深度学习:从seq2seq到Transformer的机器翻译模型解析
116 浏览量
更新于2024-08-30
1
收藏 1.48MB PDF 举报
"本文主要探讨了从seq2seq模型到Transformer的发展,并着重讲解了seq2seq模型的基本概念、结构及实现方式,同时也提及了在机器翻译领域的应用。seq2seq模型由Encoder和Decoder组成,其中Encoder通过循环神经网络(RNN)处理输入序列,提取语义信息,然后Decoder接收Encoder的隐藏状态作为初始输入,生成目标序列。在训练和预测阶段,模型有不同的工作模式。文章还展示了Encoder、Decoder和EncoderDecoder类的基本定义,为实际的模型实现提供了框架。"
seq2seq模型是深度学习领域中用于处理序列到序列问题的一种架构,特别是在自然语言处理(NLP)任务如机器翻译中表现突出。该模型的核心在于其Encoder-Decoder结构,其中Encoder负责理解和编码输入序列的语义信息,而Decoder则基于这些信息生成对应的输出序列。
Encoder通常由一个或多个RNN层构成,例如长短期记忆网络(LSTM)或门控循环单元(GRU)。在训练过程中,Encoder对输入序列的每个时间步进行迭代,逐个处理单词,并将每个步骤的隐藏状态更新,最终得到一个包含了整个输入序列信息的向量,即上下文向量(context vector)。
Decoder同样基于RNN,它利用Encoder的上下文向量作为初始化状态,开始生成输出序列。在每个时间步,Decoder会根据上一步的隐藏状态和当前的输入(可能是上一步生成的词或起始令牌)来预测下一个单词,并更新其隐藏状态。预测过程直到生成特殊的结束标记为止。
在训练时,seq2seq模型采用 teacher forcing 方法,即在每个时间步,Decoder的输入是实际的参考输出序列的下一个词。而在预测时,Decoder使用上一步自己生成的词作为输入,这被称为自回归性解码。
为了简化和加速训练,Transformer模型应运而生。Transformer由Vaswani等人在2017年提出,它摒弃了RNN,转而采用自注意力机制和多头注意力机制,这使得模型可以并行计算,极大地提高了效率。此外,Transformer引入了位置编码来处理序列的位置信息,解决了纯注意力机制无法捕获序列顺序的问题。
在机器翻译任务中,seq2seq模型和Transformer模型都取得了显著的效果,但Transformer由于其并行性和强大的表示能力,已经成为现代NLP系统的基础架构之一。通过理解seq2seq模型的原理和实现方式,可以更好地理解Transformer的设计决策,并为优化和开发更先进的NLP模型奠定基础。
从从seq2seq模型到模型到Transformer以及机器翻译小记以及机器翻译小记
seq2seq模型模型
基本概念基本概念
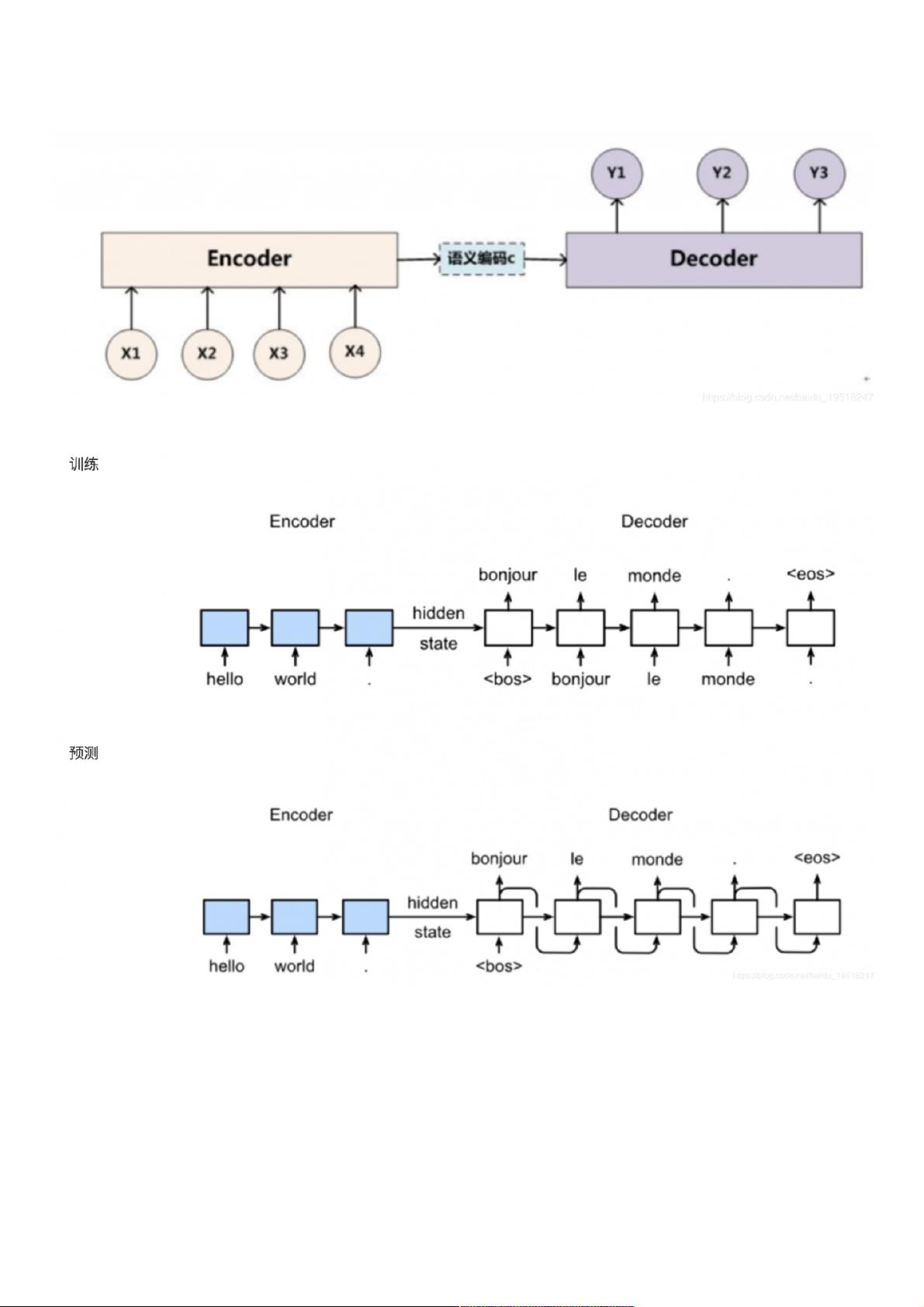
顾名思义,seq2seq模型是指,模型的输入是一个sequence序列,而模型的输出也是sequence序列,其模型结构可以表示为Encoder-Decoder结构,如下图:
其中encoder与decoder都是使用循环神经网络(RNN)实现的。其中的语义编码则是encoder的隐藏状态。其中包括了encoder中的语义信息,作为decoder的输入,从而使用
decoder得到输出。
训练以及预测时的方式如下:
具体结构:
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-06 上传
2021-01-06 上传
2021-01-06 上传
2023-07-02 上传
2021-01-06 上传
2021-01-06 上传

weixin_38569203
- 粉丝: 6
- 资源: 930
 我的内容管理
展开
我的内容管理
展开







