电商全文检索:Solr与IK集成Tomcat实践教程
需积分: 9 130 浏览量
更新于2024-07-19
收藏 1.57MB DOC 举报
Solr是一个强大的全文检索服务器,它结合了Lucene全文检索工具包的功能,专为满足大规模、高性能的搜索需求而设计。在电商项目中,Solr与IK(Apache Lucene中文分词器)的集成使得文本内容的处理更为高效,能够实现对文档内容的精确搜索和分析。
首先,Solr的核心任务是接收文档,对其进行分析(包括分词),然后创建索引。在Solr中,文档被表示为Document对象,它可以包含自定义的域(Field),如StringField、TextField、LongField或StoreField,这些域可以有不同的设置,比如是否需要进行分词、索引以及是否保存。对于索引操作,Solr支持增删改查的基本操作:
1. 增加文档:通过`Document`对象构建新的文档,并使用`indexWriter`添加到索引中。
2. 删除文档:通过`indexWriter`的`deleteDocument()`方法,根据文档ID删除已存在的文档。
3. 修改文档:如果需要更新现有文档,通常会先删除再添加,以确保一致性。
4. 查询:使用`IndexSearcher`和`IndexReader`执行搜索。查询语句可以基于TermQuery(精确匹配特定字段值)、`MatchAllDocQuery`(查询所有文档)、`NumericRangeQuery`(数值范围查询)、`BooleanQuery`(组合查询,如AND、OR、NOT)或者通过`QueryParser`解析复杂的查询字符串。例如,`parser.parse("content:spring OR java")`会先将查询字符串分词,生成`Query`对象,以便根据分词后的结果进行搜索。
IK分词器在Solr中的应用至关重要,因为它负责将用户的输入转换为索引可以理解的词元(Term),这在处理中文等非英文语言时尤为关键。在Solr配置中,可以指定使用IKAnalyzer进行中文文本的分析。
虽然Lucene是一个强大的底层工具,但它需要更多的开发工作,包括搜索优化、索引库管理和集群设置。这使得Lucene更适合那些对性能有极高要求且愿意投入更多精力进行自定义开发的场景。相比之下,Solr作为一个成熟的全文检索服务器,提供了现成的配置和优化方案,包括支持多种查询语法、大小写不敏感、分词算法等特性,非常适合快速搭建并部署站内搜索功能,特别是对于商业应用和项目而言,推荐优先选择Solr。
Solr+IK分词集成Tomcat实现在电商项目中的全文检索,简化了开发流程,提高了搜索效率,使得开发者能够专注于业务逻辑,而不必过多关注底层的搜索引擎实现细节。因此,选择Solr作为电商项目全文检索的解决方案,是一个明智且高效的决策。

solrconfig.xml:
Lib:配置了索引库的扩展 jar 包的位置。默认是 collection1\lib 文件夹,如果没有就创建
一个。
dataDir:索引库存放的目录。默认是 collection1\data 文件夹,如果没有 solr 启动后会
自 requestHandler:配置了 solr 对外提供服务的 url。
查询索引使用的 url:
维护索引时使用的 url:
defaultQuery:默认的查询语法
可以根据实际情况对 solrconfig.xml 进行配置,如果使用默认配置可以不修改此配置文件。
第六步:打开 tomcat 下的 wenapps 下 solr 工程下的 WEB-INF 下的 web.xml 文件告诉 solr 服
务器 solrhome 存放的位置。修改 solr 工程的 web.xml 文件的路径
第七步:启动 tomcat
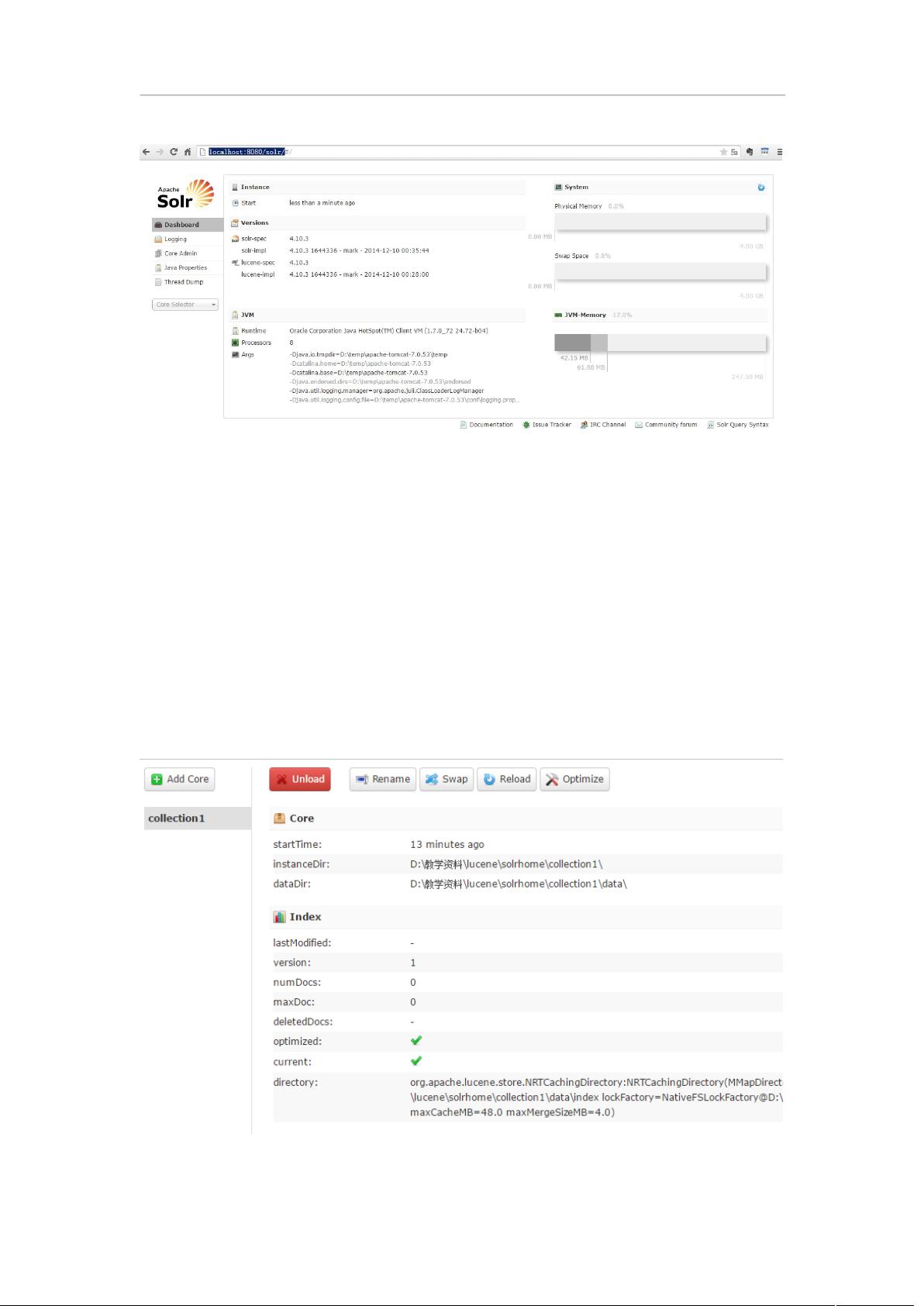
第八步:访问 http://localhost:8080/solr/
剩余35页未读,继续阅读
223 浏览量
141 浏览量
117 浏览量
2016-10-24 上传
108 浏览量
2019-09-17 上传
105 浏览量
174 浏览量

PasserBy*_*
- 粉丝: 72
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- jungle-rails:丛林项目
- piazza-api:Piazza内部API的非官方客户端
- hadoopstu.7z
- 2014学校德育工作年度计划
- matlab的slam代码-openslam_cekfslam:来自OpenSLAM.org的cekfslam存储库
- Zendi-crx插件
- svg.path:SVG路径对象和解析器
- 朱宏林.github.io
- Fivlytics - Fiverr Seller Assistant-crx插件
- 基于代码变更分析的过时需求识别
- tomcat windwos 7\8
- Hot-Restaurant-App
- VB.net 2010 读写txt文件
- pcdoctor
- java版sm4源码-spring-security-family:关于如何在微服务系统中使用spring-security的demo&分享
- iiam:IIAM App正在开发中!
