C++实现:线性时间复杂度的非比较排序算法
78 浏览量
更新于2024-08-29
收藏 122KB PDF 举报
"本文主要分析了C++中三种线性时间复杂度的非比较排序算法——计数排序、基数排序和桶排序,它们突破了比较排序的Ω(nlgn)时间下界。"
在排序算法的世界里,比较排序是常见的方法,如插入排序、冒泡排序、快速排序等,它们依赖于元素间的比较来决定顺序。然而,这些基于比较的排序算法在最坏情况下都有Ω(nlgn)的时间复杂度下限,这意味着它们的运行速度不会超过这个界限。这一理论可以通过决策树模型进行证明。
为了超越这个时间限制,我们可以转向非比较排序算法。计数排序、基数排序和桶排序就是这样的例子,它们能在线性时间内完成排序,即O(n)的时间复杂度。
1. 计数排序(Counting Sort):
这种排序算法适用于整数排序,其基本思想是统计数组中每个元素出现的次数,然后根据这些统计信息来确定每个元素在输出数组中的位置。具体步骤包括:
- 找出输入数组的最大和最小值。
- 统计每个元素i出现的次数,存储在新的计数数组C中。
- 对计数数组C进行累加,得到每个元素应该在输出数组中的位置。
- 反向填充目标数组,按照每个元素i在C中的位置将其放入,同时递减C(i)。
2. 基数排序(Radix Sort):
基数排序是按数字的位数进行排序,从低位到高位,或者从高位到低位。对于每一位,都可以使用其他线性时间的排序算法(如计数排序)进行处理。当所有位数处理完毕,整个数组就按照基数完成了排序。
3. 桶排序(Bucket Sort):
桶排序假设输入数据服从均匀分布,将数据分到有限数量的桶里。每个桶再分别排序,最后按照顺序合并所有桶中的元素。如果每个桶内的元素数量较少,那么桶排序可以在线性时间内完成。
这些非比较排序算法的优势在于,它们不是通过比较元素之间的大小关系来排序,而是利用特定的性质(如数值范围、位数等)直接确定元素的位置。因此,它们在特定条件下能实现线性时间复杂度,但缺点是可能需要额外的空间,且对数据的特性有较高要求。
理解并掌握这些非比较排序算法,可以让我们在面对特定类型的排序问题时,选择更高效的方法,提高算法的执行效率。特别是在大数据量或对时间复杂度有严格要求的情况下,非比较排序算法能够提供显著的优势。
C++线性时间的排序算法分析线性时间的排序算法分析
前面的文章已经介绍了几种排序算法,如插入排序(直接插入排序,折半插入排序,希尔排序)、交换排序(冒泡排序,快速
排序)、选择排序(简单选择排序,堆排序)、2-路归并排序(可以参考前一篇文章:各种内部排序算法的实现)等,这些排
序算法都有一个共同的特点,就是基于比较。
本文将介绍三种非比较的排序算法:计数排序,基数排序,桶排序。它们将突破比较排序的Ω(nlgn)下界,以线性时间运行。
一、比较排序算法的时间下界一、比较排序算法的时间下界
所谓的比较排序是指通过比较来决定元素间的相对次序。
“定理:对于含n个元素的一个输入序列,任何比较排序算法在最坏情况下,都需要做Ω(nlgn)次比较。”
也就是说,比较排序算法的运行速度不会快于nlgn,这就是基于比较的排序算法的时间下界。
通过决策树(Decision-Tree)可以证明这个定理,关于决策树的定义以及证明过程在这里就不赘述了。读者可以自己去查找
资料,这里推荐大家看一看麻省理工学院公开课:算法导论的《MIT公开课:线性时间排序》。
根据上面的定理,我们知道任何比较排序算法的运行时间不会快于nlgn。那么我们是否可以突破这个限制呢?当然可以,接下
来我们将介绍三种线性时间的排序算法,它们都不是通过比较来排序的,因此,下界Ω(nlgn)对它们不适用。
二、计数排序(二、计数排序(Counting Sort))
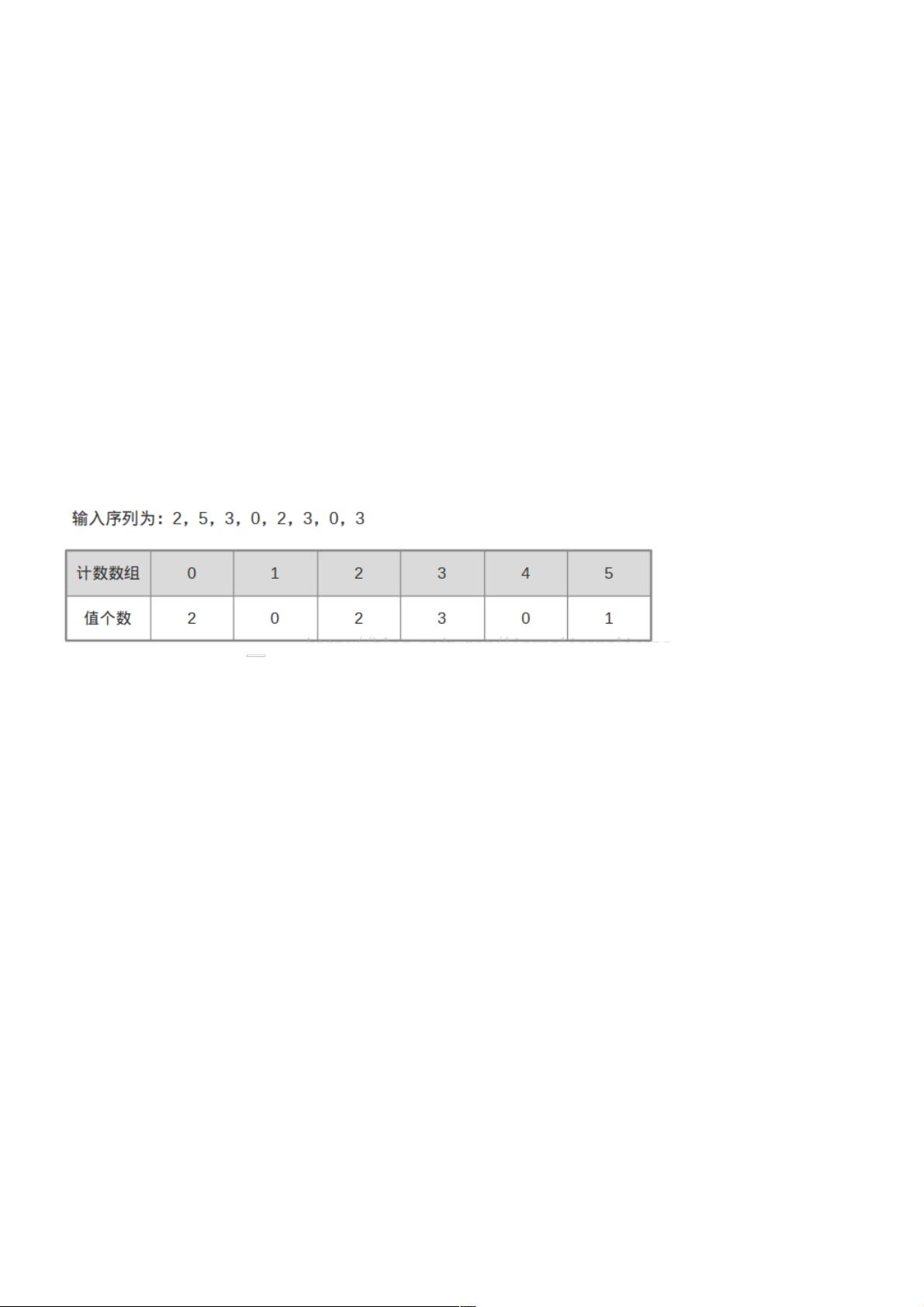
计数排序的基本思想就是对每一个输入元素x,确定小于x的元素的个数,这样就可以把x直接放在它在最终输出数组的位置
上,例如:
算法的步骤大致如下:算法的步骤大致如下:
①.找出待排序的数组中最大和最小的元素
②.统计数组中每个值为i的元素出现的次数,存入数组C的第i项
③.对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
④.反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
C++代码如下:代码如下:
/*************************************************************************
> File Name: CountingSort.cpp
> Author: SongLee
************************************************************************/
#include<iostream>
using namespace std;
/*
*计数排序:A和B为待排和目标数组,k为数组中最大值,len为数组长度
*/
void CountingSort(int A[], int B[], int k, int len)
{
int C[k+1];
for(int i=0; i<k+1; ++i)
C[i] = 0;
for(int i=0; i<len; ++i)
C[A[i]] += 1;
for(int i=1; i<k+1; ++i)
C[i] = C[i] + C[i-1];
for(int i=len-1; i>=0; --i)
{
B[C[A[i]]-1] = A[i];
下载后可阅读完整内容,剩余4页未读,立即下载
2008-11-01 上传
2012-06-09 上传
2011-05-11 上传
2010-10-19 上传
2024-03-10 上传
2008-07-02 上传
2020-09-04 上传
2010-11-09 上传
点击了解资源详情

weixin_38519763
- 粉丝: 5
- 资源: 922
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
