H.264/Cabac:基于上下文的自适应二进制算术编码详解
版权申诉
129 浏览量
更新于2024-07-06
收藏 1.16MB PDF 举报
"CABAC (Context-Based Adaptive Binary Arithmetic Coding in H.264/AVC) 是一种高效的熵编码技术,用于H.264标准中的视频压缩。它属于基于上下文的自适应编码方法,旨在根据源数据的概率分布动态调整码字长度,从而接近信息熵的最大效率。相比于传统的Huffman编码,当信源概率分布均匀时,CABAC的编码性能更优。
1. **算术编码基础**:
- 算术编码是一种变字长编码,利用符号的概率信息进行编码,概率大的符号使用较短码字,小的概率使用较长码字。它不同于Huffman编码,后者使用整数长度码字,而算术编码则不局限于整数,能更好地适应概率分布。
- 通过将概率表示为[0,1]区间,区间宽度反映概率值大小。符号的概率区间通常是半开区间,如S1对应[0,0.001),S2对应[0.001,0.01),编码结果是一个指向概率区间的二进制指针。
2. **编码过程**:
- 编码开始时,编码点C=0,区间宽度A=1.0。对于每个符号,计算新编码点C=C+原区间A×Pi,并更新新区间A=原区间A×pi,其中Pi是当前符号的概率。
- 例如,序列3324SSSS中的第一个S3对应第3个子区间,输出的初始码字是.011。后续编码会在上一个编码指向的子区间内继续,如.011变为.1001,然后对S2进行编码,划分出更小的区间。
3. **实际应用与参考资料**:
- CABAC的实现方式通常参考开源项目,如JavaScript Video Media Source Extensions (JSVM) 和 JM解码器,它们提供了具体的编码和解码实现细节,有助于理解和掌握CABAC的工作原理。
总结来说,CABAC是一种高效的信息熵编码策略,通过上下文敏感和自适应的方式,减少了冗余,提高了视频压缩的效率。理解算术编码的基本原理和编码过程,以及如何结合实际的编码实现,对于从事视频编码和处理的开发者来说至关重要。"
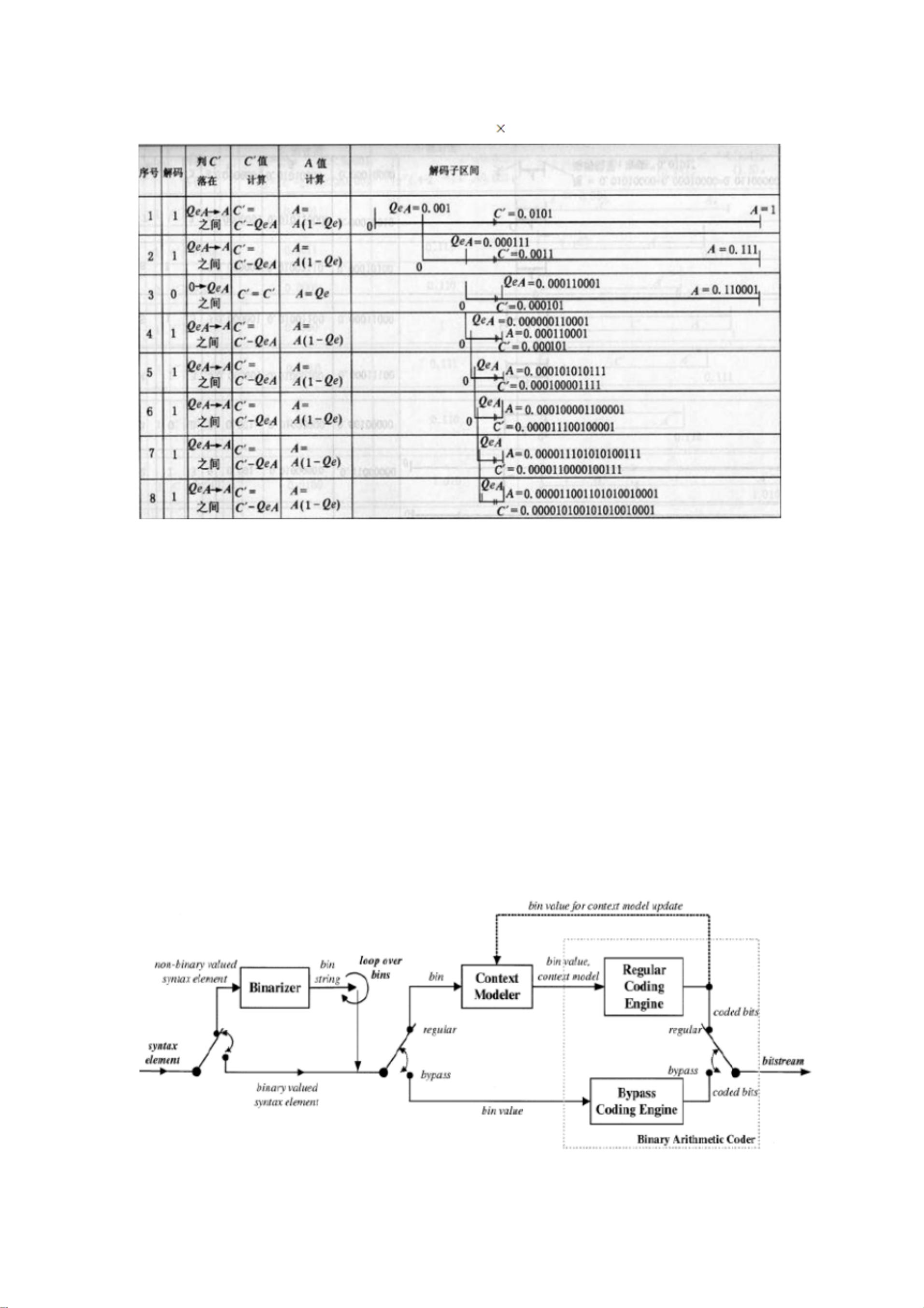
c’ = c ’ = 0.000101 A = AQe = 0.110001 0.001 = 0.000110001
三,CABAC 原理及其实现
CABAC 是 H264 的一种熵编码方案,相比如 H264 的另外一种熵编码方案
CAVLC 而言,在可接受的视频质量( 30dB 到 38dB 之间)内变化时,前者可节
约平均 9%到 14%的码流。 CABAC 有以下几个特性:
1,对多数符号使用了自适应概率模型。
2,通过使用上下文关系,利用了符号相关性。
3,限制为二进制算术编码( binary arithmetic coding),基于只用查表和移位方式
的快速二进制算术编解码器。
4,399 种预定义的上下文模型,分成了各种不同的模型组,例如模型 14-20 用
于帧间宏块类型的编码, 模型的选择基于前面编码的信息 (上下文关系),每
个上下文模型适应实验分布。
先大致介绍 CABAC 的实现过程,然后对一些技术做细节介绍
下面是 CABAC 的编码流程图
按上图可知,对一个符号编码有如下过程:
剩余16页未读,继续阅读
2011-10-17 上传
2021-07-26 上传
2011-11-17 上传
2021-07-13 上传
2012-07-30 上传
2019-08-16 上传
2021-11-26 上传
2021-11-19 上传

m0_63721911
- 粉丝: 0
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- mueblesKandra
- The Tale Trade Ext-crx插件
- IS-95A CDMA功率控制:IS-95A CDMA功率控制-matlab开发
- graphql-on-rails-auth-docs:Rails Auth系统文档上的GraphQL
- 点文件
- DynamicDecals:Unity内置渲染管线的贴花解决方案
- libeXosip2-3.6.0,c语言之贪吃蛇源码,c语言
- IEEE 802.11a WLAN 模型:IEEE 802.11a WLAN 物理层模型,带有自适应调制和编码的演示。-matlab开发
- choiiis.github.io
- bugexte:“ bugis应用程序的访问部分!”
- openssh9.6p1 for openeuler2203LTS
- tendalgo-search-engine
- frontend-project-lvl1
- 安卓全能工具箱v8.2.2.1 专业版.txt打包整理.zip
- music
- ClickUrl,字符动画c语言源码,c语言
