KNN手写识别实例与神经网络性能比较
需积分: 9 188 浏览量
更新于2024-08-04
收藏 539KB PDF 举报
本资源是一份名为"21-提交-WS06V03KNN实现手写识别实例编写与神经网络实验对比.pdf"的文档,主要介绍了如何使用K-最近邻(KNN)算法进行手写数字识别,并将其结果与多层感知机(Multilayer Perceptron,MLP)进行性能对比。该文档针对的是一个常见的机器学习任务,即多分类问题,目标是识别10个手写数字类别(0-9),通过sklearn库实现。
文档首先阐述了任务背景,指出手写数字识别的挑战在于处理大量的训练数据,并且KNN作为一种懒散学习方法,不涉及复杂的模型训练,仅在预测阶段通过寻找最相似的数据点进行分类。文档详细地指导读者如何操作:
1. **工程建立与sklearn包导入**:
- 创建一个名为sklearnKNN.py的文件,并在此文件中导入必要的sklearn模块,以便进行后续数据处理和模型构建。
2. **加载训练数据**:
- 定义了img2vector函数,将32x32的图片矩阵展平成1024维向量。
- readDataSet函数用于加载数据集DBRHD,将图片存储在train_dataSet中,标签存于train_hwLabels中。
3. **构建KNN分类器**:
- 设置查找算法(通常为欧几里得距离或余弦相似度)及邻居点的数量k(这里尝试了1、3、5、7不同的k值)。
- KNN分类器的构建包括调用fit函数,这个过程是无参数训练,依赖于训练数据。
4. **测试集评价**:
- 加载测试数据,并使用已构建的KNN模型进行预测。
- 分析不同k值下的性能,结果显示K=3时的正确率最高,随着k值增加,正确率逐渐降低,表明过度拟合或欠拟合问题可能开始显现。
这份文档不仅提供了KNN在手写识别任务中的应用实例,还展示了如何通过改变超参数(如k值)来优化模型性能,以及与传统神经网络模型(如MLP)的潜在比较。这对于理解KNN算法的基本原理、实践应用以及优化策略具有实际价值。
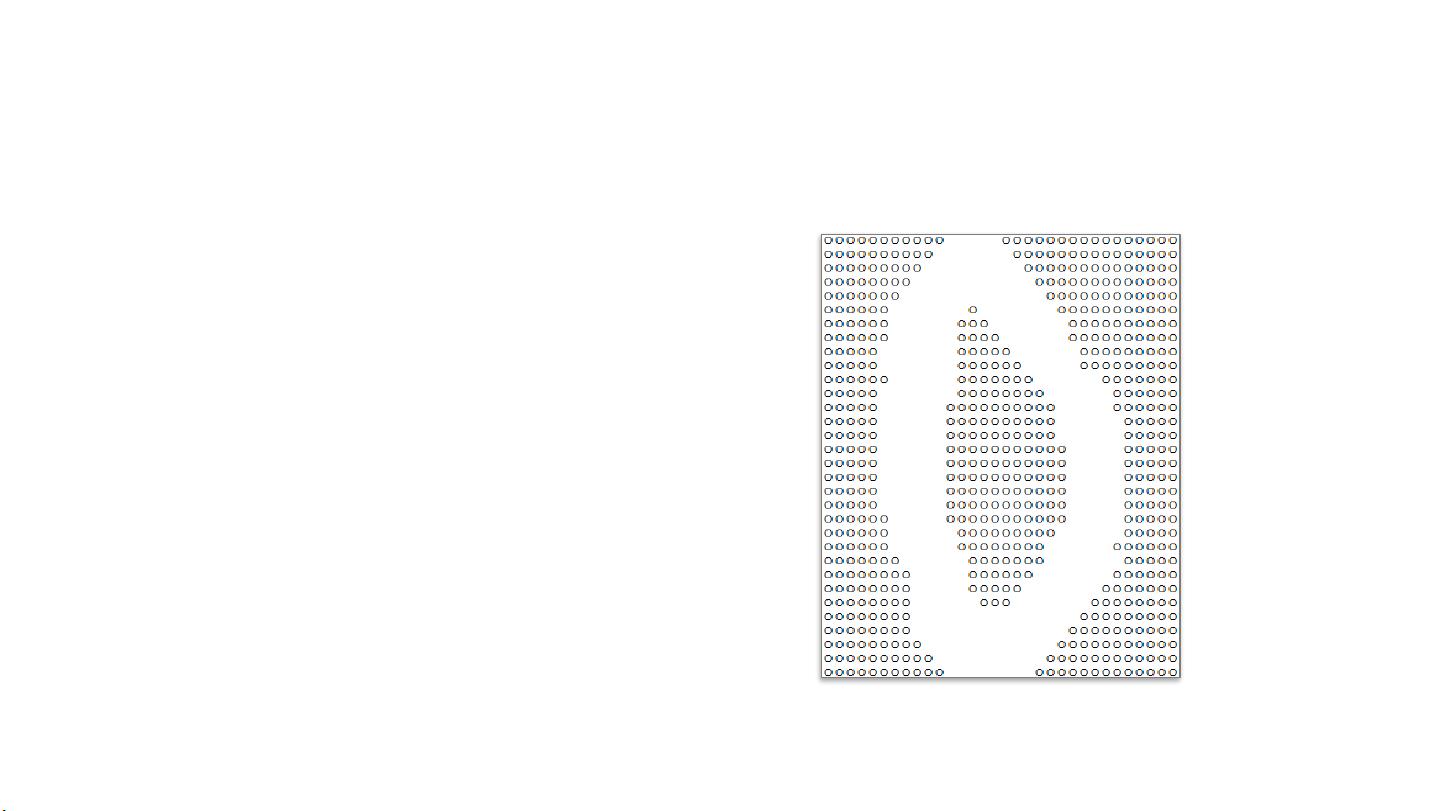
KNN的输入
DBRHD数据集的每个图片是一个由0
或1组成的32*32的文本矩阵。
KNN的输入为图片矩阵展开的一个
1024维的向量。
剩余12页未读,继续阅读
2019-05-18 上传
2016-03-23 上传
2023-04-17 上传
2019-07-27 上传
2021-10-14 上传
2019-06-09 上传
2023-04-17 上传
2022-05-18 上传

「已注销」
- 粉丝: 0
- 资源: 23
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
