MapReduce编程模型:简化海量数据处理
需积分: 0 5 浏览量
更新于2024-06-30
收藏 307KB DOCX 举报
"MapReduce是一种编程模型,由Google提出,用于处理和生成大规模数据集。它简化了在分布式计算环境中编写处理程序的复杂性,使程序员可以专注于业务逻辑,而无需深入了解并行处理和分布式系统的底层细节。MapReduce的核心包括Map(映射)和Reduce(归约)两个阶段,以及在分布式集群上处理数据的框架。
Map阶段接收输入数据,将其划分为键值对,并应用用户定义的Map函数,生成中间结果。这个过程是并行化的,每个Map任务可以在集群的不同节点上独立执行。中间结果通常包含相同的键和与之相关的值列表。
Reduce阶段则负责聚合Map阶段产生的中间键值对。通过用户定义的Reduce函数,将所有具有相同键的中间值合并成单个或少量的值。这一阶段同样支持并行处理,不同 Reduce 任务可以并行处理不同的键组。
MapReduce架构在设计时考虑了以下几个关键点:
1. 数据分割:输入数据被自动分割成多个块,每个块由一个Map任务处理。
2. 调度和分布:系统自动决定哪些任务在哪个节点上执行,以及如何在集群间分发数据。
3. 错误处理:MapReduce能够检测并自动处理节点故障,确保任务的可靠性。
4. 通信管理:处理节点间的通信,包括中间结果的传递和最终结果的整合。
这种模型在Google内部广泛应用,处理各种任务,如文档抓取、Web请求日志分析、构建倒排索引等。程序员发现MapReduce易于使用且高效,因为它允许他们专注于编写业务逻辑,而不用操心分布式系统的复杂性。在Google的集群中,MapReduce程序经常涉及数千台机器,处理以TB为单位的海量数据,每天有数千个MapReduce作业在运行。
MapReduce的设计灵感来源于Lisp语言和其他函数式编程概念,其目的是通过抽象和自动化,降低处理大数据的复杂性和门槛。通过这种模型,程序员可以专注于实现特定的Map和Reduce函数,而复杂的分布式计算问题则交由MapReduce库来处理。这种方法极大地提高了开发效率,使得更多程序员能够利用分布式系统的计算能力。"
则适用于大型 NUMA 架构的多处理器的主机,而有的实现方式更适合大型的网
络连接集群。
本章节描述一个适用于 Google 内部广泛使用的运算环境的实现:用以太网
交换机连接、由普通 PC 机组成的大型集群。在我们的环境里包括:
1.x86 架构、运行 Linux 操作系统、双处理器、2-4GB 内存的机器。
2.普通的网络硬件设备,每个机器的带宽为百兆或者千兆,但是远小于网络
的平均带宽的一半。 (alex 注:这里需要网络专家解释一下了)
3.集群中包含成百上千的机器,因此,机器故障是常态。
4.存储为廉价的内置 IDE 硬盘。一个内部分布式文件系统用来管理存储在这
些磁盘上的数据。文件系统通过数据复制来在不可靠的硬件上保证数据的可靠性
和有效性。
5.用户提交工作(job)给调度系统。每个工作(job)都包含一系列的任务
(task),调度系统将这些任务调度到集群中多台可用的机器上。
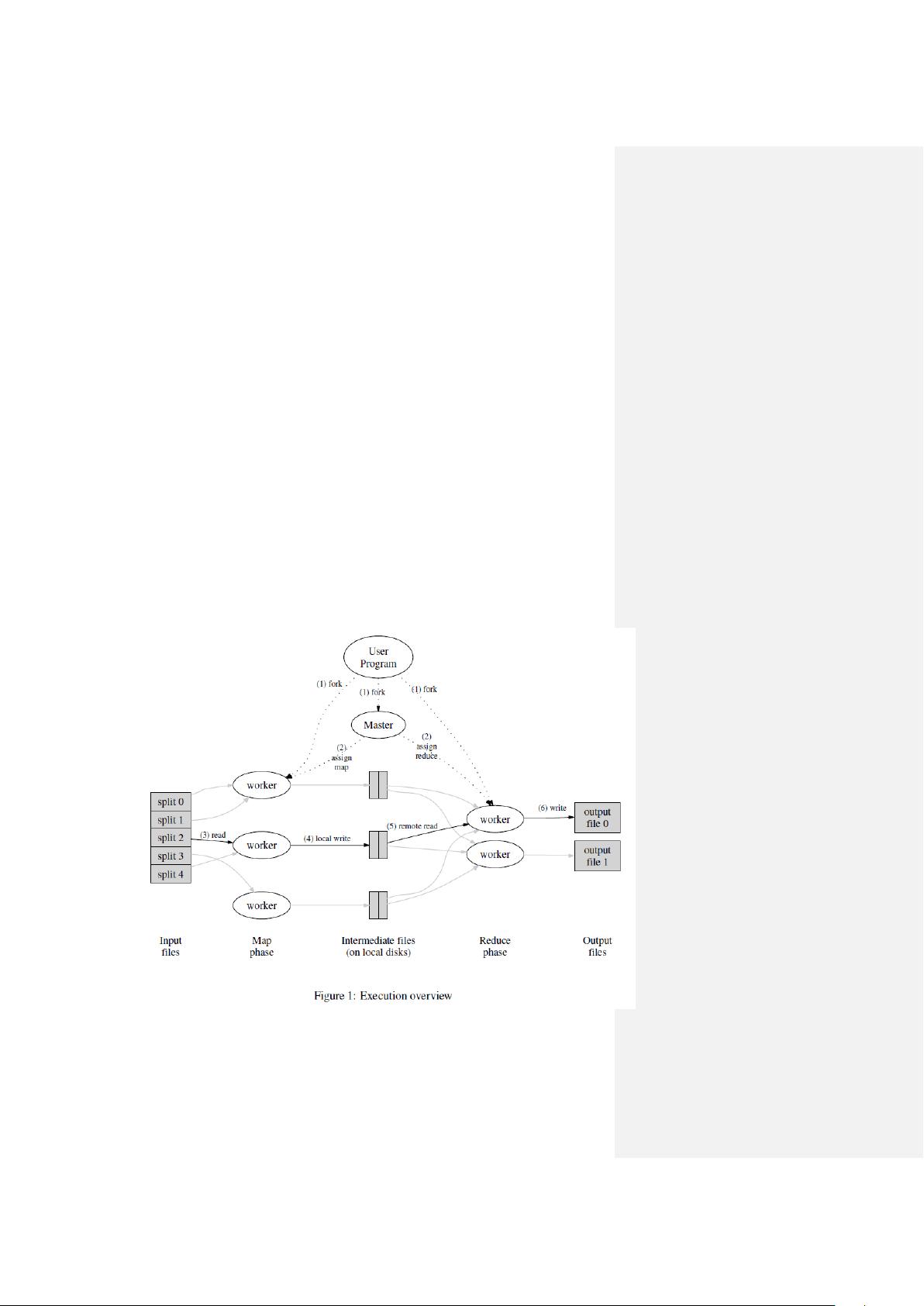
执行概括
通过将 Map 调用的输入数据自动分割为 M 个数据片段的集合,Map 调用被
分布到多台机器上执行。输入的数据片段能够在不同的机器上并行处理。使用分
区函数将 Map 调用产生的中间 key 值分成 R 个不同分区(例如,hash(key) mod
R),Reduce 调用也被分布到多台机器上执行。分区数量(R)和分区函数由用
户来指定。
图 1 展示了的 MapReduce 实现中操作的全部流程。当用户调用 MapReduce
函数时,将发生下面的一系列动作(下面的序号和图 1 中的序号一一对应):
剩余16页未读,继续阅读
2011-03-07 上传
2022-08-08 上传
2011-02-16 上传
2022-08-08 上传
2021-06-20 上传
2021-06-14 上传
2018-11-22 上传
2011-11-19 上传

KerstinTongxi
- 粉丝: 25
- 资源: 277
 我的内容管理
展开
我的内容管理
展开







最新资源
- bookers2-favorite_comment
- UMI.CMS Debugging Tool-crx插件
- 毕业设计&课设-基于MATLAB的IEEE 802.11p物理层仿真模型.zip
- yak:又一位收藏经理
- rubiks:魔方解集上的蛮力研究
- Koffee:Java字节码汇编程序作为Kotlin DSL
- os:小型操作系统
- HTML5 Canvas生成粒子效果的人物头像html5-canvas-pixel-image-master.zip
- mona:mona.py 的 Corelan 存储库
- QQ群管理-crx插件
- 毕业设计&课设-滑动传递分析工具箱和GUI(Matlab).zip
- ece3552-faceRecognition:ECE 3552的最终项目。人脸识别签到设备
- polaroidz
- MIT-JOS:6.828:操作系统工程2011年秋季
- 基于 html5 & css3 的移动端多级选择框html-multi-selector-master.zip
- vue2-daterange-picker:Vue2日期范围选择器
