堆排序详解:小顶堆与自定义数据结构实现
83 浏览量
更新于2024-08-30
收藏 355KB PDF 举报
堆排序是一种基于比较的排序算法,它属于选择排序的一种变体,特别适用于大数据量的场景,因为它的时间复杂度在最坏情况下为O(n log n),平均时间复杂度也为O(n log n)。在本文中,我们将详细介绍堆排序中的关键概念——小顶堆。
小顶堆,也称为最大堆,是一种特殊的完全二叉树数据结构。在小顶堆中,每个节点的值都大于或等于其子节点的值。根节点的值总是整个堆中最大的,这使得堆排序的过程相对直观。堆排序的核心步骤是建立堆和调整堆。
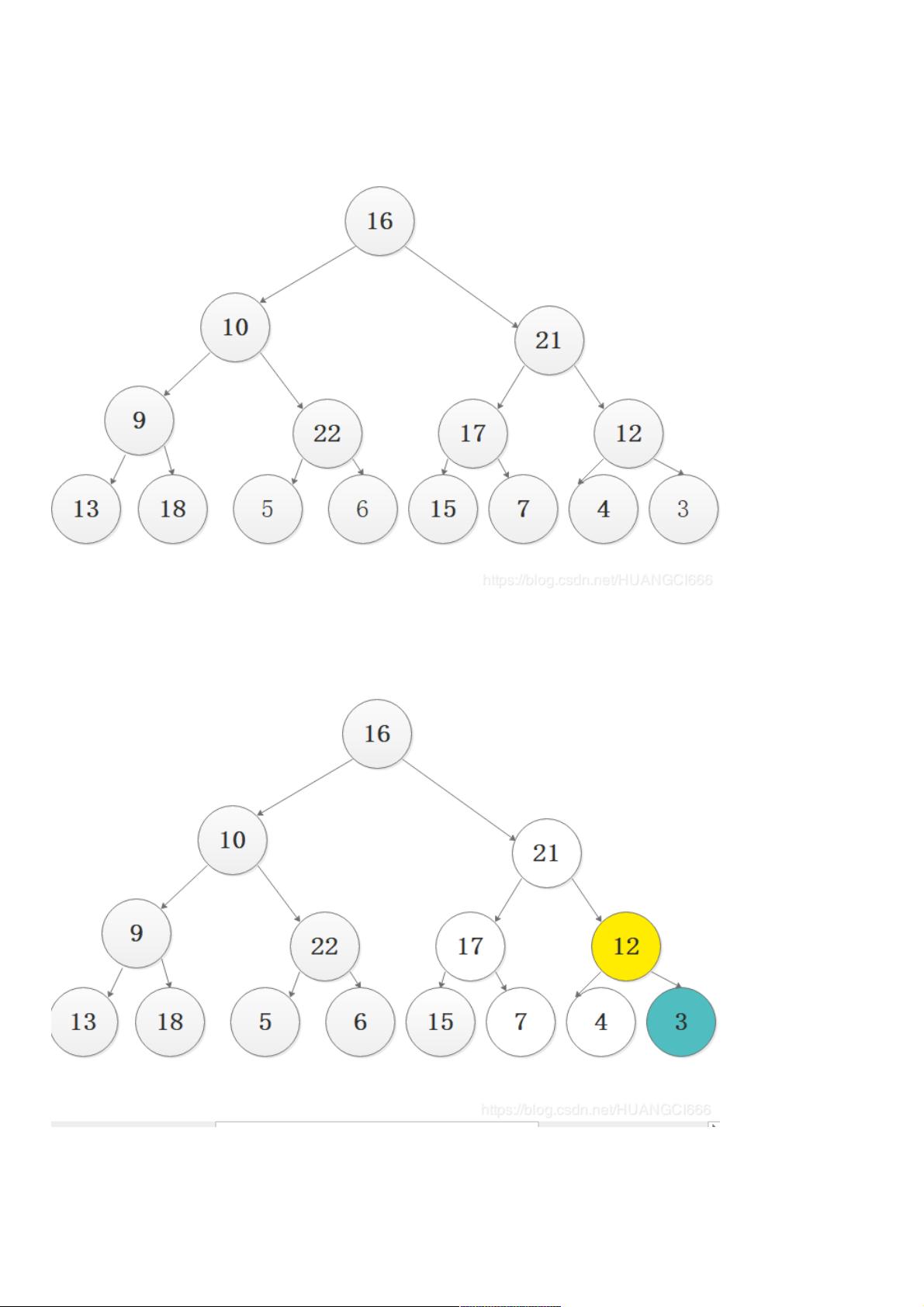
堆化是堆排序的起始步骤,它通过从最后一个非叶子节点(即倒数第二个节点)开始,逐个向下检查并调整堆的性质,确保满足小顶堆的规则。这个过程是从右向左进行的,通过比较当前节点与其子节点的大小,如果不符合小顶堆条件,就进行交换,并递归地检查父节点,直到堆化完成。
堆排序的主要流程包括以下几个步骤:
1. 建立初始堆:将待排序的数组视为一个完全二叉树,将其转换成一个小顶堆。
2. 堆顶元素与末尾元素交换:将堆顶(最大值)与末尾元素交换,此时末尾元素成为新的堆顶。
3. 调整堆:由于交换后堆的结构被破坏,需要重新调整剩余元素,使其恢复为小顶堆状态。
4. 重复步骤2和3,直到整个数组有序。
给出的Java代码片段展示了堆排序的具体实现,通过`MinHeapFixDown`方法实现了堆化操作。在`main`方法中,首先读取用户输入的整数数组,然后调用`sort`函数进行排序。`sort`函数中,首先创建一个最小堆,然后调用`MinHeapFixDown`方法,从根节点开始下沉,保证每个节点都符合小顶堆规则。当堆化完成后,数组就被排序好了。
堆排序算法的优点在于空间复杂度低,只需要一个额外的存储空间用于临时交换,适合内存有限的情况。然而,它不适合实时排序,因为每次交换都需要遍历整个堆。堆排序是一种简单且高效的排序算法,尤其适用于需要排序大量数据的场景。
算法算法 十大排序十大排序 堆排序堆排序
十种排序算法十种排序算法——堆排序堆排序(小顶堆小顶堆)
首先要了解什么是堆?小顶堆又是什么?而堆排序是十种排序种唯一种自定义的数据结构首先要了解什么是堆?小顶堆又是什么?而堆排序是十种排序种唯一种自定义的数据结构
这里的堆就是我们所熟悉的二叉树
而小顶堆又是什么呢?而小顶堆又是什么呢?
小顶堆就是根节点比子节点小,子节点比叶子节点小。小顶堆就是根节点比子节点小,子节点比叶子节点小。
所以我们第一步是进行堆化,从它倒数第一个子节点进行堆化(从右到左)
下载后可阅读完整内容,剩余6页未读,立即下载
2024-09-26 上传
2011-04-28 上传
2009-11-27 上传
2024-05-22 上传
2011-04-10 上传
2013-09-19 上传
2020-09-03 上传

weixin_38669793
- 粉丝: 6
- 资源: 938
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
