MLDM 2016: 模式识别中的机器学习与数据挖掘
需积分: 9 50 浏览量
更新于2024-07-18
收藏 42.57MB PDF 举报
"Machine Learning and Data Mining in Pattern Recognition" 是第12届国际机器学习与数据挖掘会议(MLDM 2016)的会议论文集,该会议在纽约举行,作为“智能数据与信号分析前沿大会(DSA2016)”的一部分。此资源主要关注机器学习、数据挖掘以及它们在模式识别中的应用。
正文:
机器学习(Machine Learning)是人工智能的一个分支,主要研究如何使计算机系统通过经验或数据自我改进和学习。它涉及各种算法,如监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)、半监督学习(Semi-Supervised Learning)和强化学习(Reinforcement Learning)。在监督学习中,系统通过已标记的数据进行训练,例如,用图像分类问题,系统会学习如何将图像分配到正确的类别。无监督学习则处理未标记的数据,如聚类(Clustering),目标是找到数据内在的结构和关系。半监督学习介于两者之间,通常用于大量未标记数据的场景。强化学习则让系统通过与环境的交互学习最优策略。
数据挖掘(Data Mining)则是从大量数据中发现有价值信息的过程。它包括关联规则学习(Association Rule Learning)、序列模式挖掘(Sequential Pattern Mining)、异常检测(Anomaly Detection)、概念分层(Concept Drifting)等方法。例如,关联规则学习常用于市场篮子分析,揭示商品间的购买关联;序列模式挖掘用于发现时间序列数据中的模式,如用户行为序列;异常检测则用于找出与正常行为模式偏离的事件,可能用于欺诈检测或设备故障预测。
在模式识别(Pattern Recognition)中,机器学习和数据挖掘技术常常结合使用。模式可以是图像、声音、文本或其他形式的数据。通过特征提取(Feature Extraction)、分类器设计(Classifier Design)和模型训练,系统能够识别并分类不同的模式。例如,深度学习(Deep Learning)通过多层神经网络实现高级特征的学习,已经在图像识别、语音识别等领域取得了重大突破。
会议论文集《Machine Learning and Data Mining in Pattern Recognition》可能涵盖了这些领域的最新研究进展、理论发展和实际应用案例。这些内容对理解如何利用机器学习和数据挖掘技术解决模式识别问题,以及推动相关领域的发展具有重要意义。参会者和读者可以从论文集中获取到学者们在这些关键技术上的创新思想和实践经验,从而提升自己的研究水平和应用能力。
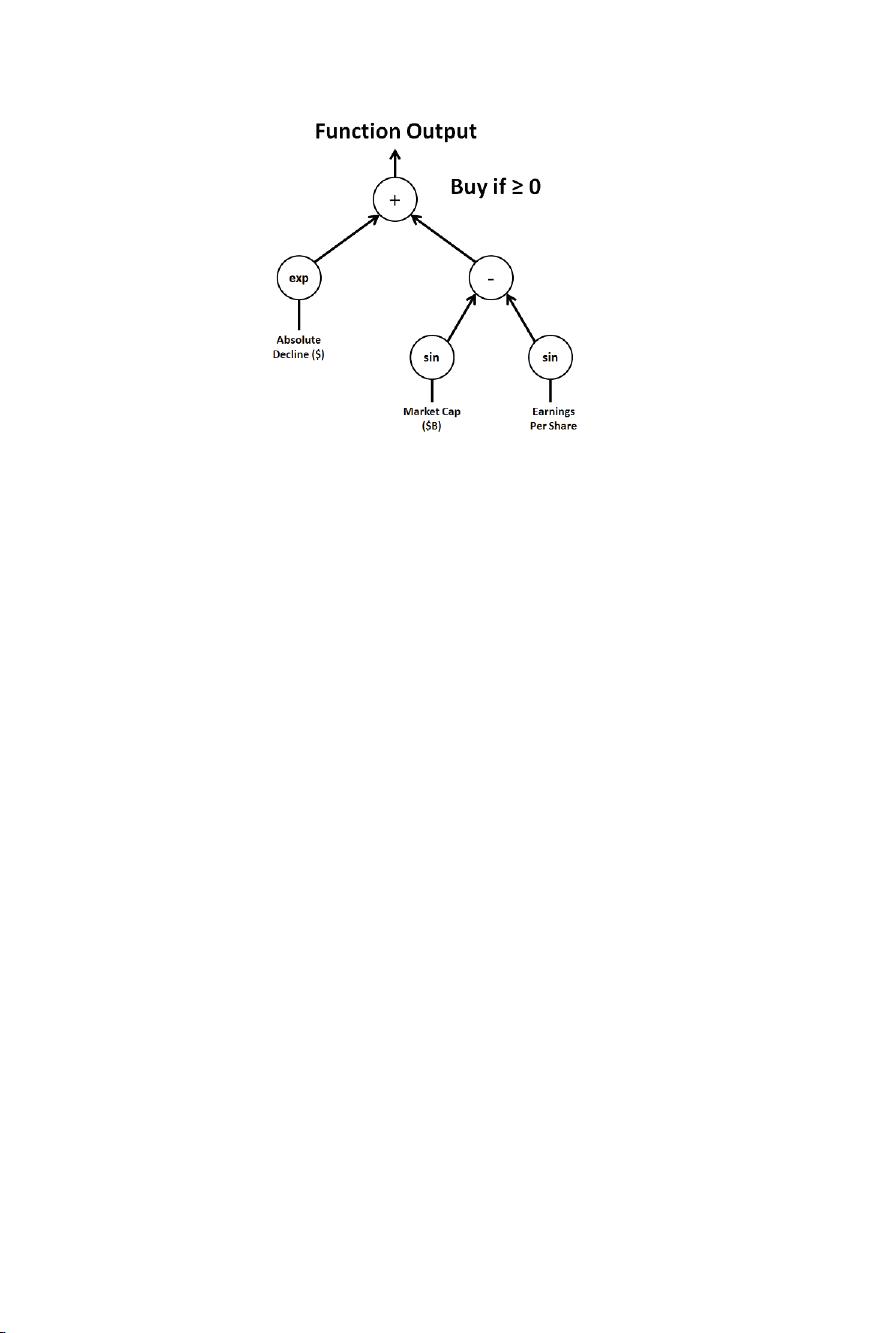
4 R.E. Marmelstein et al.
Fig. 2. Function represented as a GP tree structure
2.1 LPRS Agent Fitness Functions
Our GP utilized two types of fitness functions to evolve the LPRS agent. The
first function type is based on a Confusion Matrix (CM) [10], which measures
the agents ability to correctly classify each candidate stock as recovered or non-
recovered. In machine learning, a CM contains the true positives, false posi-
tives and false negatives for every class in the data set. In our approach, the
classification results over the training set are put in a confusion matrix (X).
Each diagnonal value of the matrix (x
ii
) represents the true positives the ith
class–that is, the percentage of class i that was correctly classfied. The fitness
value is computed by multiplying the diagonal values of the matrix together (see
Equation 1). Thus, the fitness metric reflects the agents ability to correctly dis-
criminate between classes, even if it comes at the expense of overall classification
accuracy.
F itness =
n
i=1
x
ii
(1)
The second type of fitness function returns the overall profit (P) ratio earned
by the agent. For this case, a simulation is elaborated with the LPRS agent’s
portfolio having an initial cash balance and no stocks on a predetermined start
date. Beginning with this date, trade decisions are made in temporal order, as
candidates are identified. Stock holdings are sold according to the rules enu-
merated in section 1.1. Capital gains on trades are added to the available cash
reserve in the account; likewise, capital losses are subtracted. Using this app-
roach, purchases are only carried out if the sufficient free cash exists in the
portfolio to cover the transaction. The fitness result is returned based on the
percent increase in portfolio value within 60 days after the last security pur-




剩余818页未读,继续阅读
2017-11-29 上传
2018-03-19 上传
2023-05-17 上传
2023-04-03 上传
2023-06-12 上传
2023-07-08 上传
2023-03-29 上传
2023-05-25 上传
2023-05-17 上传

dyt12345678
- 粉丝: 3
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
