B树、B-树、B+树与R-tree详解:数据结构与平衡策略
版权申诉
69 浏览量
更新于2024-08-04
收藏 203KB DOC 举报
本文将深入总结B树、B-树、B+树、B*树++以及R-tree这几种常见的数据结构,它们都是在数据库管理系统和文件系统中广泛应用的数据组织方式。
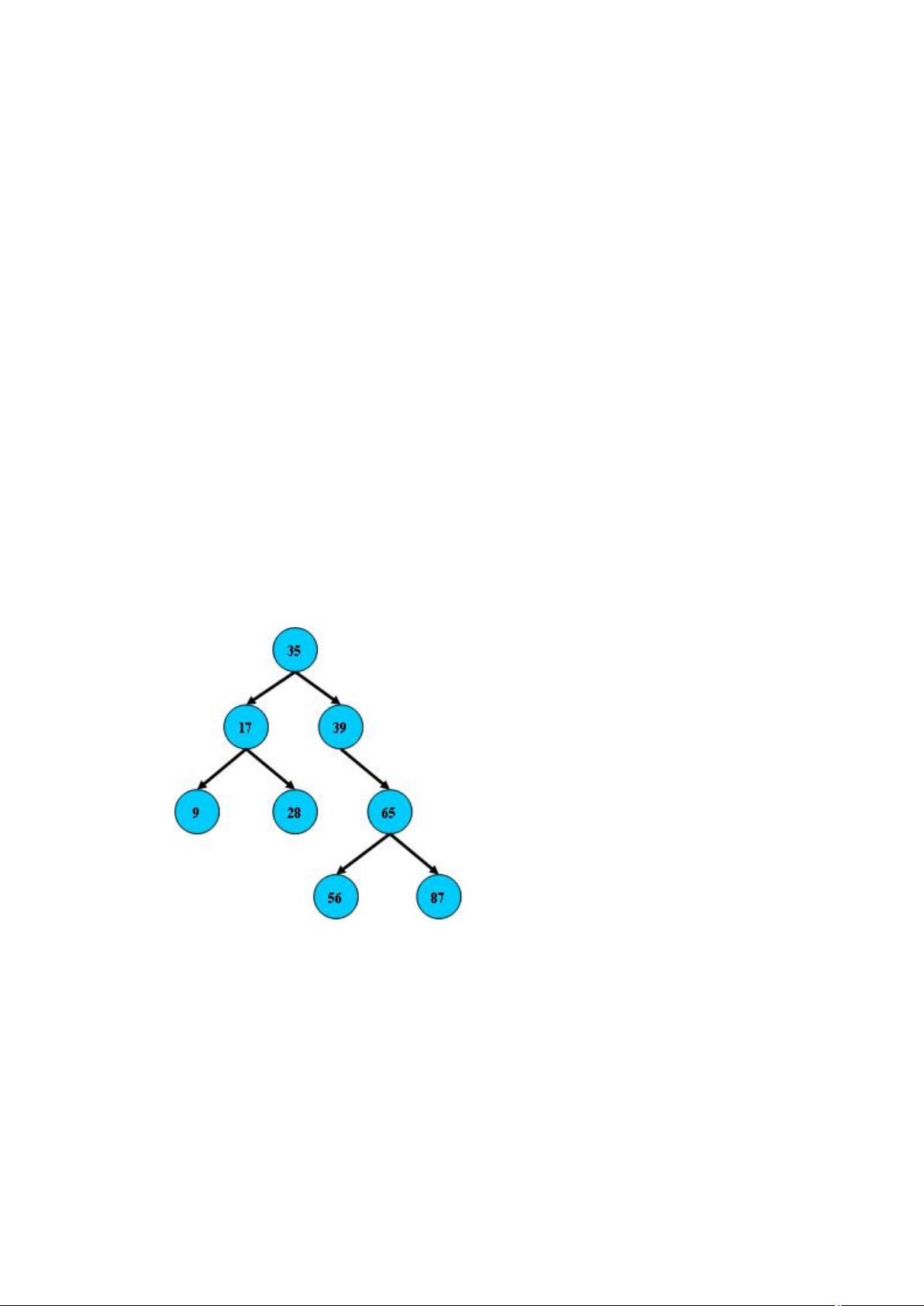
1. **B树**:
B树是一种自平衡的多路搜索树,它确保每个节点最多有两个子节点(在某些实现中可能更多,但通常限制为不超过两个),且所有节点都包含一定的关键字数。B树的关键特性是所有节点的平衡性,这使得搜索性能接近二分查找。B树插入和删除操作通常具有常数时间复杂度,因为即使树高度增加,也只需少量调整。为了保持平衡,实际应用中的B树通常会配合平衡算法进行操作。
2. **B-树**:
B-树是一种更为灵活的多路搜索树,允许每个非叶子节点有多于两个儿子(最多M个),且节点大小可以容纳M/2到M个关键字。根节点和内部节点的子节点数范围受限。B-树的搜索过程是对有序关键字序列进行二分查找,直到找到目标范围或到达叶子节点。这种设计有助于处理大量数据和大型文件系统,因为它能够有效地利用磁盘存储空间。
3. **B+树**:
B+树是一种变体,所有叶子节点都在同一层,且内部节点只存储关键字而不存储实际数据。这使得B+树非常适合用于文件系统,因为查找操作几乎总是从叶子节点开始,而不需要回溯到根节点。插入和删除操作可能导致部分数据移动,但整体性能优良。
4. **B*树++**:
这种术语不太常见,可能是B+树的一个特定变种或改进版本。B*树++可能指代一种优化过的B+树,增加了某些特性以提高效率,比如更复杂的平衡策略或优化的节点设计,但具体细节需要进一步的文档分析。
5. **R-tree**:
R-tree 是一种特别适合空间数据(如地理信息系统)的树结构,用于高效地索引多维空间对象。每个节点代表一个空间区域,而不是关键字集合。R-tree强调的是根据空间位置关系来组织数据,这对于处理多边形、多边线和点等几何对象的查询非常有效。
总结来说,这些数据结构都是为了在不同的场景下提供高效的数据存储和检索。选择哪种树取决于应用的需求,例如对内存访问的效率、数据的大小、更新频率等因素。理解这些树的特性及其优化方法对于数据库和文件系统的开发者至关重要。
下载后可阅读完整内容,剩余9页未读,立即下载
2022-09-24 上传
2021-11-26 上传
2023-06-03 上传
2021-06-24 上传
2019-04-17 上传
2021-07-10 上传
2021-06-21 上传
2012-09-27 上传
2020-08-05 上传

小小哭包
- 粉丝: 2085
- 资源: 4286
 我的内容管理
展开
我的内容管理
展开







最新资源
- AIPipeline-2019.9.12.19.11.34-py3-none-any.whl.zip
- PHP to Excel-开源
- azure-webjobs-demo:Azure WebJobs 演示
- Algoritme-og-UP-projekt
- budgeteer-ws
- 机器学习
- OCCIBIP-Studio:OCCIware和JavaBIP的集成
- ExamService-Backend
- AISTLAB_novel_downloader-1.0.0-py2.py3-none-any.whl.zip
- 含多种窗体元素的VC++演示对话框
- typings-suitescript-2.0:SuiteScript 2.0版的TypeScript类型
- ocean_game
- OpenCV工作展示一个隐层感知器NN训练有HSV强度值的特征:OpenCV工作展示一个隐层感知器NN训练有HSV强度值作为分割水像素的特征向量来自水下图像中的非水像素
- socketio-netty:从 code.google.compsocketio-netty 自动导出
- AIJIdevtools-1.4.2-py3-none-any.whl.zip
- e-library-开源
