利用开源软件打造Hadoop大数据管道的实践指南
需积分: 9 132 浏览量
更新于2024-07-26
收藏 8.47MB PPT 举报
在当今大数据时代,Hadoop作为一个强大的分布式计算框架,对于处理海量数据起着关键作用。如何使用开源软件构建高效的大数据管道是许多企业和开发者关注的重点。本文由Dr. Mark Pollack撰写,主要围绕如何利用开源工具,如Spring Data,来构建与Hadoop集成的数据处理管道。
首先,"big data"的概念指的是那些超出传统数据库软件能力范围,大小从数百TB到PB级的海量数据集。这是一个不断发展的领域,涵盖了众多行业,包括电子商务、金融等,其中价值远超硬件和软件成本。例如,通过对用户代理进行分组, Orbitz可以为Mac用户推荐更昂贵的酒店服务,这体现了数据连接的价值。
Spring框架一直以来都以其出色的数据库访问支持而闻名。它提供了全面的功能,如事务管理、可移植的数据访问异常处理机制、JDBC和JdbcTemplate接口、以及ORM框架的支持,如Hibernate、JPA、JDO和iBatis。此外,Spring 3.1版本引入了缓存支持,进一步增强了其性能。
Spring Data项目于2010年启动,其目标是基于Spring的现有基础,更新和强化数据访问支持。这主要针对新的数据访问环境,旨在提供一种熟悉的、一致的编程体验,使得开发者能够更加便捷地与Hadoop及其他大数据存储系统交互。
Spring Data的使命声明是提供一个基于Spring的统一编程模型,简化大数据处理流程,让开发者能够轻松地实现数据检索、存储和操作,无需深入了解底层技术细节。通过Spring Data,开发人员可以编写出高可用、易于维护的代码,同时充分利用Hadoop的分布式计算能力,构建稳定且高效的大数据管道。
构建大数据管道时,使用Spring Data这样的开源工具与Hadoop集成,不仅可以降低复杂性,还能提高开发效率和数据处理能力。开发者需要掌握如何配置和使用Spring Data的各种模块,结合Hadoop的MapReduce或Spark等计算模型,构建能满足企业特定需求的高性能数据处理流程。同时,随着数据规模的持续增长,持续关注Spring Data的最新发展和优化,将有助于保持系统的灵活性和适应性。

•
Spring Data
for manipulating data in relational DBs
as well as a variety of NoSQL databases and data grids
(inside Gemfire 7.0)
•
Spring for Apache Hadoop
for orchestrating Hadoop and non-Hadoop workflows
in conjunction with Batch and Integration processing
(inside GPHD 1.2)
Spring projects offer substantial integration functionality
11
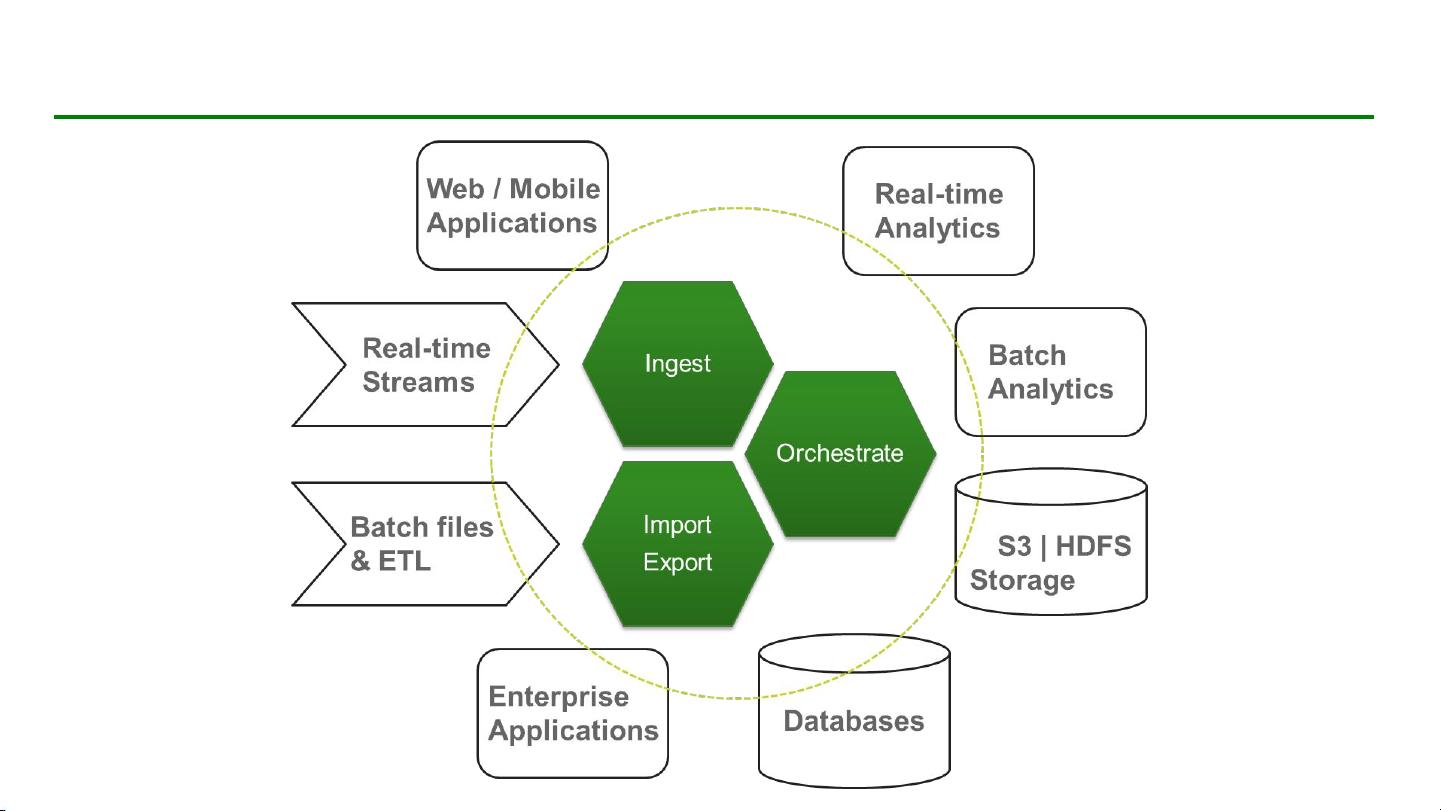
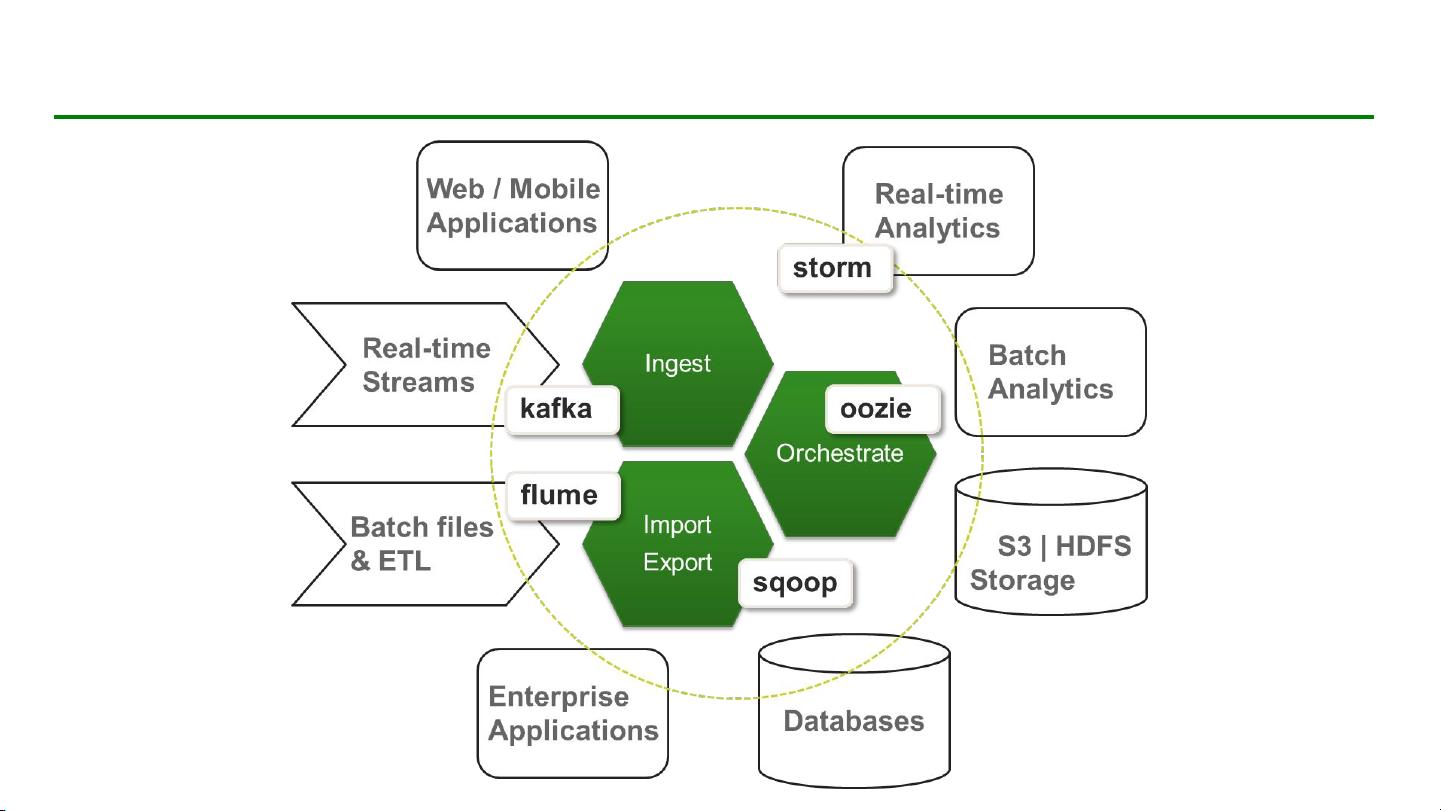
剩余63页未读,继续阅读
2021-10-14 上传
2018-09-01 上传
2021-01-20 上传
2023-12-01 上传
2023-05-12 上传
2023-06-08 上传
2023-11-05 上传
2023-09-01 上传
2023-06-13 上传

tdxueli
- 粉丝: 1
- 资源: 143
 我的内容管理
展开
我的内容管理
展开







