2022年Python爬虫实战指南:从基础到分布式
版权申诉
"这篇资源是2022年关于Python爬虫的一份全面总结,包含了从基础到进阶的各种知识点,由拥有6年爬虫经验的专家精心整理。内容涵盖Python环境搭建、基本库的使用、Scrapy框架的应用以及应对反爬策略,还涉及到了手机APP爬虫的技巧。"
在Python爬虫的世界里,本文首先介绍了Python环境的搭建,推荐使用Anaconda来管理Python环境,因为它自带了许多数据科学常用的库,方便进行数据分析和爬虫开发。Selenium的安装和使用也至关重要,它能够模拟真实用户的行为,尤其在处理动态加载页面时非常有用,需要配合对应的浏览器驱动,如Chrome的chromedriver。
接着,文章深入讲解了Python爬虫的基本库,包括urllib、requests、BeautifulSoup(bs4)、xpath和lxml、selenium以及PyQuery。urllib和requests库用于发送HTTP请求,获取网页内容,而BeautifulSoup和lxml则用于解析HTML文档,提取所需数据。Selenium能够执行更复杂的交互任务,PyQuery则提供了一个类似于jQuery的API来处理XML和HTML文档。
Scrapy是一个强大的爬虫框架,提供了更高效、结构化的爬取流程,支持分布式爬虫。Scrapy-Redis则是Scrapy的一个扩展,允许通过Redis来协调多个Scrapy爬虫进程,实现数据的分布式处理,提高了爬虫的并发能力和数据处理速度。
面对网站的反爬机制,文章提到了一些应对策略,比如使用代理IP来避免IP被封禁,这是因为在大量请求时,同一个IP过于频繁访问同一网站可能被识别为爬虫并遭到封锁。此外,对于需要登录的网站,爬虫需要模拟登录过程,通常涉及到cookie和session的管理。
最后,文章触及了移动应用的爬取,这是一个相对复杂且技术含量高的领域。需要掌握模拟器的使用,如蓝叠(Bluestacks)等,以及抓包工具如Fiddler、mitmproxy,它们可以帮助分析和拦截APP的数据通信。此外,利用Appium进行移动端的自动化控制,以及通过apk脱壳反编译来理解APP的数据请求方式,是进行APP爬虫的关键步骤。
这份资料全面覆盖了Python爬虫的各个层面,从基础知识到高级技巧,对于想要系统学习和提升爬虫技能的读者来说是一份宝贵的资源。
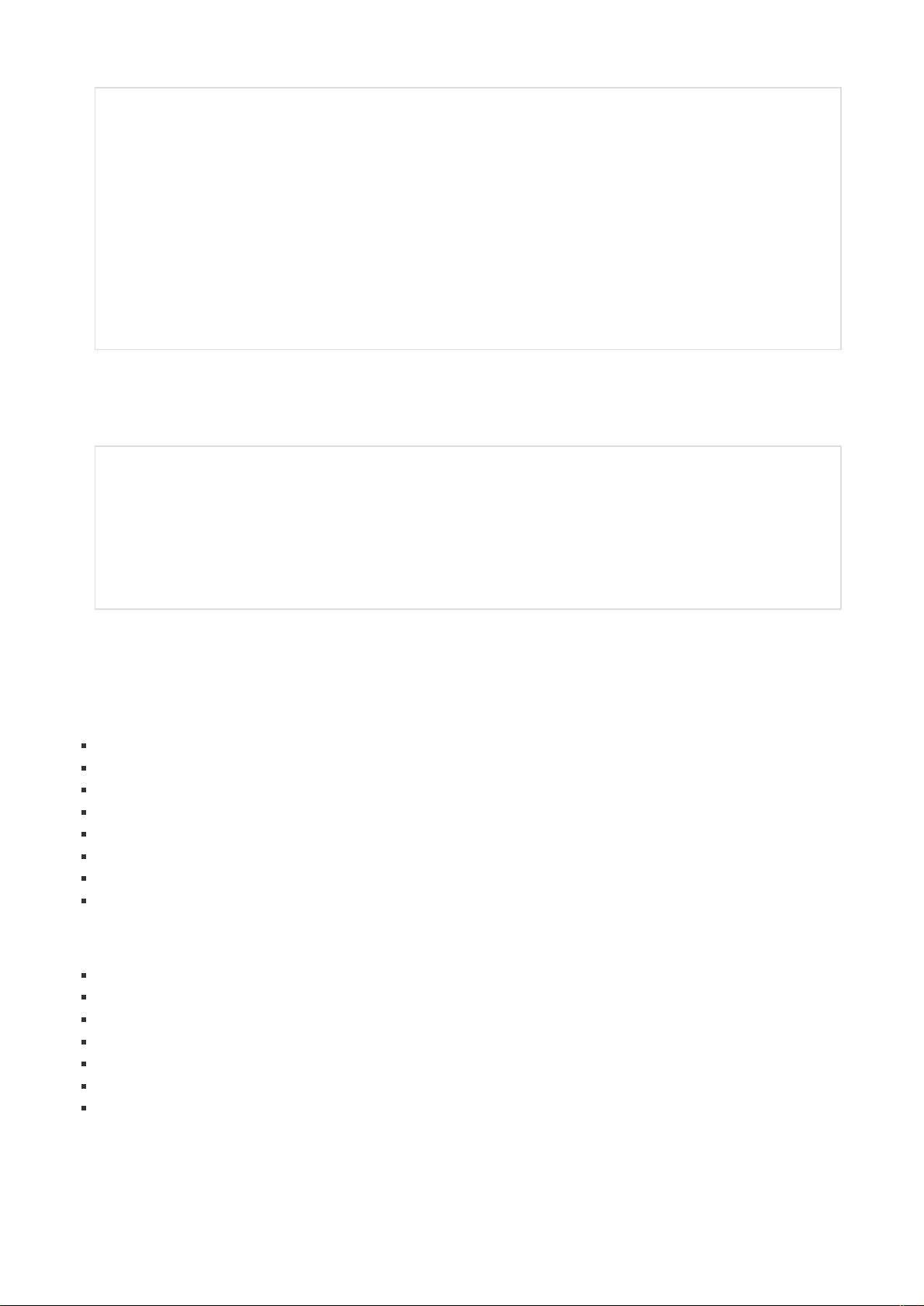
它可以根据索引来选择,可以根据值来选择,可以根据文字来选择,十分方便。
Cookies处理:
2.6.2 元素选取
单个元素选取:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
多个元素选取:
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
2.6.3 页面等待
from selenium.webdriver.support.ui import Select
select = Select(driver.find_element_by_name('name'))
select.select_by_index(index)
select.select_by_visible_text("text")
select.select_by_value(value)
# 全部取消选择
select = Select(driver.find_element_by_id('id'))
select.deselect_all()
# 获取所有的已选选项
select = Select(driver.find_element_by_xpath("xpath"))
all_selected_options = select.all_selected_options
# 为页面添加Cookies
driver.get("http://www.example.com")
cookie = {'name': 'foo', 'value': 'bar'}
driver.add_cookie(cookie)
# 获取页面Cookies,用法如下
driver.get("http://www.example.com")
driver.get_cookies()
剩余68页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-02-23 上传
338 浏览量
2024-05-30 上传
2024-03-05 上传
2022-03-22 上传
2021-09-11 上传

大数据技术派
- 粉丝: 1862
- 资源: 20
 我的内容管理
展开
我的内容管理
展开







