Java实现布隆过滤器详解
60 浏览量
更新于2024-09-02
收藏 541KB PDF 举报
"Java实现布隆过滤器的方法和原理,以及其在空间和时间效率上的优势。"
在软件开发中,布隆过滤器是一种高效的数据结构,用于判断一个元素是否可能存在于一个大型集合中,而不会产生误判。相较于传统的数据结构如哈希表,布隆过滤器在节省空间方面具有显著优势,但代价是可能存在一定的误判率。
布隆过滤器由Burton Bloom于1970年提出,它包含一个很长的二进制向量(通常是一个位数组)和若干个独立的哈希函数。这些哈希函数将元素映射到位数组的不同位置,将这些位置设置为1。当查询一个元素是否存在时,通过相同的哈希函数计算出位数组中的位置,如果所有对应位置都是1,则可能存在于集合中;如果存在0,则肯定不存在。由于可能会有多个元素映射到同一个位置,因此可能会出现误判,即判断一个实际上不存在的元素为存在。
在Java中实现布隆过滤器,可以使用BitSet类来创建位数组,并定义多个不同的哈希函数。以下是一个简单的Java布隆过滤器实现:
```java
import java.util.BitSet;
public class BloomFilter {
private BitSet bits;
private int hashFunctions;
public BloomFilter(int capacity, int hashFunctions) {
this.bits = new BitSet(capacity);
this.hashFunctions = hashFunctions;
}
public void add(Object item) {
for (int i = 0; i < hashFunctions; i++) {
bits.set(hash(item, i), true);
}
}
public boolean contains(Object item) {
for (int i = 0; i < hashFunctions; i++) {
if (!bits.get(hash(item, i))) {
return false;
}
}
return true;
}
// 自定义哈希函数
private int hash(Object item, int index) {
// 实现多个不同的哈希函数,例如使用物品的toString()值
int hashValue = item.toString().hashCode();
return hashValue * index % bits.size();
}
}
```
在这个例子中,`add`方法将元素添加到布隆过滤器中,`contains`方法检查元素是否存在。注意,为了实现多个哈希函数,`hash`方法需要进行适当的修改以确保不同的哈希值。实际应用中,可能需要使用更高效的哈希函数组合,例如MurmurHash或MD5。
在实际使用中,布隆过滤器特别适合于大数据场景,如Redis中存储大量唯一ID,或者防止垃圾邮件系统中重复检查同一邮箱地址等。然而,由于其误判特性,不适用于对精确性要求极高的应用。布隆过滤器是在空间效率和精确度之间做出权衡的有效工具。
Java实现布隆过滤器的方法步骤实现布隆过滤器的方法步骤
布隆过滤器是可以用于判断一个元素是不是在一个集合里,并且相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大
的优势。下面这篇文章主要给大家介绍了关于Java实现布隆过滤器的相关资料,需要的朋友可以参考下
前言前言
记得前段时间的文章么?redis使用位图法记录在线用户的状态,还是需要自己实现一个IM在线用户状态的记录,今天来讲讲另一方案,布隆
过滤器
布隆过滤器的作用是加快判定一个元素是否在集合中出现的方法。因为其主要是过滤掉了大部分元素间的精确匹配,故称为过滤器。
布隆过滤器布隆过滤器
在日常生活工作,我们会经常遇到这的场景,从一个Excel里面检索一个信息在不在Excel表中,还记得被CTRL+F支配的恐惧么,不扯了,软
件开发中,一般会使用散列表来实现,Hash Table也叫哈希表,哈希表的优点是快速准确,缺点是浪费储存空间,我们这个场景,储存登录
的userId到哈希表,当用户规模十分巨大的时候,哈希表的储存效率低的问题就显示出来了,今天介绍一种数学工具:布隆过滤器,它只需要
哈希表1/8到1/4的大小就能解决同样的问题。
背书中背书中
布隆过滤器(Bloom Filter)是由伯顿·布隆(Burton Bloom)于1970年提出来的,它实际上是一个很长的二进制向量和一系列随机映射函数。
原理原理
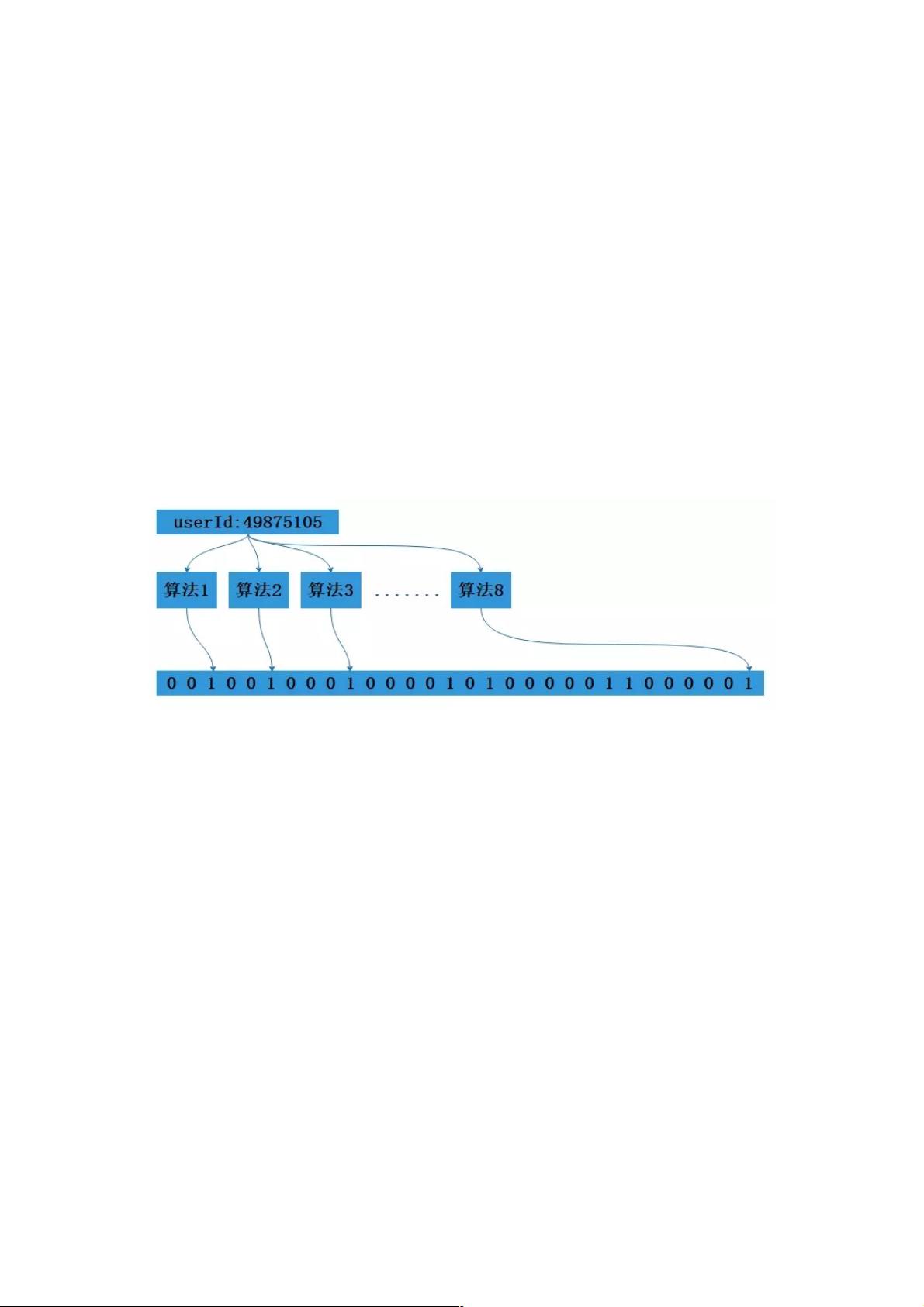
使用我们这个场景,来讲原理吧,假设我们的个人网站同时在线人数达到1亿(意淫一下),要存储这一亿人的在线状态,先构建一个16亿比
特位即两亿字节的向量,然后把这16亿个比特位都记为0。对于每一个登录用的userId,使用8个不同的算法产出8个不同信息指纹,在用一个
算法把这8个信息隐身到这16亿个比特位的8个位置上,把这8个位置都设置成1,这样就构建成了一个记录一亿用户在线状态的布隆过滤器。
1亿在线用户的布隆过滤器
检索就是同样的原理,使用相同的算法对要检索的userId产生8个信息指纹,然后在看这八个信息指纹在这16亿比特位对应的值是否为1,都为
1就说明这个userId在线,下面就用java代码来实现一个布隆过滤器。
Java实现布隆过滤器实现布隆过滤器
先实现一个简单的布隆过滤器
package edu.se;
import java.util.BitSet;
/**
* @author ZhaoWeinan
* @date 2018/10/28
* @description
*/
public class BloomFileter {
//使用加法hash算法,所以定义了一个8个元素的质数数组
private static final int[] primes = new int[]{2, 3, 5, 7, 11, 13, 17, 19};
//用八个不同的质数,相当于构建8个不同算法
private Hash[] hashList = new Hash[primes.length];
//创建一个长度为10亿的比特位
private BitSet bits = new BitSet(256 << 22);
public BloomFileter() {
for (int i = 0; i < primes.length; i++) {
//使用8个质数,创建八种算法
hashList[i] = new Hash(primes[i]);
}
}
//添加元素
public void add(String value) {
for (Hash f : hashList) {
//算出8个信息指纹,对应到2的32次方个比特位上
bits.set(f.hash(value), true);
}
下载后可阅读完整内容,剩余3页未读,立即下载
2017-04-30 上传
2012-06-29 上传
2021-01-30 上传
2020-09-01 上传
2021-05-11 上传
2024-03-23 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38723683
- 粉丝: 6
- 资源: 908
 我的内容管理
展开
我的内容管理
展开







