Spark集群计算:利用数据集加速迭代应用
需积分: 5 70 浏览量
更新于2024-07-17
收藏 1.33MB PDF 举报
"Spark Cluster Computing with Data Set,深入理解Spark集群计算与数据集,适合Spark初学者,英文原版教程"
Spark是当前大数据处理领域的一个关键工具,它以高效、易用和弹性著称,特别是在处理大规模数据集时。本教程主要关注在Spark中进行集群计算的数据集(Resilient Distributed Dataset,简称RDD)的概念和应用。
**为什么选择Spark?**
Spark设计的核心目标是解决MapReduce框架的一些局限性。MapReduce的数据流模型是无环的,这导致了它不适用于迭代工作负载,如机器学习和图分析。在MapReduce中,每次迭代都需要重新读取和序列化数据,这显著增加了延迟。此外,MapReduce不支持交互式分析,用户需要等待从磁盘读取数据或反序列化,这降低了数据分析的效率。同时,MapReduce处理多个查询时,每个查询都是独立的,即使它们基于相似的基础数据。
**什么是“重用工作集”?**
在迭代算法中,“重用工作集”意味着在不同迭代之间使用相同的数据。这就像虚拟内存,数据被保留在内存中,减少了磁盘I/O。例如,k-means聚类算法需要对数据点进行多次分类,逻辑回归用于分类任务时,需要反复处理数据点,而期望最大化(Expectation Maximization)算法则用于处理观测数据。交替最小二乘法(Alternating Least Squares)在协同过滤等推荐系统中应用,需要频繁处理特征向量。
**如何实现高效的集群计算?**
Spark通过引入RDD实现了对工作集的高效重用。RDD是弹性分布式数据集,它是不可变的、分区的数据集合,可以在集群中进行并行操作。RDD的一个关键特性是缓存(Caching),它可以将数据保存在内存中,避免反复从磁盘读取和序列化。这种做法显著提升了处理速度,尤其是在需要多次访问同一数据集的情况下。
**Spark与Scala的结合**
Spark的API设计紧密集成在Scala语言中,这使得Spark程序具有高表达性和可读性。开发者可以方便地利用Scala的函数式编程特性,编写简洁且高效的代码。
**示例与应用**
教程中可能包含各种示例,演示如何使用Spark创建和操作RDD,以及如何应用于实际问题。这些例子可能涵盖简单的数据处理任务到复杂的机器学习模型训练。Spark可以广泛应用于数据挖掘、实时流处理、图分析和机器学习等多个领域。
"Spark Cluster Computing with Data Set"教程旨在帮助读者理解和掌握Spark的集群计算能力,特别是围绕RDD的高效使用,以便在大数据处理项目中实现更快速、更灵活的解决方案。通过学习这个教程,读者将能够更好地应对需要迭代计算和交互式分析的场景。

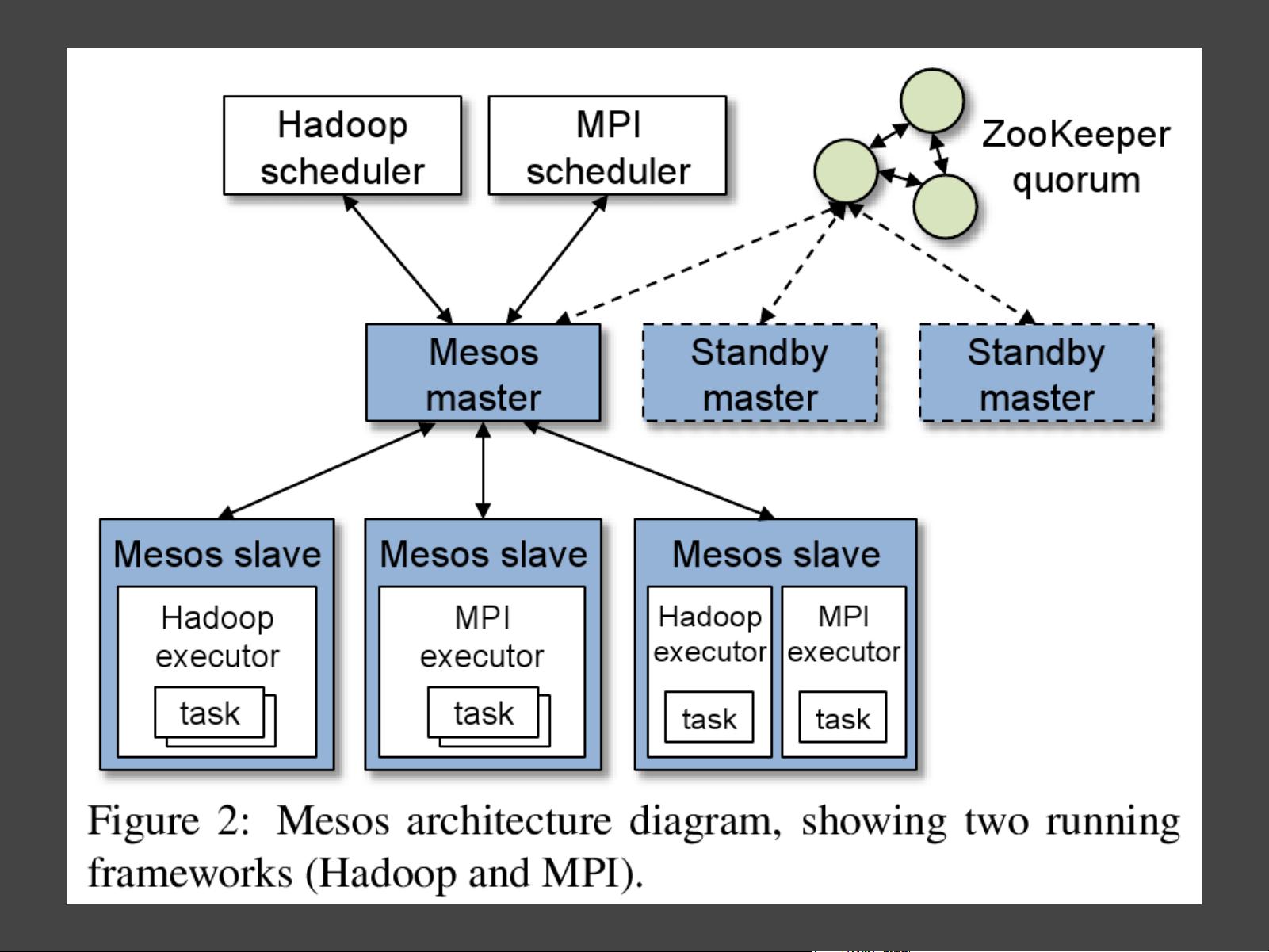
Mesos
● Resource isolation and sharing across distributed
applications
● Manages pools of compute instances
○ distribution of files, work, memory
○ network communications
● Allow heterogeneous and incompatible systems to coexist
within a cluster.
● Give each job the resources it needs to ensure throughput
○ Don't starve anyone
○ But make sure to utilize all available resources
● Manages different types of systems in a cluster
○ Spark, Dryad, Hadoop, MPI
● Allow multiple datasets for multiple groups to process, all
using their own data.
剩余36页未读,继续阅读
262 浏览量
280 浏览量
193 浏览量
2015-01-04 上传
2018-04-19 上传
240 浏览量
196 浏览量
238 浏览量
Advanced Web Crawler Data Processing and Cleaning Techniques: Using Spark for Big Data Cleansing ...
点击了解资源详情
点击了解资源详情

zr1800
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Blogs:Vue原始解析React设计思想webpack工作流程分析前端性能优化
- 易语言FTP上传带进度
- solid-bassoon:Lorem ipsum dolor坐下,一直保持良好状态。 明天会自食其果。 Fusce turpis velit,一些人的边界处的诅咒,简历
- 自制软件:为学生安装自制软件
- 易语言FTKernelAPI内核应用
- DummyTM:一页帮助程序,用于威胁建模跟踪
- FrontVue
- yyate2tara,c语言阳历转阴历源码,c语言程序
- Halcon项目之刀口缺陷检测
- 易语言flash看视频
- react-typescript-starter:此存储库包含一个基本的React应用,其中包含出色的工具
- nicolesaunders.megatsby
- 移动操作系统原理与实践课件.zip
- remotelogger-1.0.zip
- web-develop:web前端学习记录
- netty-learn:Netty4.X社区配套原始码,博客地址:https
