NSGA3:进化多目标优化算法
需积分: 49 164 浏览量
更新于2024-07-19
6
收藏 2.06MB PDF 举报
"NSGA3:一种基于参考点的非支配排序多目标优化算法,用于解决具有箱约束的问题"
NSGA3(非支配排序遗传算法3)是进化多目标优化算法的一种,它主要针对具有四个或更多目标的优化问题。NSGA3是在NSGA2的基础上发展起来的,两者在算法框架上基本相似,但选择机制有所差异。NSGA2使用拥挤距离(Crowding Distance)作为选择策略,即对于处于同一非支配层的个体,拥挤距离越大,其优选度越高。这种方法对于处理两到三个目标的问题效果良好,但在面对更多目标时,可能会导致解的分布不均匀,从而影响算法的收敛性和多样性,使算法容易陷入局部最优。
NSGA3引入了基于参考点(Reference Point)的方法来解决这一问题。参考点方法允许算法在多维目标空间中更有效地探索,以提高解的分布均匀性。通过这种方式,NSGA3能够更好地维护种群的多样性,防止过早收敛,并确保在多目标优化中找到更广泛的帕累托前沿。在处理具有多个相互冲突目标的复杂问题时,这种改进的选择策略至关重要。
本文的第一部分专注于解决具有箱约束的问题。箱约束指的是问题中变量的取值范围受到上下限的限制,这在实际应用中非常常见。在这样的环境中,NSGA3需要能够适应这些限制,同时保持其优化能力。作者Kalyanmoy Deb和Himanshu Jain探讨了最近的一些努力和可能的发展方向,提出了一种潜在的进化多目标优化算法,以解决具有多个目标和约束条件的优化问题。
在实现NSGA3的过程中,有几个关键步骤包括:初始化种群、非支配排序、计算拥挤距离、基于参考点的选择以及变异和交叉操作。这些步骤共同作用,使得算法能够在不断迭代中逐步接近全局最优解集。非支配排序是NSGA系列算法的核心,它将个体按照非支配关系分为多个层级,每一层内的个体则通过拥挤距离进行进一步筛选。参考点的选择和更新策略则是NSGA3的关键创新,它们有助于在多目标优化过程中维持种群的多样性和探索性。
NSGA3是进化计算领域中解决多目标优化问题的一个强大工具,尤其是在面临多个相互冲突的目标和约束条件时。通过采用参考点策略,NSGA3能够在多目标优化的复杂环境下,提供更加均衡且多样化的解决方案,这对于工程设计、资源分配等实际问题具有重大意义。
Copyright (c) 2013 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.
5
neighboring solutions. Thereafter, the solutions having larger
crowding distance values are chosen. Here, we r ep lace the
crowding distance operator with the following approach es
(subsections IV-A to IV-E).
A. Classification of Population into Non-dominated Levels
The ab ove procedure of identifying non-dominated f ron ts
using the usual domination principle [17] is also used in
NSGA-III. All popu lation members fro m non-dominated front
level 1 to level l are first included in S
t
.If|S
t
| = N,nofurther
operations are needed and the next generation is started with
P
t+1
= S
t
.For|S
t
| >N,membersfromoneto(l − 1)
fronts are already selected, that is, P
t+1
= ∪
l−1
i=1
F
i
,andthe
remaining (K = N −|P
t+1
|) population members are chosen
from the last front F
l
.Wedescribetheremainingselection
process in the following subsections.
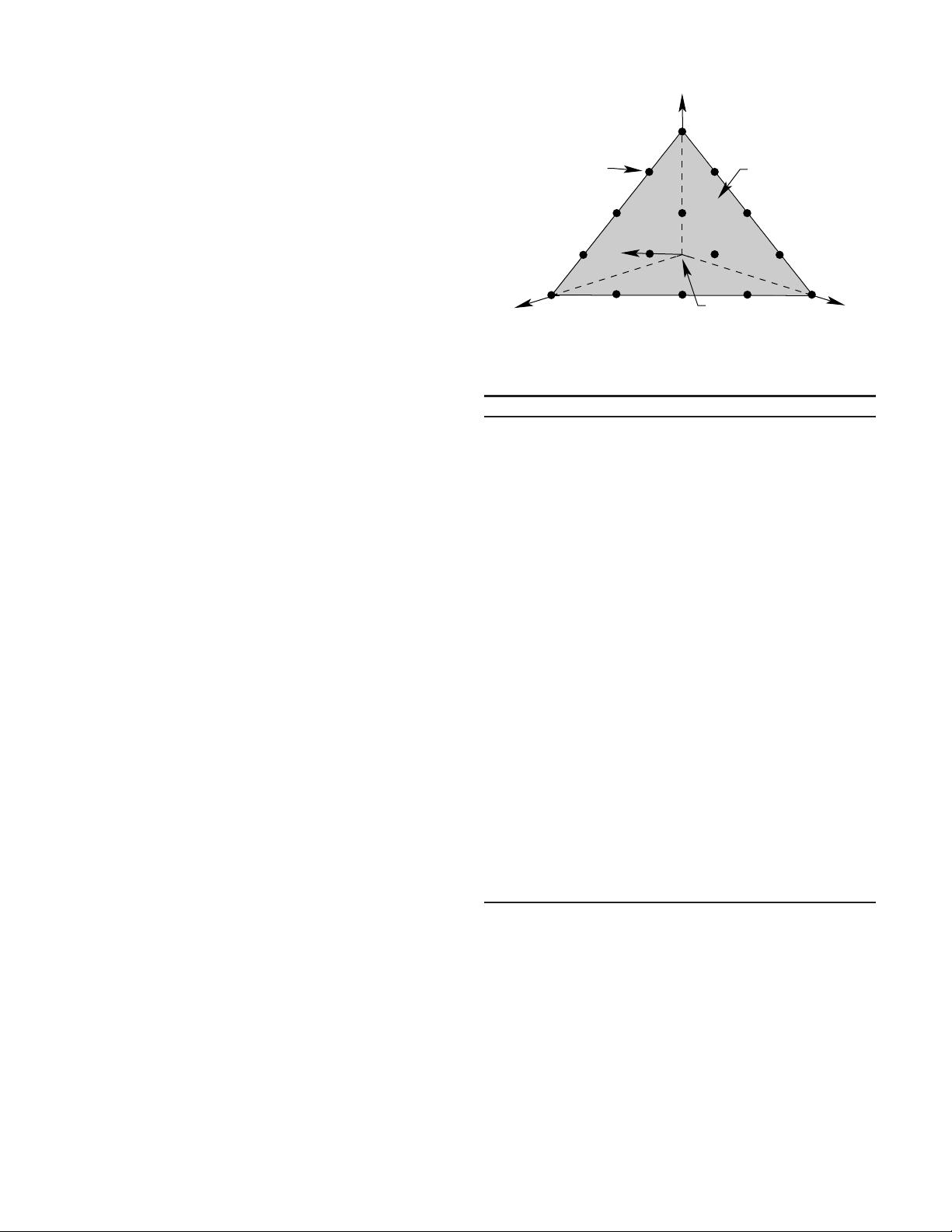
B. Determination of Reference Points o n a Hyper-Plane
As indicated befo re, NSGA-III uses a predefined set of
reference p oints to ensure diversity in obtained solutions.
The chosen reference p oints can either be predefined in a
structured manner or supplied preferentially by the user. We
shall present results of both methods in the results section later.
In the absence o f any preference information, any predefined
structured placement of reference points can be adopted, butin
this paper we use Das and Dennis’s [48] systematic approach
1
that places points on a normalized hyper-plane –a(M − 1)-
dimensional unit simplex – which is equally inclined to all
objective axes and has an intercept of one on each axis. If p
divisions are considered along each objective, the total number
of reference points (H)inanM-objective problem is given
by:
H =
!
M + p − 1
p
"
. (3)
For example, in a three-objective problem (M =3), the
reference points are created on a triangle with apex at (1, 0, 0),
(0, 1, 0) and (0, 0, 1).Iffourdivisions(p =4)arechosenfor
each objective axis, H =
#
3+4−1
4
$
or 15 reference points will
be created. For clarity, these reference points are shown in
Figure 1. In the proposed NSGA-III, in addition to emphasiz-
ing non-dominated solutions, we also emphasize population
members which are in some sense associated with each
of these reference points. Since the above-created reference
points are widely distributed on the entire normalized hyper-
plane, the obtained solutions are also likely to be widely
distributed on or near the Pareto-optimal front. In the case of a
user-supplied set of preferred reference points, ideally the user
can mark H points on the normalized hyper-plane or indicate
any H, M -d imensional vectors for the purpose. The proposed
algorithm is likely to find near Pareto-optimal solutions cor-
responding to the supplied reference points, thereby allowing
this method to be used more from the point of view of a
combined application of decision-making and many-objective
optimization. The procedure is presented in Algorithm 1.
1
Any other structured distribution with or without a biasing on some part
of the Pareto-optimal front can be used as well.
hyperplane
Normalized
line
Reference
point
Reference
Ideal point
1
1
f1
f3
1
f2
Fig. 1. 15 reference points are shown on a normalized reference plane for
athree-objectiveproblemwithp =4.
Algorithm 1 Generation t of NSGA-III procedure
Input: H structured reference points Z
s
or supplied aspira-
tion points Z
a
,parentpopulationP
t
Output: P
t+1
1: S
t
= ∅, i =1
2: Q
t
= Recombination+Mutation(P
t
)
3: R
t
= P
t
∪ Q
t
4: (F
1
,F
2
,...)=Non- dominated-sor t(R
t
)
5: repeat
6: S
t
= S
t
∪ F
i
and i = i +1
7: until |S
t
|≥N
8: Last front to be included: F
l
= F
i
9: if |S
t
| = N then
10: P
t+1
= S
t
,break
11: else
12: P
t+1
= ∪
l−1
j=1
F
j
13: Points to be chosen from F
l
: K = N −|P
t+1
|
14: Normalize objectives and create reference set Z
r
:
Normalize(f
n
,S
t
,Z
r
,Z
s
,Z
a
)
15: Associate each membe r s of S
t
with a reference point:
[π(s),d(s)] =Associate(S
t
,Z
r
) % π(s):closest
reference point, d:distancebetweens and π(s)
16: Compute niche count of reference point j ∈ Z
r
: ρ
j
=
%
s∈S
t
/F
l
((π(s)=j)?1 : 0)
17: Choose K members o ne at a time from F
l
to construct
P
t+1
: Niching(K, ρ
j
,π,d,Z
r
,F
l
,P
t+1
)
18: end if
C. Adaptive Normalization of Population Members
First, the ideal point of the population S
t
is determined
by identifying the minimum value (z
min
i
), for each objective
function i =1, 2,...,M in ∪
t
τ =0
S
τ
and by constructing the
ideal point ¯z =(z
min
1
,z
min
2
,...,z
min
M
).Eachobjectivevalue
of S
t
is then translated by subtracting objective f
i
by z
min
i
,
so that the ideal point of translated S
t
becomes a zero vector.
We denote this translated objective as f
$
i
(x)=f
i
(x) − z
min
i
.
Thereafter, the extreme po int in each objective axis is identi-
fied by finding the solution (x ∈ S
t
)thatmakesthefollowing
achievement scalarizing function minimum with weight vector
剩余22页未读,继续阅读
2020-07-10 上传
2021-05-23 上传
2021-05-10 上传
2021-05-25 上传
2021-02-05 上传
2023-05-23 上传
2021-05-15 上传

jueqingnikong
- 粉丝: 13
- 资源: 39
 我的内容管理
展开
我的内容管理
展开







最新资源
- R语言中workflows包的建模工作流程解析
- Vue统计工具项目配置与开发指南
- 基于Spearman相关性的协同过滤推荐引擎分析
- Git基础教程:掌握版本控制精髓
- RISCBoy: 探索开源便携游戏机的设计与实现
- iOS截图功能案例:TKImageView源码分析
- knowhow-shell: 基于脚本自动化作业的完整tty解释器
- 2011版Flash幻灯片管理系统:多格式图片支持
- Khuli-Hawa计划:城市空气质量与噪音水平记录
- D3-charts:轻松定制笛卡尔图表与动态更新功能
- 红酒品质数据集深度分析与应用
- BlueUtils: 经典蓝牙操作全流程封装库的介绍
- Typeout:简化文本到HTML的转换工具介绍与使用
- LeetCode动态规划面试题494解法精讲
- Android开发中RxJava与Retrofit的网络请求封装实践
- React-Webpack沙箱环境搭建与配置指南
