R语言中rpart包实现决策树分析:以Iris数据集为例
在R语言中实现决策树算法通常通过rpart包来完成,这是一个专门用于构建决策树模型的工具。本文将介绍如何利用rpart函数以及Iris数据集来构建一个分类决策树。
首先,我们从加载rpart包开始,这是实现决策树的基础。通过`library(rpart)`命令,我们可以确保在后续的操作中可以使用rpart函数及其相关的功能。Iris数据集是一个经典的多类分类问题数据集,包含150个样本,每个样本有四个连续变量(花萼长度、花萼宽度、花瓣长度和花瓣宽度)和三个类别(Setosa、Versicolour和Virginica)。
在构建决策树时,我们需要明确以下几个关键步骤:
1. **数据预处理**:使用`head(iris)`查看数据集结构,了解变量类型和分布,这对于选择适当的算法参数至关重要。Iris数据集的因变量是Species,它是离散型数据,因此我们选用`method="class"`来构建分类决策树。
2. **构建模型**:`rpart(Species~., data=iris, method="class", parms=list(split="gini"))`这一行代码创建了决策树模型。`formula`部分指定了因变量和自变量的关系,`Species~.`表示预测变量Species依赖于所有其他变量。`data`参数是输入数据集,`method="class"`指定因变量为分类问题。`parms`列表用于设置纯度度量方法,这里选择了Gini指数(默认)。
3. **可视化决策树**:`plot(iris.rp1, uniform=T, branch=0, margin=0.1, main="ClassificationTree\nIrisSpeciesbyPetalandSepalLength")`用于绘制决策树图形。`uniform`参数控制图形在空间上的分布,`branch`控制节点分支的形状,`margin`决定树的大小。`main`设置了图的标题,包括换行符`\n`以便清晰展示。
4. **添加节点信息**:`text(iris.rp1, use.n=T, fancy=T, col="blue")`和`text(iris.rp1, use.n=T, fancy=F, col="blue")`用于在每个节点上显示观测数据的数量及其类别。`use.n=T`表示包含数量信息,`fancy`参数控制节点标记的样式,`col`设置颜色。
通过以上步骤,你可以看到如何在R语言中利用rpart包实现决策树模型,并对Iris数据集进行分类分析。这不仅可以帮助理解决策树的工作原理,还可以用于处理其他具有相似结构的数据集,只需调整公式、方法和参数以适应不同的问题类型。
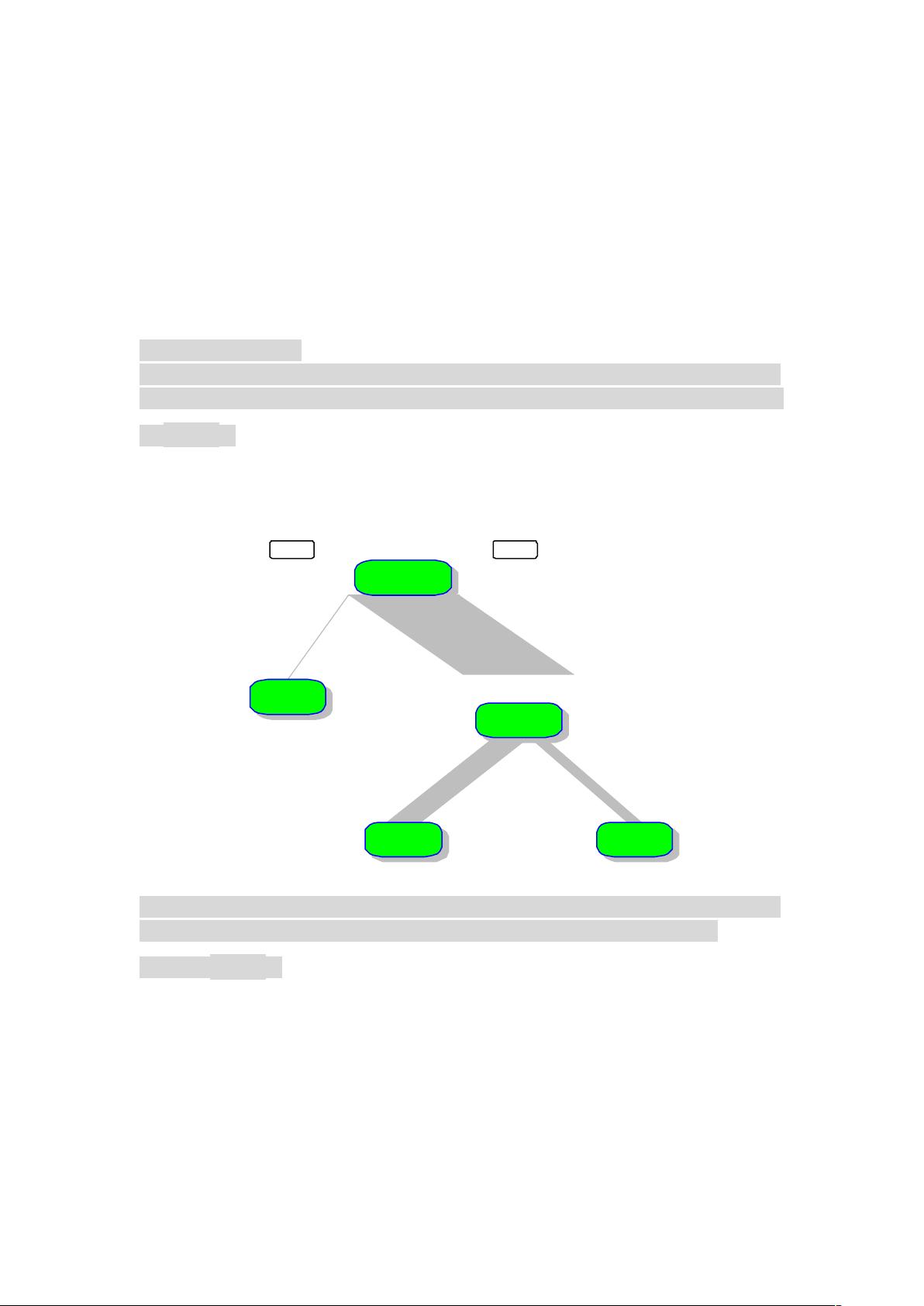
分类,use.n=F 时就不显示观测个数了。
(2) fancy=T、F 的区别见上图
(3) col=“blue”就是写在树上的信息的颜色。
还有另一种画图函数
library(rpart.plot)
rpart.plot(iris.rp1,branch=0,branch.type=2,type=1,extra=1,shadow.
col="gray",box.col="green",border.col="blue",split.col="red" ,main
="决策树")
决策树
yes
no
Petal.Le < 2.4
Petal.Wi < 1.8
setosa
50 50 50
setosa
50 0 0
versicol
0 50 50
versicol
0 49 5
virginic
0 1 45
yes
no
rpart.plot(iris.rp1,branch=0,branch.type=0,type=1,extra=1,shadow.
col="gray",box.col="green",border.col="blue",split.col="red",
main="决策树")
剩余20页未读,继续阅读
2021-01-07 上传
2022-09-21 上传
点击了解资源详情
2024-09-24 上传
2013-08-16 上传
2019-02-17 上传

guohangfly
- 粉丝: 1
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
