深度学习入门:MNIST手写数字识别
需积分: 12 9 浏览量
更新于2024-07-16
收藏 13.96MB DOCX 举报
"《深度学习与Python笔记本》中文版提供了深度学习代码的实现及中文解释,专注于帮助初学者理解人工智能的代码解析。文档通过MNIST手写数字识别问题介绍了神经网络的基本概念和Keras库的使用。"
在深度学习领域,神经网络是一个核心概念,它们模拟人脑神经元的工作方式,通过学习数据中的模式来执行各种任务。在本节中,作者以MNIST手写数字识别为例,介绍了如何使用Keras这个Python库来构建和训练神经网络模型。
MNIST数据库是机器学习领域的一个基准,它包含60,000个训练样本和10,000个测试样本,每张图片都是28x28像素的灰度图像,代表0到9的数字。在Keras中,可以轻松加载这些数据,它们被组织成NumPy数组,其中`train_images`和`train_labels`用于训练,`test_images`和`test_labels`用于验证模型的性能。
`train_images.shape`返回`(60000, 28, 28)`,表示60,000个图像,每个图像有28行和28列。`len(train_labels)`显示训练标签的数量,即60,000。同样,`test_images.shape`为`(10000, 28, 28)`,`len(test_labels)`为10,000,对应测试集的图像和标签。
神经网络的构建通常涉及将多个层串联起来,每个层负责从输入数据中提取特定的特征。在这个例子中,层会逐渐学习识别图像中的形状和结构,这些特征对于识别手写数字至关重要。通过连接多层,网络可以逐步提升对数据的理解,实现复杂的模式识别。
在Keras中,创建一个简单的神经网络模型可能包括以下步骤:
1. 导入所需的库,如`keras.datasets`中的`mnist`。
2. 加载MNIST数据并进行预处理,如归一化或缩放。
3. 定义模型结构,包括输入层、隐藏层和输出层。每一层都可以配置不同的激活函数、节点数量等参数。
4. 编译模型,指定损失函数(如交叉熵)和优化器(如随机梯度下降)。
5. 训练模型,使用`model.fit()`方法,传入训练数据和对应的标签。
6. 预测测试数据,使用`model.predict()`,并将预测结果与`test_labels`对比以评估模型性能。
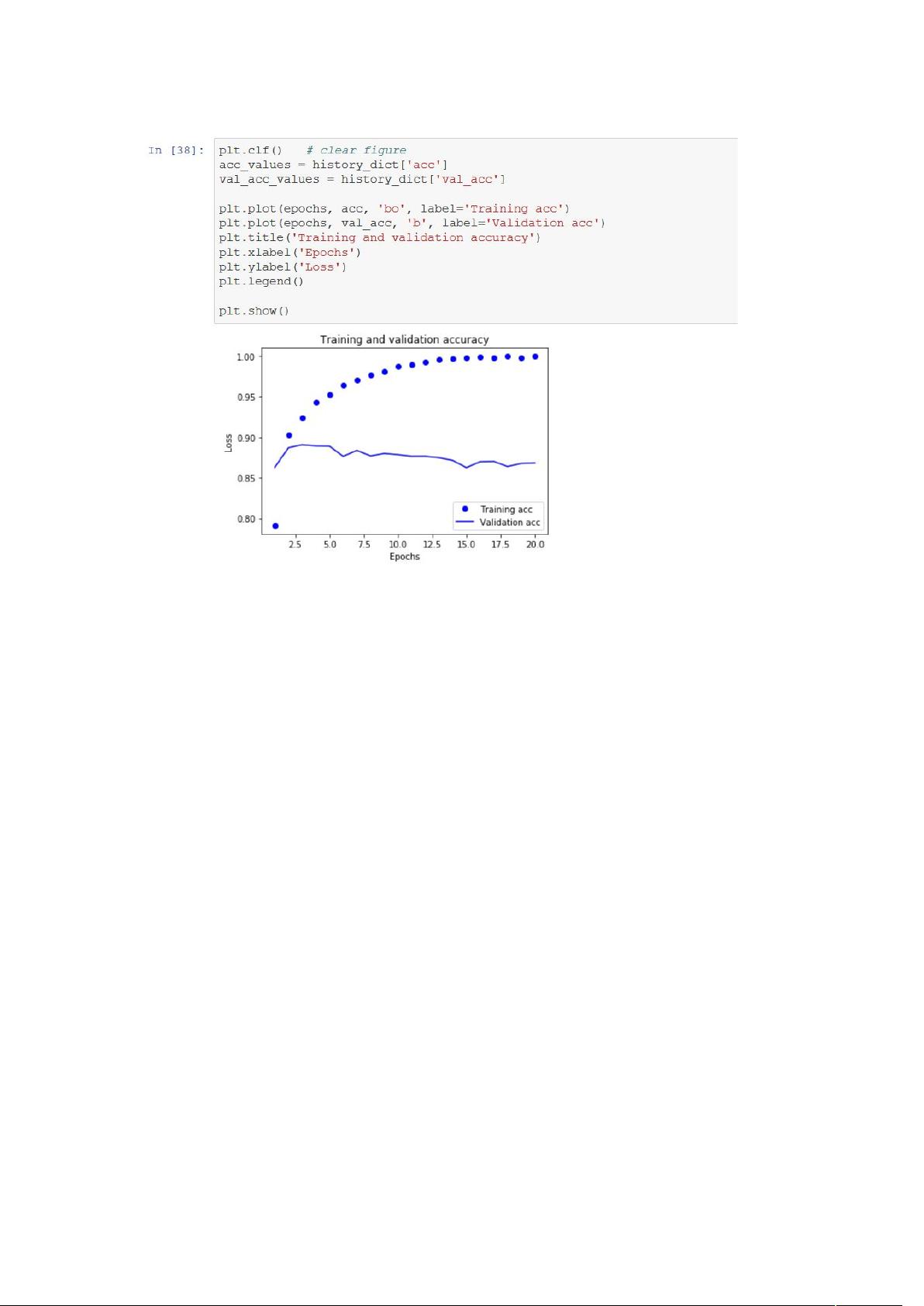
这个过程体现了深度学习的基本流程,即构建、训练和验证模型。通过不断迭代和调整网络结构,可以优化模型的性能,提高对MNIST数据集的识别准确率。对这个例子的理解是深入学习入门的基础,后续章节会逐步深入到更复杂和实际的应用场景。

!" !2
2"!$" !!3*" !!3I""$*)'
*(!#%2# "'
!2*+ !2(!#%222.)
验证我们的方法
为了在训练过程中监控模型对于以前从未见过的数据的准确性,我们将创建一个“验证
集”,方法是从原始训练数据中分离出 ' 个样本:
0%=*0% !#+E.
" !%0% !#*0% !#+E.
%=*% !#+E.
" !%% !#*% !#+E.
我们现在将以 , 个样本的小批量训练我们的模型 个周期(对所有样本 0% !#
和 % !# 张量中的 次迭代)。与此同时,我们将监测我们设置的 ' 个样品的损
失和准确性。这是通过将验证数据作为 =! !#% 参数传递完成的:
! *G $" !%0% !#'
" !%% !#'
"2*'
( 2%!3*,'
=! !#% *$0%='%=))

剩余63页未读,继续阅读
270 浏览量
487 浏览量
2024-02-21 上传
2022-07-15 上传
272 浏览量
2021-03-13 上传
2021-03-14 上传

purewater
- 粉丝: 14
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript-Projects
- 蜡笔::crayon:Crayons-一个UI套件,其中包括用于构建Freshworks Apps的Web组件!
- 卷积码编译码matlab仿真.zip
- mqemitter-redis:由Redis驱动的MQEmitter
- mlive:用于通过高容量网络重定向实时媒体的分布式服务器-开源
- curso-javascript-node-i:脚本编程节点
- 【Java毕业设计】使用 Go 语言实现内容管理系统,该系统聚集博客、云盘、社区、论坛、问答等子系统。希望该项目对你.zip
- 流
- 华为rpa 多excel自动汇总机器人
- MiniCore:这是有关flex RSL的微型核心。-开源
- 辞郁报表设计器(2021-06-18)
- 真棒聚合物:真棒聚合物资源的集合
- recipe_book:一个大学生每次做饭都要给妈妈打电话的食谱书
- DataGridView中的RichTextBox单元格
- bank_app_neomorphism_flutter
- 最终项目
