数据预处理:关键步骤与实战操作
需积分: 35 34 浏览量
更新于2024-09-10
收藏 185KB DOCX 举报
数据预处理是统计分析过程中的关键步骤,它在数据准备阶段扮演着至关重要的角色。这一过程涉及到对原始数据进行清洗、整理和转化,以便于后续的分析和模型构建。以下是实验二关于数据预处理的具体内容:
1. 实验目的:
数据预处理的目的是确保数据的质量和一致性,使其符合统计分析的要求。这包括消除错误、缺失值,处理异常值,以及对数据进行归一化或标准化,使得各个变量在分析中具有可比性。
2. 实验环境:
需要具备基本的硬件设备,如PC及联网环境,以及特定的软件工具,如Windows操作系统、SQLServer2005数据库管理系统和SPSS统计软件,这些都是数据管理和分析的基础平台。
3. 实验内容:
- 变量级别的数据管理:
a) 数据分组合并:通过重新编码技术,将CCSS_Sample.sav中的年龄数据按照年龄段进行分组,如18-34岁、35-54岁等,便于后续分析。
b) 离散化:对连续性变量如S3年龄进行可视化或最优的离散化处理,例如将年龄变量分为10个等间距的区间,以便更好地理解和解释数据。
- 文件级别的数据管理:
a) 排序个案:按照指定的变量(如time)对个案进行排序,有助于发现数据的内在规律。
b) 分割文件:将CCSS_Sample.sav中的数据根据时间(time)进行分组,如2007年和2008年,便于分别进行分析。
c) 选择个案:筛选出特定时间段(如2009年12月)的数据,减少分析样本的复杂性。
d) 分类汇总:对选定的变量(如index1)按时间(time)和城市(S0)进行分类,计算平均值,并将结果汇总到新的数据文件Sum_index1中,便于进行深入的统计分析。
通过这些操作,数据预处理确保了数据的可用性和有效性,使统计分析结果更加可靠和精确。在实际应用中,数据预处理是一个细致且必不可少的过程,它直接影响到最终的分析结论和业务决策。
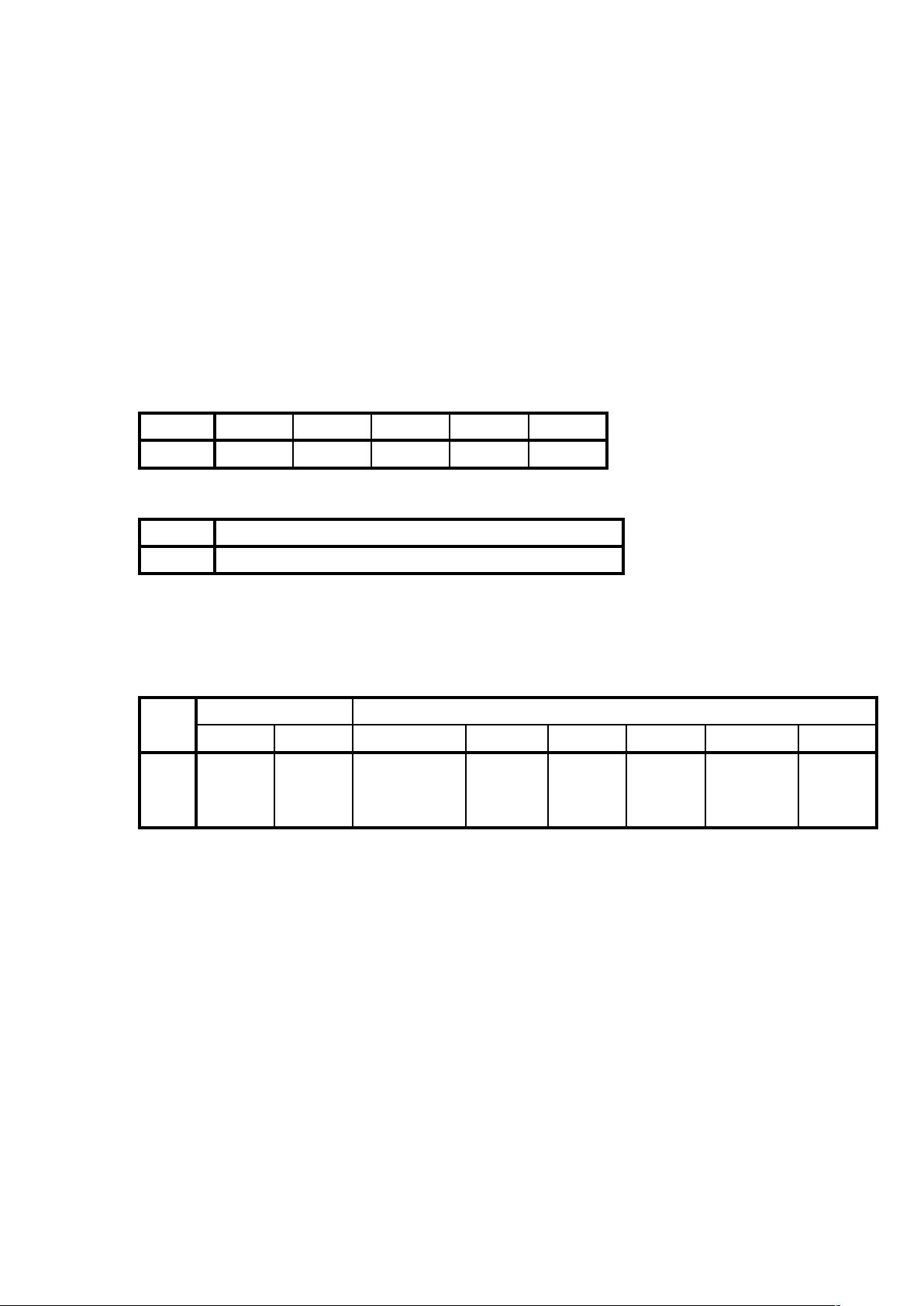
(3)连续性变量的最优离散化:
CCSS_Sample.sav 中,利用 S3 年龄变量对 S4 学历进行预测建模,要求基
于此构思对 S3 进行最优离散化。
最优离散化
描述统计
N
极小值 极大值 相异值数 块个数
S3. 年龄
1147 18 65 48 2
模型熵
模型熵
S3. 年龄
2.048
模型熵越小表示参照变量 S4. 学历 上的离散化变量的预测准确性越高。
离散化摘要
S3. 年龄
块
端点 水平 S4. 学历 的个案数
下限 上限 初中/技校或以下 高中/中专 大专 本科 硕士或以上 总计
1
a
40 56 149 236 234 48 723
2 40
a
98 164 95 58 9 424
总计
154 313 331 292 57 1147
每个块的计算方法为: 下限 <= S3. 年龄 < 上限。
a. 无限制
剩余10页未读,继续阅读
3684 浏览量
904 浏览量
170 浏览量
2331 浏览量
3168 浏览量
315 浏览量
1010 浏览量
989 浏览量

wcf0512
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 小学水墨风学校网站模板设计
- 深入理解线程池的实现原理与应用
- MSP430编程代码集锦:实用例程源码分享
- 绿色大图幻灯商务响应式企业网站开发源码包
- 深入理解CSS与Web标准的专业解决方案
- Qt/C++集成Google拼音输入法演示Demo
- Apache Hive 0.13.1 版本安装包详解
- 百度地图范围标注技术及应用
- 打造个性化的Windows 8锁屏体验
- Atlantis移动应用开发深度解析
- ASP.NET实验教程:源代码详细解析与实践
- 2012年工业观察杂志完整版
- 全国综合缴费营业厅系统11.5:一站式缴费与运营管理解决方案
- JAVA原生实现HTTP请求的简易指南
- 便携PDF浏览器:随时随地快速查看文档
- VTF格式图片编辑工具:深入起源引擎贴图修改
