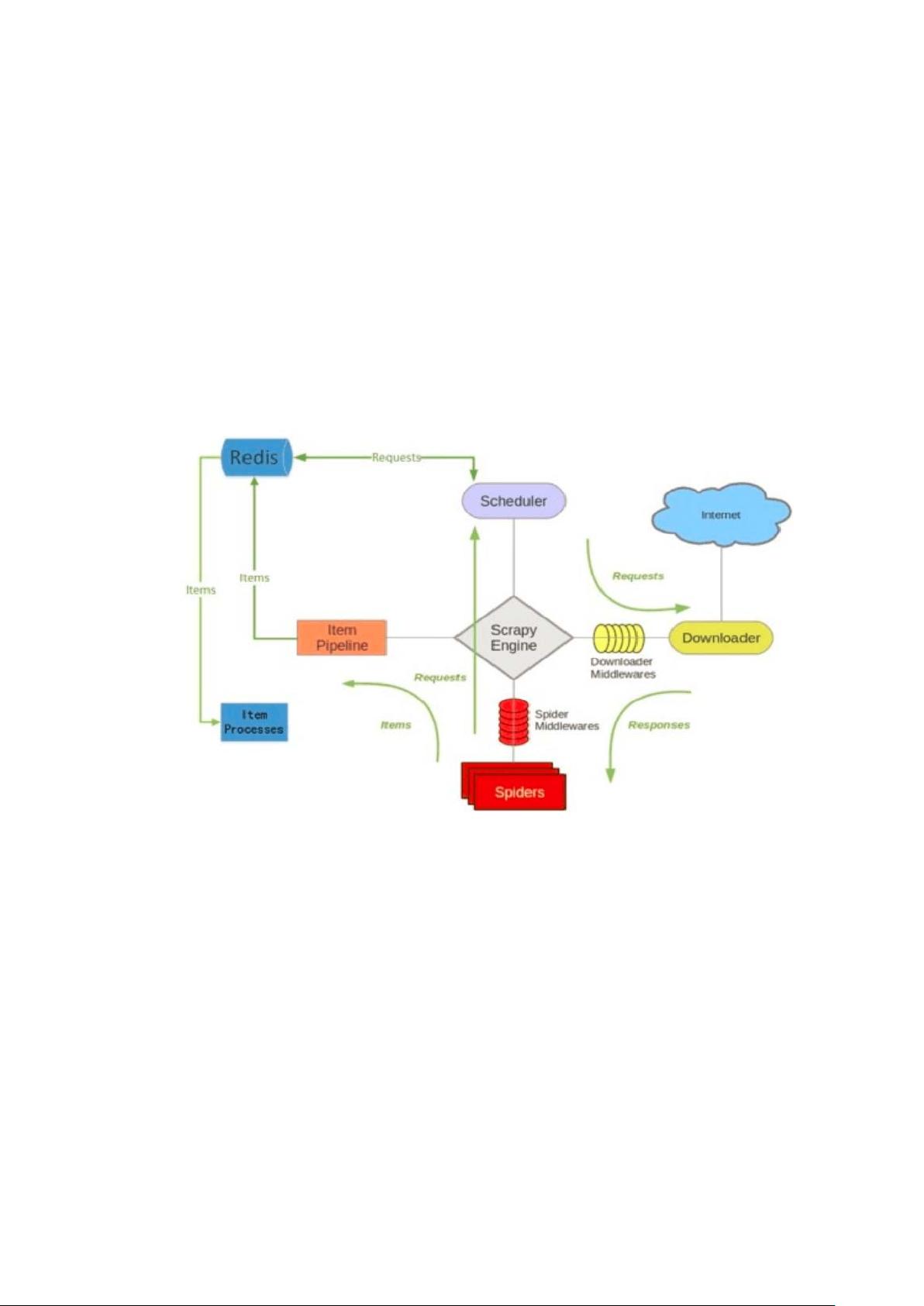
Scrapy-Redis
Scrapy-Redis 则是一个基于 Redis 的 Scrapy 分布式组件。它利用 Redis 对用
于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)
存储以供后续处理使用。scrapy-redi 重写 scrapy 一些比较关键的代码,将 scrapy
变成一个可以在多个主机上同时运行的分布式爬虫。
加上 redis 后,上述 scrapy 的架构就变成下图所示:
组件-connection.py
负责根据 setting 中配置实例化 redis 连接。被 dupefilter 和 scheduler 调用,
总之涉及到 redis 存取的都要使用到这个模块。
connect 文件引入了 redis 模块,这个是 redis-python 库的接口,用于通过
python 访问 redis 数据库,可见,这个文件主要是实现连接 redis 数据库的功能
(返回的是 redis 库的 Redis 对象或者 StrictRedis 对象,这俩都是可以直接用来
剩余27页未读,继续阅读
2022-08-03 上传
2019-05-06 上传
2011-06-22 上传
2017-03-15 上传
2022-06-30 上传
2011-12-21 上传
2014-12-05 上传

chenbtravel
- 粉丝: 29
- 资源: 296
 我的内容管理
展开
我的内容管理
展开







最新资源
- WPF渲染层字符绘制原理探究及源代码解析
- 海康精简版监控软件:iVMS4200Lite版发布
- 自动化脚本在lspci-TV的应用介绍
- Chrome 81版本稳定版及匹配的chromedriver下载
- 深入解析Python推荐引擎与自然语言处理
- MATLAB数学建模算法程序包及案例数据
- Springboot人力资源管理系统:设计与功能
- STM32F4系列微控制器开发全面参考指南
- Python实现人脸识别的机器学习流程
- 基于STM32F103C8T6的HLW8032电量采集与解析方案
- Node.js高效MySQL驱动程序:mysqljs/mysql特性和配置
- 基于Python和大数据技术的电影推荐系统设计与实现
- 为ripro主题添加Live2D看板娘的后端资源教程
- 2022版PowerToys Everything插件升级,稳定运行无报错
- Map简易斗地主游戏实现方法介绍
- SJTU ICS Lab6 实验报告解析
