



Bruce讲解词向量:从OneHot到Word2Vec与FastText实战
版权申诉
自然语言处理之动手学词向量(word embedding)是一门实用的课程,由Bruce主讲,关注于AI壹号堂公众号分享的知识。课程内容涵盖了基础的One-hot编码概念,这是一种常用的离散特征编码方法,尤其适用于文本数据处理。One-hot编码将每个可能的状态表示为一个独立的二进制特征,例如在性别分类中,1代表男,2代表女,对应特征向量中仅一个位为1,其余为0。
在课程中,首先介绍了One-hot编码的工作原理,通过举例说明了如何为特征分配不同的状态位。这种编码方法简单直观,但在处理大量状态或稀疏数据时效率较低,因为它会生成大量的维度,导致维度灾难( Curse of Dimensionality)。
接着,课程转向了更先进的词向量表示方法,如Word2vec。Word2vec是一种流行的词嵌入技术,包括连续词袋模型(CBOW)和Skip-Gram模型,它们能捕捉词汇之间的上下文关系,生成低维稠密向量,解决了One-hot编码的维度问题。课程还会涉及Word2vec的具体实现方式和训练过程,包括神经网络模型的构建以及优化算法的应用。
除了Word2vec,课程还探讨了FastText,它是在Word2vec基础上的一个改进,不仅考虑词的中心词,还能捕捉到词内部的子词信息,提高了文本分类和表示的效率。GloVe(Global Vectors for Word Representation)则是另一种独特的词向量表示方法,它结合全局统计和局部上下文信息,生成的词向量具有更好的语义表达能力。
本课程从基础的One-hot编码出发,深入浅出地介绍了词向量在自然语言处理中的重要性,以及如何通过Word2vec、FastText和GloVe等技术来有效地学习和表示词汇,为理解和应用自然语言处理提供扎实的理论基础和实践经验。通过本课程的学习,学员将能够提升文本处理的精度和效率,为后续的NLP任务打下坚实基础。
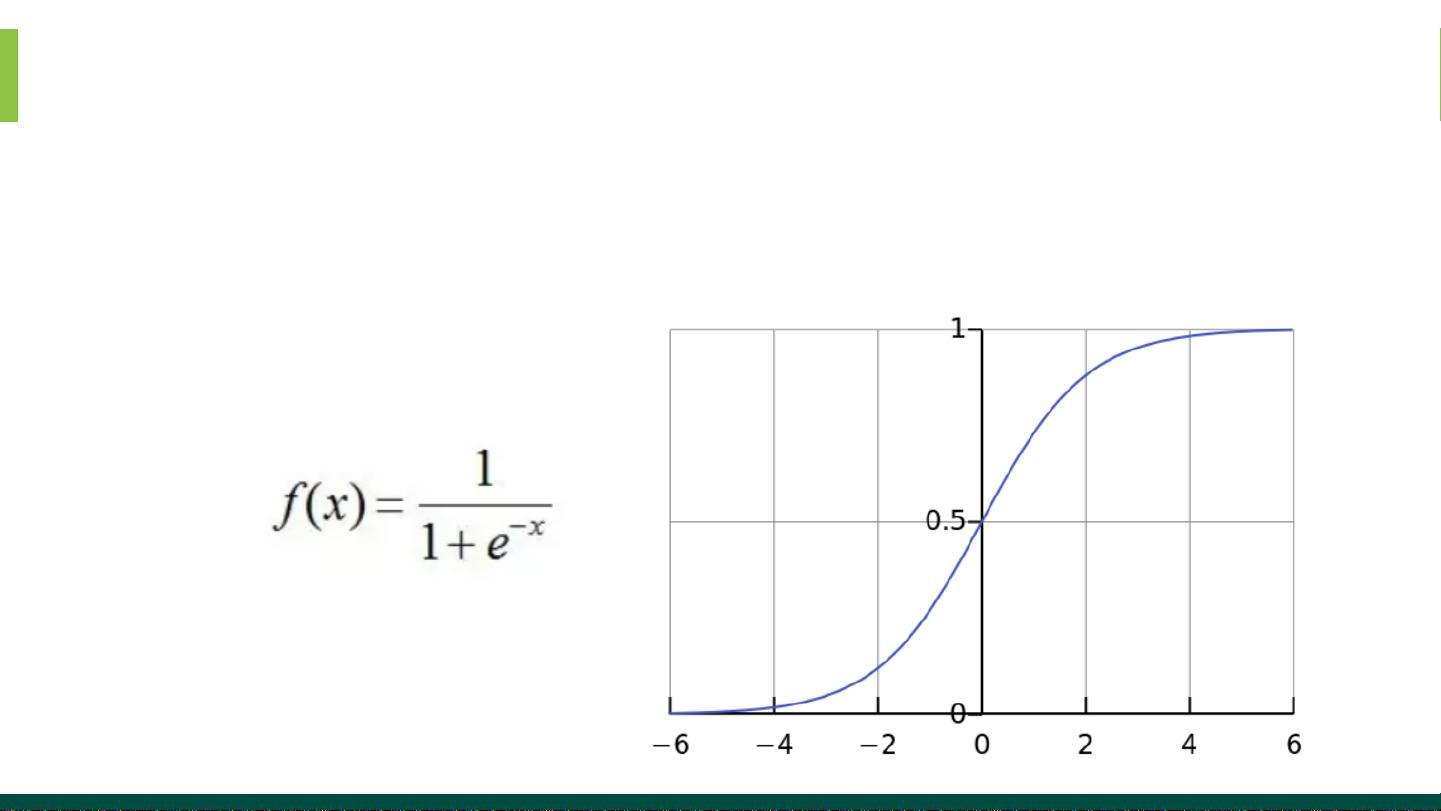
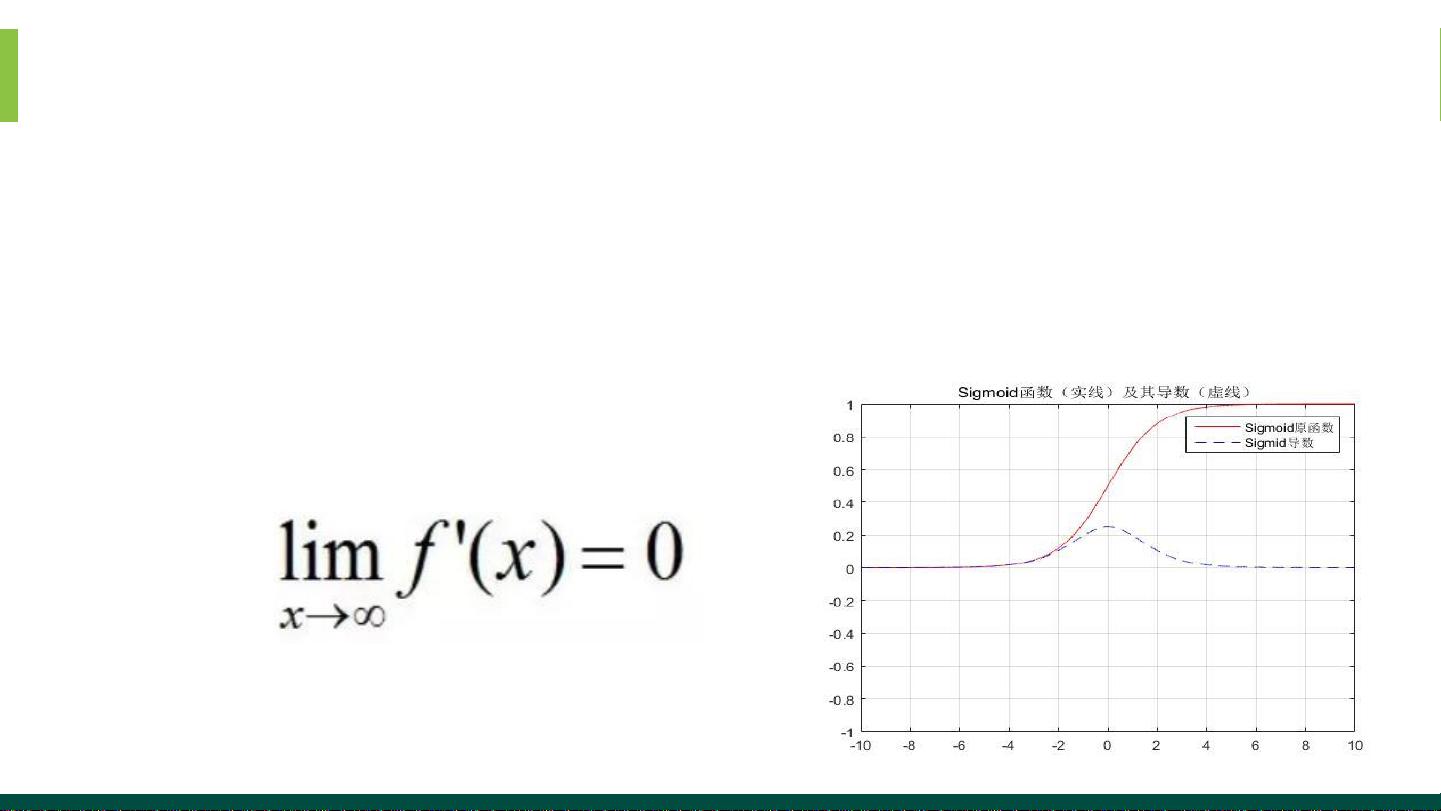
Sigmoid
Sigmoid是什么?
sigmoid函数也叫 Logistic 函数,用于隐层神经元输出,取值范围
为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分
类。

剩余100页未读,继续阅读
3248 浏览量
590 浏览量
104 浏览量
2021-09-14 上传
2024-04-28 上传
855 浏览量
243 浏览量

passionSnail
- 粉丝: 470
 我的内容管理
展开
我的内容管理
展开







最新资源
- Delphi7.0构建的图书销售管理系统设计
- 51单片机C语言入门:使用KEIL uVISION2开发
- 掌握XML:实用教程与核心技术
- C# Programming Fundamentals and Applications
- LoadRunner入门:实战测Tomcat表单性能与脚本录制
- 松下KX-FLB753CN一体传真机中文说明书:安全与操作指南
- Java语言入门学习笔记
- 哈工大线性系统理论硕士课程大纲
- DS18B20:一线总线数字温度传感器详解
- 数据库表设计实战指南:主键选择与规范化策略
- Protel DXP中文版入门教程:构建原理图与PCB设计
- 正则表达式完全指南:常见模式与解析
- Linux世界驰骋系列教程全集:系统管理与Shell编程
- 软件工程:走进成熟的学科指南(第4版)
- .NET初学者指南:C#基础教程
- Oracle常用函数详解:从ASCII到RPAD/LPAD





















