HDFS实验报告:大数据技术课程实践
下载需积分: 30 | DOCX格式 | 728KB |
更新于2024-08-10
| 193 浏览量 | 举报
"本次实验是关于Hadoop分布式文件系统(HDFS)的学习,实验者姚能燕使用了Ubuntu Linux 20.04.1操作系统,Hadoop 2.10.1版本,JDK 1.8.0_261,Eclipse 2020-06作为Java集成开发环境,Putty 0.74作为远程连接工具,以及FileZilla Client 3.50.0进行文件传输。"
在Hadoop_HDFS的背景下,这个实验主要涉及以下几个关键知识点:
1. **Hadoop分布式文件系统(HDFS)**:HDFS是一种基于分布式计算的大型数据存储系统,它是Apache Hadoop项目的核心组成部分。HDFS设计的目标是处理大规模数据集,通过将数据分布在多台廉价的服务器上,实现高容错性和高可用性。
2. **HDFS架构**:HDFS由NameNode和DataNode组成。NameNode是主节点,负责元数据管理,包括文件系统的命名空间和文件的块映射信息。DataNode则是从节点,存储实际的数据块,并根据NameNode的指令执行数据的读写操作。
3. **Hadoop版本2.10.1**:这是Hadoop的一个稳定版本,包含了一些性能优化和错误修复。选择该版本意味着实验者将使用经过广泛测试和验证的HDFS实现。
4. **Java Development Kit (JDK)**:Hadoop是用Java编写的,因此JDK 1.8.0_261是运行Hadoop和编写Hadoop应用程序的必备组件。Java的版本选择确保了与Hadoop的兼容性。
5. **Eclipse 2020-06**:作为Java IDE,Eclipse被用于编写、测试和调试Hadoop MapReduce程序,它提供了丰富的插件支持,使得开发HDFS应用更加便捷。
6. **Putty 0.74**:这是一个SSH客户端,用于远程登录到运行Hadoop集群的服务器,进行命令行操作,如启动、停止Hadoop服务,监控系统状态等。
7. **FileZilla Client 3.50.0**:这是一个FTP/SFTP客户端,实验者可能用它来上传或下载文件到HDFS,或者在集群的不同节点间传输文件。
实验中,学生可能会接触到以下操作:
- **配置Hadoop**:包括修改`hdfs-site.xml`和`core-site.xml`等配置文件,设置HDFS的相关参数。
- **启动/停止HDFS**:使用`start-dfs.sh`和`stop-dfs.sh`脚本启动和关闭HDFS服务。
- **HDFS操作**:如使用`hadoop fs`命令进行文件的创建、删除、移动、复制等操作。
- **数据分布和冗余**:理解HDFS如何将文件分割成块并复制到多个DataNode,以实现容错。
- **故障恢复**:模拟DataNode故障,观察HDFS如何自动恢复数据。
- **HDFS Shell命令**:学习和使用各种HDFS Shell命令,了解其工作原理。
通过这样的实验,学生可以深入理解HDFS的工作机制,提升对大数据处理和分布式存储的理解,为后续的大数据分析和处理打下坚实基础。
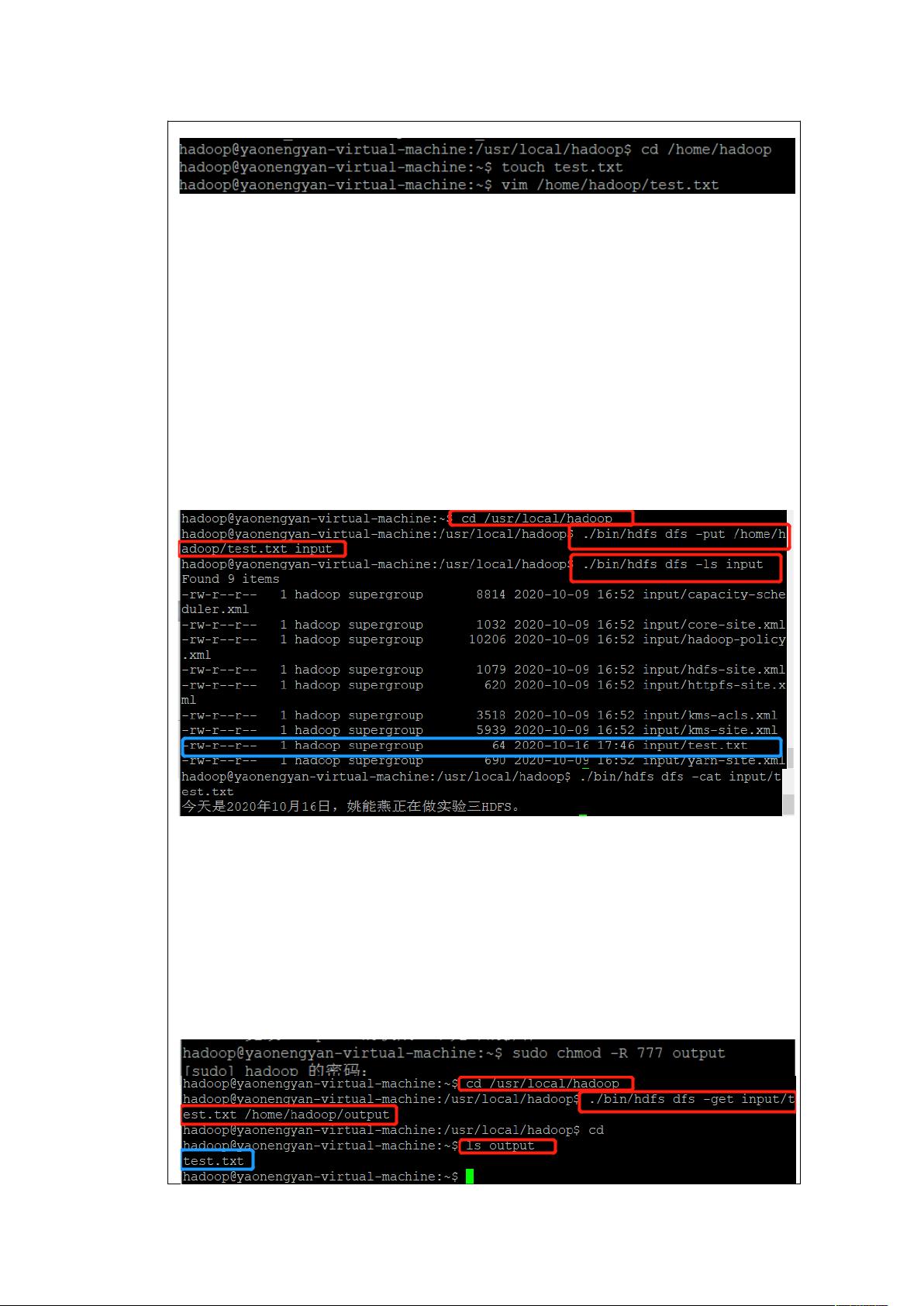
输入内容:今天是 2020 年 10 月 16 日,姚能燕正在做实验三 HDFS。
其次,输入内容完成之后,进入/usr/local/hadoop 目录下,把/
home/hadoop/test.txt 传到虚拟机本地的 input 下,并查看传输后的
input 下有无刚刚的 test.txt 文件,并用 cat 命令可以查看 test.txt 文件的
内容。
操作的命令以及结果如下图所示:
再者,把刚刚的 hdfs 里的 test.txt 文件下载到本地的/home/
hadoop/output 目录下。注意:要修改 output 的权限,否者将会提示
权限不够。
操作命令以及结果如下图所示:
剩余11页未读,继续阅读
相关推荐




努力的小包
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Cairngorm中文版:Flex应用设计指南
- ThinkPHP 1.0.0RC1 开发者手册:框架详解与应用构建
- ZendFramework中文手册:访问控制与认证
- 深入理解C++指针:从基础到复杂类型
- Java设计模式详解:从基础到高级
- JavaScript高级教程:深入解析基础与对象
- Qt教程:从Hello World到GUI游戏开发
- RealView编译工具链2.0:链接程序与实用程序深度解析
- Unicode编码与.NET Framework中的实现
- Linux内核0.11完全注释 - 赵炯
- C++ 程序设计员面试试题深入分析与解答
- Tomcat深度解析:配置、应用与优势
- 车辆管理系统:全面解决方案与功能设计
- 使用JXplorer连接Apache DS LDAP服务器指南
- 电子商务环境下的企业价值链分析及增值策略
- SAP仓库管理系统详解:灵活高效的库存控制
