Hadoop分布式文件系统(HDFS)详解:容错性与高吞吐量
需积分: 0 95 浏览量
更新于2024-07-01
收藏 864KB PDF 举报
"本文介绍了Hadoop分布式文件系统(HDFS)的基本概念、特点以及其架构组成,同时探讨了HDFS的容错机制和数据压缩算法。"
HDFS,全称为Hadoop Distributed File System,是一种专为大数据处理设计的分布式文件系统。它能够在由普通硬件组成的集群上运行,提供高容错性和高吞吐量的数据访问。HDFS的设计目标之一是应对机器故障,通过错误检测和快速恢复机制确保系统的稳定运行。文件系统中,数据分散存储在各个Datanode上,当某个节点故障时,系统能够自动检测并恢复数据,确保服务的连续性。
HDFS的一个显著特点是支持流式数据访问,这使得它非常适合大规模数据集的应用,如大数据分析和处理。文件的大小通常非常大,以G或T为单位,最小分配单位为64M,并且文件总大小必须是这个单位的整数倍。此外,HDFS采用一次写入、多次读取的一致性模型,简化了数据管理,增强了读取效率。
HDFS架构主要由Namenode和Datanode构成。Namenode负责元数据管理,包括文件系统的命名空间和文件位置信息。Datanode则负责实际的数据存储,它们通常分布在多台运行Linux操作系统的机器上。Java语言的使用使得HDFS具有良好的跨平台性,可以轻松部署在各种硬件环境中。一个集群通常有一个Namenode,多个Datanode,但也可以根据需求在同一台机器上运行多个Datanode。
在数据压缩方面,HDFS支持两种类型的压缩:可拆分和不可拆分。可拆分的压缩算法允许在不完全解压整个文件的情况下,对数据块进行局部处理,提高了处理效率。不可拆分的压缩算法则需要先完全解压,然后进行处理,适合对完整文件进行一次性处理的场景。
HDFS是为处理大规模数据而生的分布式文件系统,它的设计原则是高可用性、高吞吐量和低成本,通过巧妙的架构设计和数据处理策略,实现了在普通硬件上的高效大数据存储和处理。
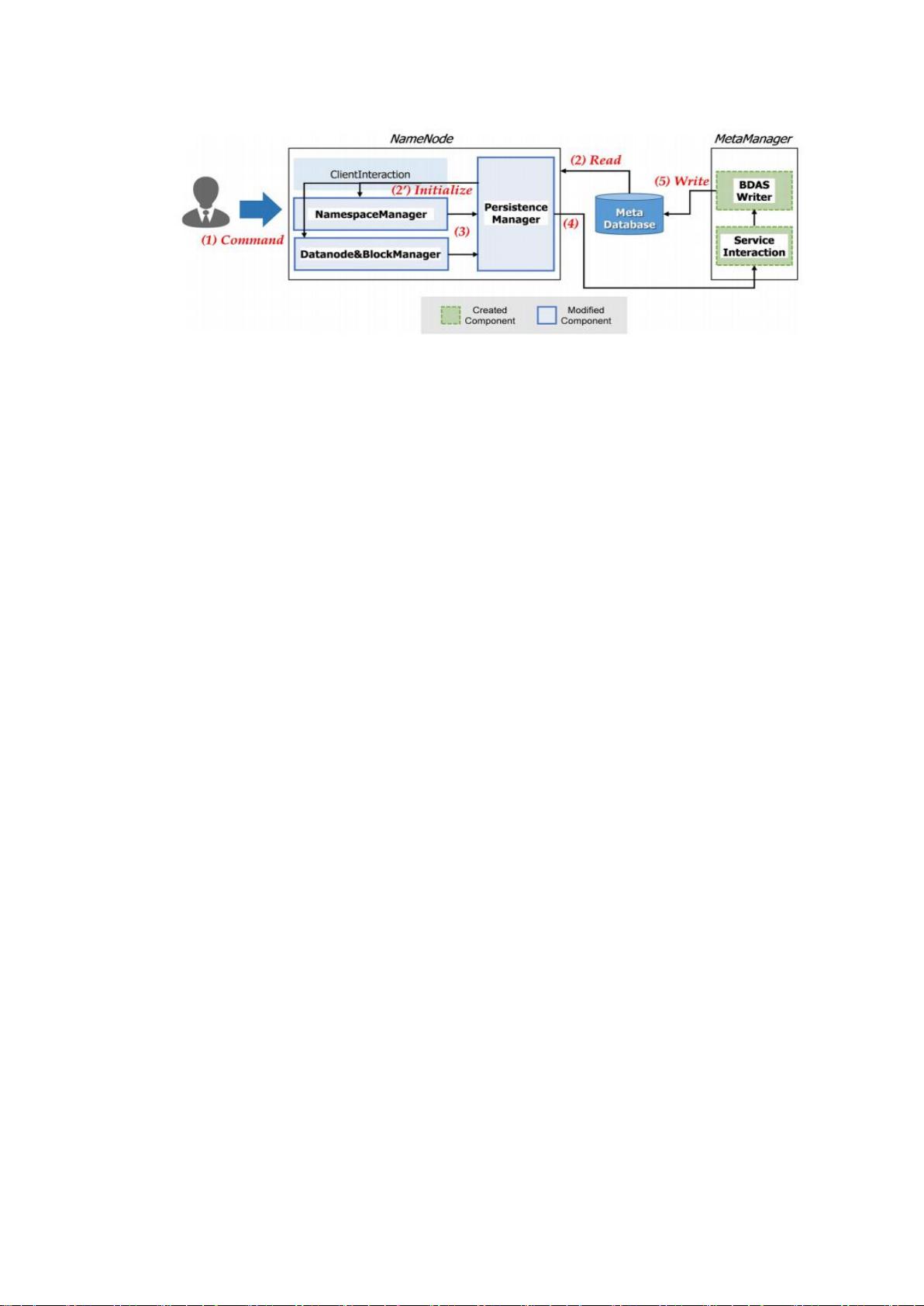
由于改进 HDFS 系统仅加载重要信息来减少 HDFS 启动时间,因此对系统效率的提高还是有显著的
影响的。
HDFS 改进方案 2:众所周知,HDFS 是针对大文件存储,因此我们提出了一中分布式缓存方案
来存储 HDFS 中的小文件。该方案大致方法为,通过在一个块中组合和存储多个小文件的方式来减
少要在 NameNode 中管理的元数据的数量。 除此以外,它通过使用客户端缓存和 DataNode 缓存
来维护有关请求文件的信息,并且同步客户端缓存的元数据,减少不必要的访问时间。客户端用来缓
存维护用户请求的小文件和元数据,每个 DataNode 缓存维护用户经常请求的小文件信息。HDFS
小文件的应用场景为小文件但数量多的情况。现有的 HDFS 对于小文件的读取是使用单个缓存,因
此它没有办法维护大量的元数据和小文件。如果我们使用多个 datanode 缓存就可能解决这一问题。
这样就形成了一个分布式的缓存系统,它可以缩短小文件的缓存时间。因此,我们可以一下一种方案:
应用缓存元数据来提高 HDFS 中访问多媒体小文件性能的分布式缓存方案。还有一种情况,针对
HDFS 存储大文件的特点, 即将小文件合并成大文件,减少 namenode 的负载,并使用预取方法
来提高访问性能。现根据以上两种情况,提出了扩展 HDFS 系统,即 EHDFS 系统。它和原有的 HDFS
的区别是它减少了 namenode 主内存中的元数据。所以方式为从单个大文件访问单个文件。如果文
件的元数据在客户端存储,就不向 namenode 发送请求信息了。考虑到相同目录的文件依赖性,我
们可以将同一个目录的文件进行合并。然后我们将小文件进行缓存。由于访问时间和次数会影响缓存
效率,因此开发了一种心得缓存策略:NRU-LFU。 HDFS 的缓存机制 HDCache 建立在 HDFS 的
顶部,由一个客户端库和多个缓存服务组成。 HDFS 会构建一个共享内存,它的加载文件会被缓存
在共享内存中,以供客户端库直接访问。 加载文件的到期时间可以由客户端自主设置。 如果超过了
到期时间,则会根据网络流量,系统工作负荷和文件访问频率来进行处理。NameNode 将元数据存
储在 DataNode 的内存中。 当 NameNode 内存已满时,它不会在群集中添加其他节点以满足进一
步的存储需求。那么的具体缓存方案是什么呢?即客户端缓存和 datanode 缓存同时进行,减少对
namenode 的通信,对 DataNode 缓存中维护的文件的缓存元数据进行额外管理。 当每个客户端
自然地调节与 NameNode 的通信周期并更新缓存元数据时,使用最新信息更新在客户端缓存中维护
的缓存元数据。缓存的体系结构由 hadoop 集群和访问该集群的客户端组成,同时包含块的元数据和
缓存元数据。每个 DataNode 缓存都维护用户请求的小文件。客户端缓存还维护用户请求的小文件,
块元数据和缓存元数据。因为我们需要块元数据来标识包含所请求的小文件的 block, 需要缓存元
数据来标识包含小文件的 DataNode。具体的结构如下图所示:
剩余15页未读,继续阅读
2021-01-20 上传
2021-01-07 上传
2021-01-20 上传
2022-08-08 上传
2022-08-08 上传
2021-09-15 上传
2013-08-25 上传
2018-11-15 上传
2020-09-09 上传

啊看看
- 粉丝: 37
- 资源: 323
 我的内容管理
展开
我的内容管理
展开







最新资源
- stm32学习代码.zip
- Python自动化神器-PyAutoGUI(1)
- 简历-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- torch_scatter-2.0.7-cp39-cp39-win_amd64whl.zip
- torch_cluster-1.5.9-cp39-cp39-win_amd64whl.zip
- torch_scatter-2.0.7-cp39-cp39-linux_x86_64whl.zip
- torch_cluster-1.5.9-cp39-cp39-linux_x86_64whl.zip
- torch_scatter-2.0.8-cp39-cp39-win_amd64whl.zip
- torch_scatter-2.0.7-cp38-cp38-win_amd64whl.zip
- torch_scatter-2.0.9-cp39-cp39-win_amd64whl.zip
- torch_cluster-1.5.9-cp38-cp38-win_amd64whl.zip
- torch_scatter-2.0.8-cp38-cp38-win_amd64whl.zip
- torch_scatter-2.0.7-cp38-cp38-linux_x86_64whl.zip
- torch_cluster-1.5.9-cp37-cp37m-win_amd64whl.zip
- torch_scatter-2.0.9-cp39-cp39-linux_x86_64whl.zip
- torch_scatter-2.0.7-cp37-cp37m-linux_x86_64whl.zip
