深度学习基础详解:从基本概念到优化策略
版权申诉
"这份文档是关于深度学习基础知识的五万字总结,涵盖了深度学习的核心概念、网络操作与计算、超参数、激活函数、Batch Size、归一化以及权重偏差初始化等多个方面,旨在帮助读者深入理解并掌握深度学习的理论与实践。"
1. 基本概念
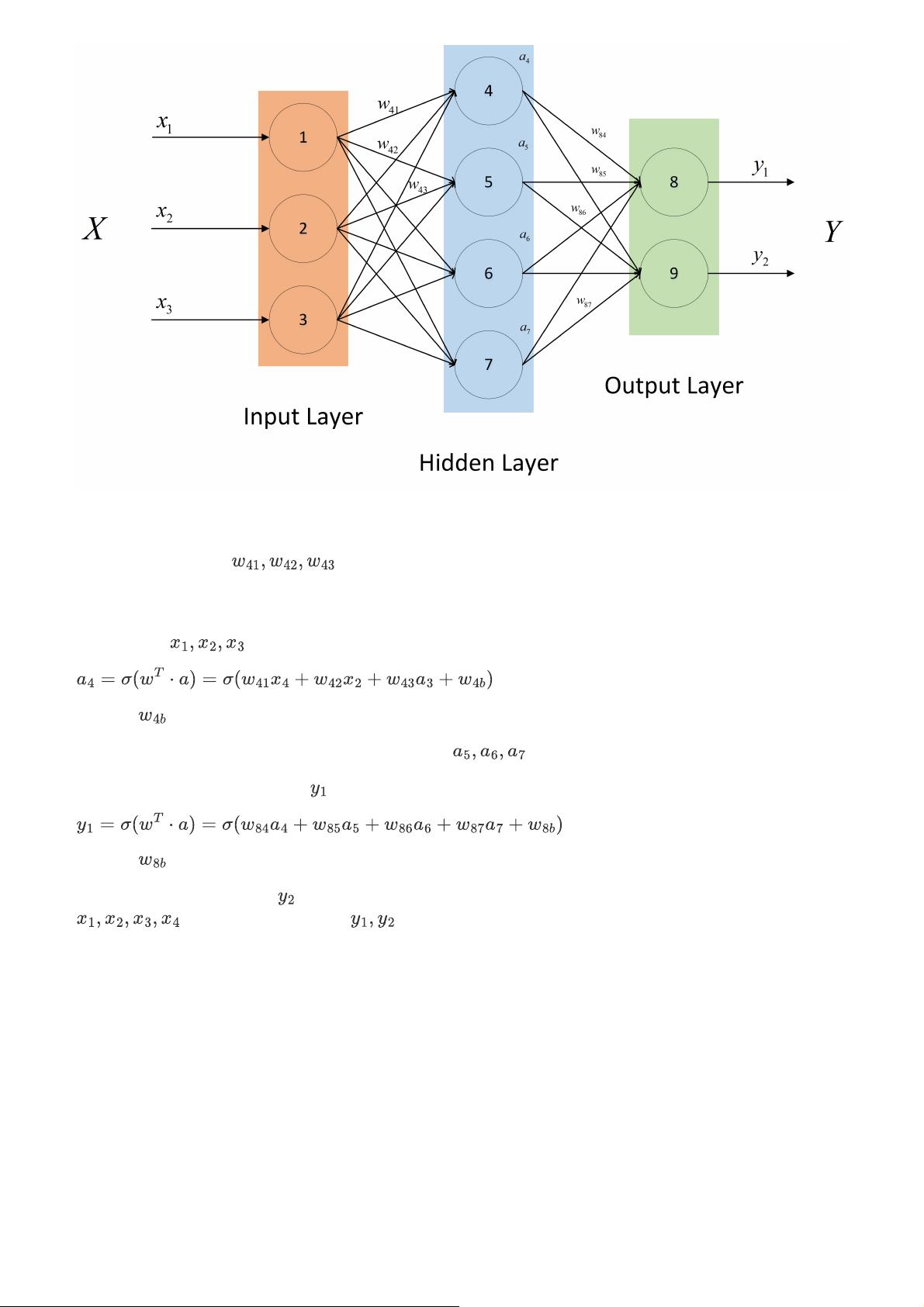
- 神经网络由输入层、隐藏层和输出层组成,通过权重和偏置连接各个神经元,形成复杂的非线性模型。
- 常见的模型结构包括全连接网络(FCN)、卷积神经网络(CNN)、循环神经网络(RNN)以及递归神经网络(GRU)、长短期记忆网络(LSTM)等。
- 深度学习开发平台的选择通常考虑易用性、性能、社区支持等因素,如TensorFlow、PyTorch、Keras等。
- 深层神经网络由于梯度消失或爆炸问题,训练难度较大。
- 深度学习与机器学习的主要区别在于深度学习利用多层非线性变换自动学习特征,而机器学习往往需要手动设计特征。
2. 网络操作与计算
- 前向传播是指输入数据通过网络各层计算直至输出的过程,反向传播则是根据损失函数反向计算权重更新的方向。
- 计算神经网络输出涉及激活函数应用和权重矩阵乘法。
- 卷积神经网络的输出值由卷积核和输入数据按位置相乘后加权求和得到。
- Pooling层用于下采样,输出值通常是池化窗口内的最大值或平均值。
- 反向传播用于优化网络权重,实例理解和推导有助于深入理解其原理。
3. 超参数
- 超参数是在学习过程开始前设置的参数,影响模型的构建和学习过程,如学习率、批次大小、网络层数等。
- 寻找超参数的最优值通常通过网格搜索、随机搜索或贝叶斯优化等方法。
- 超参数搜索一般先确定范围,然后通过验证集进行调优。
4. 激活函数
- 激活函数引入非线性,使神经网络有能力处理复杂关系。
- 常见的激活函数有sigmoid、tanh、ReLU、Leaky ReLU、ELU等,它们有不同的性质和适用场景。
- ReLU因其简单和高效,在大多数情况下优于其他激活函数,但负区全零可能导致梯度消失。
- Softmax函数用于多分类问题,将连续向量转化为概率分布。
5. Batch Size
- Batch Size指每次迭代更新权重时使用的样本数量。
- 设置合适的Batch Size可以平衡训练速度和模型精度。
- 增大Batch Size可以加快训练速度,但可能影响模型泛化能力。
- 盲目增大Batch Size可能导致训练不稳定,甚至过拟合。
6. 归一化
- 归一化是为了让数据在同一尺度上,有利于优化过程。
- 归一化可以加速梯度下降,减少训练时间。
- 常见的归一化方法有Z-Score标准化、Min-Max标准化、归一化等。
- 局部响应归一化和批归一化都是用于神经网络的正则化技术,提升模型性能。
7. 权重偏差初始化
- 权重初始化对模型的训练效果有很大影响,不同的初始化策略如随机初始化、Xavier初始化、He初始化等。
- 初始权重的设置应避免梯度消失或爆炸。
- 权重偏差初始化也是关键,通常会初始化为非零值以避免死节点。
8. 学习率
- 学习率控制每次迭代权重更新的步长,过大可能导致训练不稳定,过小则训练速度慢。
- 动态调整学习率(如学习率衰减、余弦退火等)有助于找到最优解。
这些内容构成了深度学习的基础,理解并掌握这些知识点对于深入研究深度学习和实际应用至关重要。
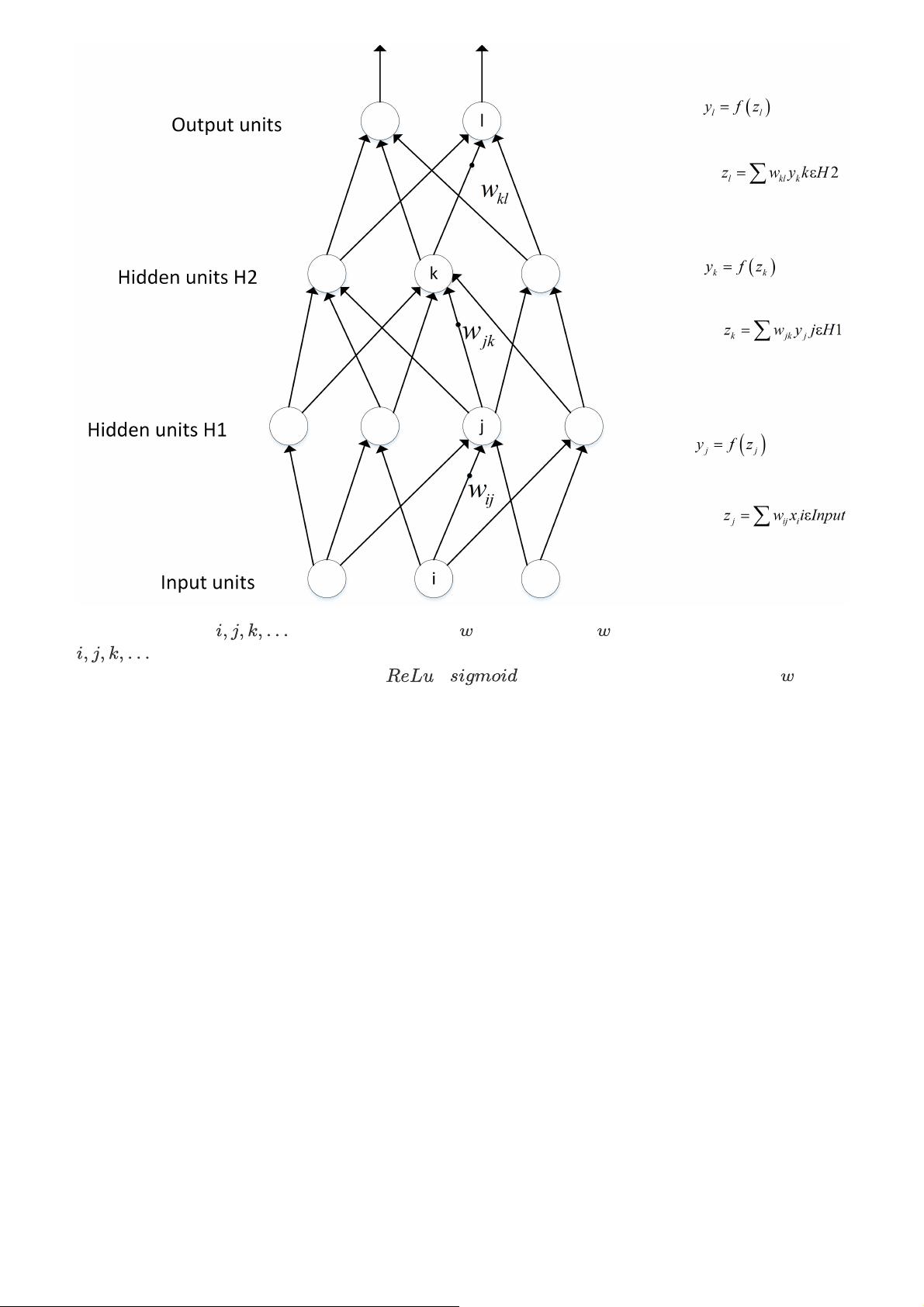
假设上一层结点 等一些结点与本层的结点 有连接,那么结点 的值怎么算呢?就是通过上一层的
等结点以及对应的连接权值进行加权和运算,最终结果再加上一个偏置项(图中为了简单省略了),最
后在通过一个非线性函数(即激活函数),如 , 等函数,最后得到的结果就是本层结点 的输
出。
最终不断的通过这种方法一层层的运算,得到输出层结果。
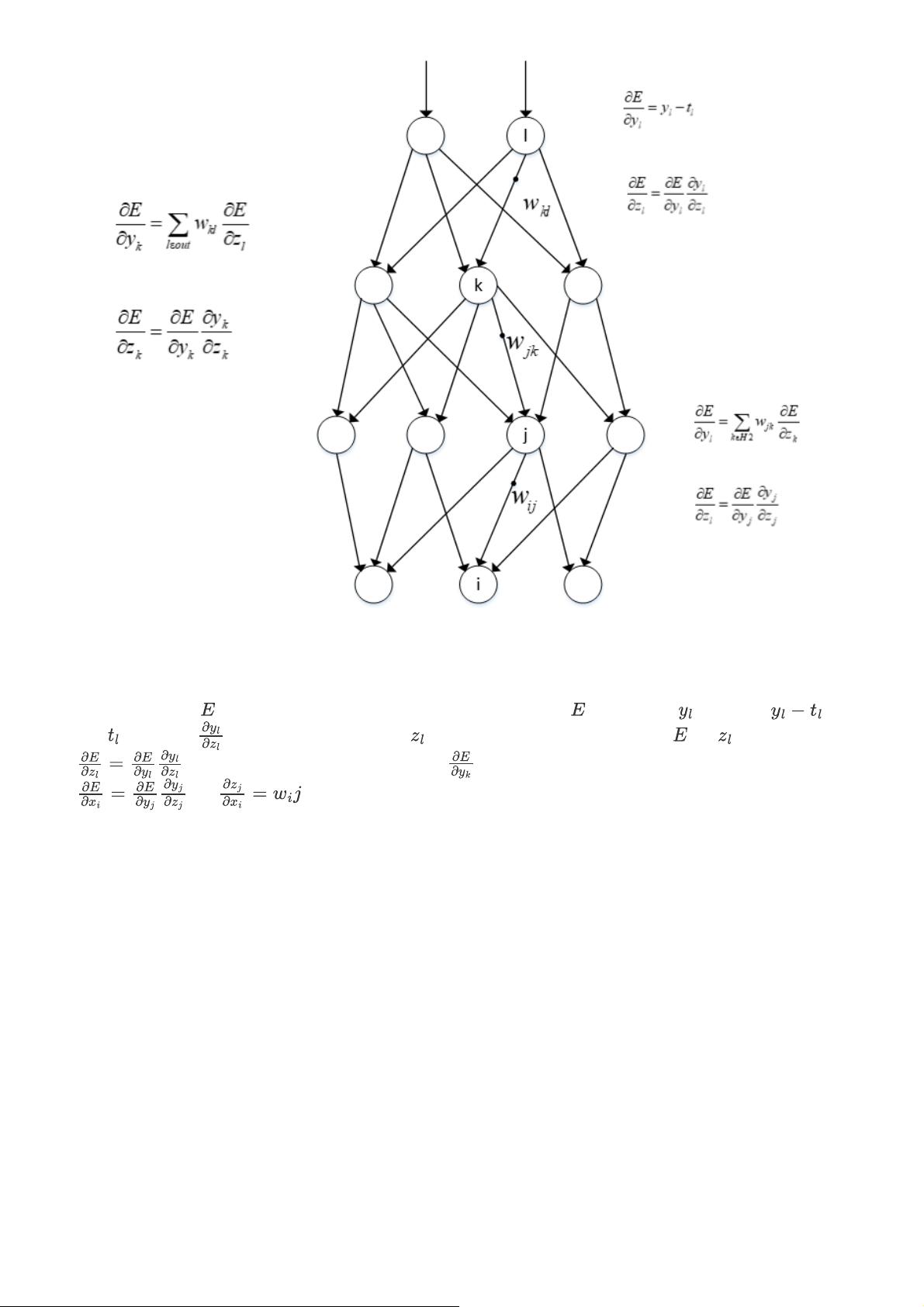
反向传播
剩余66页未读,继续阅读
2024-03-31 上传
2023-05-15 上传
2021-11-13 上传
2021-12-17 上传
2024-03-31 上传
2021-12-17 上传
2021-11-28 上传
2021-07-28 上传
2022-02-26 上传

AI浩
- 粉丝: 15w+
- 资源: 228
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
