无监督少样本学习:自我监督表示学习的崛起
194 浏览量
更新于2024-06-19
收藏 793KB PDF 举报
自我监督:无监督FSL方法中的有效表示学习
自我监督学习是机器学习中的一种重要方法,指的是模型在没有标签的情况下学习和改进自己的性能。该方法可以应用于少样本学习(FSL)领域,解决传统FSL方法依赖于大型标记数据集的限制。
在信息论的角度来看,自我监督学习可以通过捕获数据的内在结构来学习全面的表示。我们的方法遵循InfoMax原则,最大化实例和他们的代表与低偏MI估计执行自我监督的预训练。这种方法可以减少对可见类的偏见,学习更泛化的表示。
我们的自监督模型可以应用于少样本学习领域,解决传统FSL方法中的挑战性问题。传统FSL方法需要大量的标记数据集来学习先验知识,但是收集大规模的基础数据集在实践中是昂贵的。我们的方法可以充分利用丰富的未标记数据,学习更泛化的表示。
实验结果表明,自我监督的预训练可以优于监督的预训练,在广泛使用的FSL基准测试中实现了相当的性能,而无需任何基类标签。这证明了自我监督学习的有效性,可以应用于实际的FSL问题中。
自我监督学习可以解决传统FSL方法中的挑战性问题,例如标签依赖性问题。我们的方法可以应用于无监督FSL领域,学习泛化的表示,而不需要大量的标记数据集。这证明了自我监督学习的重要性和实用性。
自我监督学习可以应用于少样本学习领域,解决传统FSL方法中的挑战性问题,学习泛化的表示,而不需要大量的标记数据集。这项技术可以广泛应用于计算机视觉、自然语言处理等领域,解决实际的问题。
在计算机视觉领域,自我监督学习可以应用于图像分类、目标检测、图像分割等问题中。例如,在图像分类问题中,自我监督学习可以学习泛化的表示,解决少样本学习问题。同时,自我监督学习也可以应用于自然语言处理领域,解决文本分类、命名实体识别等问题。
自我监督学习是一种重要的机器学习方法,能够解决传统FSL方法中的挑战性问题,学习泛化的表示,而不需要大量的标记数据集。这项技术可以广泛应用于计算机视觉、自然语言处理等领域,解决实际的问题。
+v:mala2255获取更多论
文
D
D
{}
D
{ }
|
带标签的基础数据
监督
预训练
图像 编码 器
丢失
标签
自我监督可以是一个很好的少数学习者5
或
预训练微调
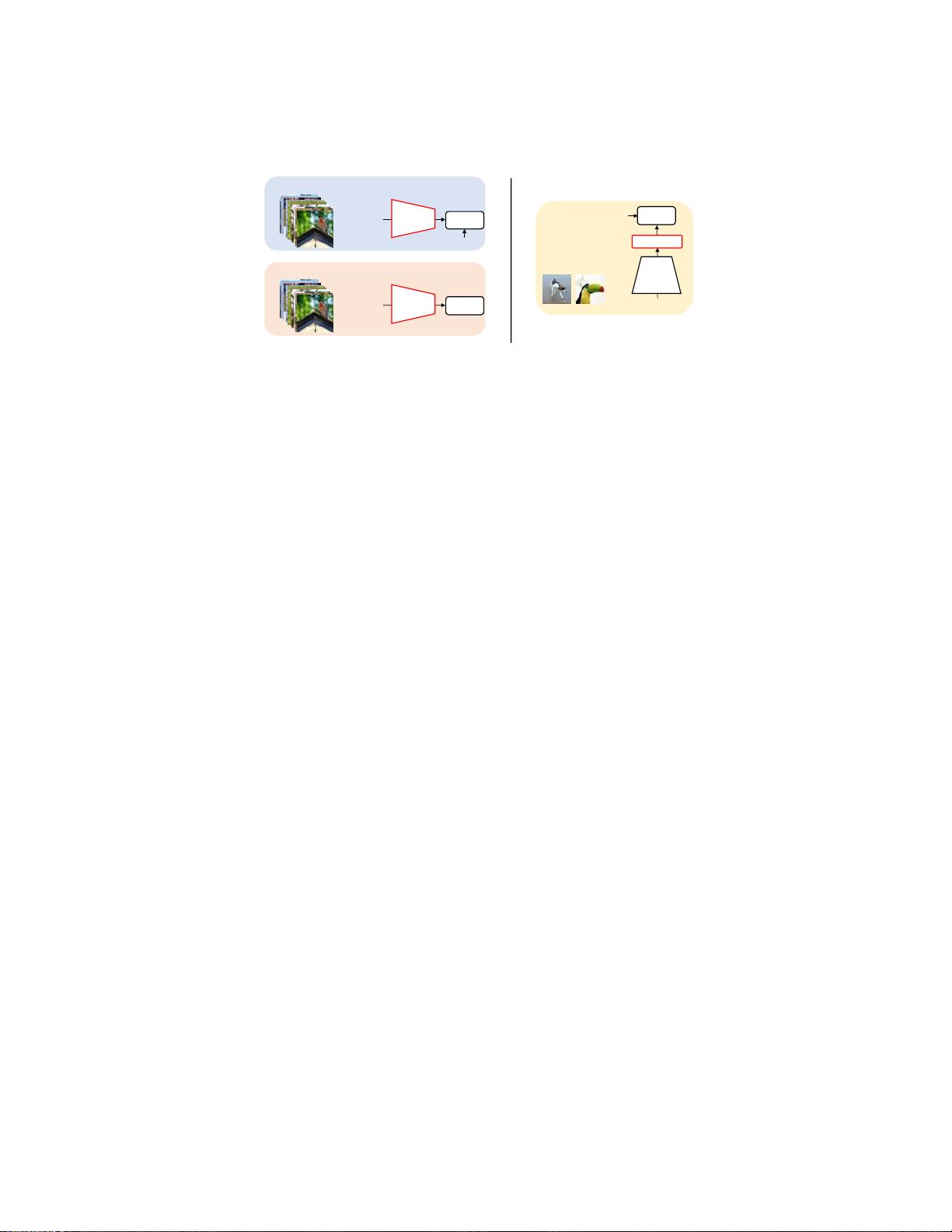
图1:FSL中预训练-&微调方法的概述。
(
左
)在预训练阶段,编码器网络
在具有监督(或自监督)损失的标记(或未标记)基础数据集上进行训
练。(
右
)在微调阶段,线性分类器(例如,逻辑回归)是用冻结的预
训练编码器在几个支持样本
预测,其中
y
s
是图像
x
s
的类标签。作为
N
路
K
次射击分类任务
T
,
K
相
对较小(例如,1或5通常)和
N
小说类别是不是在
基地
。
带监督预训练的
FSL
。
最近的工作[10,71]表明,一个简单
的预训练&-微
调方法是FSL的强大基线。这些方法预训练编码器(例如,卷积神经
网络)。在下游FSL任务中,简单的线性分类器(例如,在我们的情
况下,逻辑回归)在具有支持样本的固定编码器网络的输出特征上进
行训练最后,使用具有自适应分类器的预训练编码器① 的人。
无监督
FSL
设置。
与监督FSL(其中
D
base
=(
x
i
,
y
i
))相反,只有未标
记的数据集
base
=
x
i
在预训练(或元训练)阶段
可用于无监督FSL。我们的自我监督预训练方法遵循上面讨论的标准预
训练&-微调策略,除了基础数据集是
未标记
的(如图1所示)。请注
意,为了进行公平的比较,我们的模型
没有
在任何额外的(未标记
的)数据上进行训练。
3.2
FSL
的自我监督预训练
自我监督预训练和监督预训练最大化不同
的
MI
目标。
有监督的预训练旨在将基
础数据集的分类损失减少到零。 最近的一项研究[74]表明,在监督训练过
程中存在普遍的
神经崩溃
现象,其中类内样本的表示崩溃到类均值。 这意
味着给定类标签
Y
的隐藏表示
Z
的
条件熵
H
(
Z Y
)很小。事实上,Boudiaf
等
人。
[6]指出,最小化交叉熵损失相当于最大化
表示
Z
和
标签
Y
之间的互信息
I
(
Z
;
Y
)。 Qin
等
[
58]也证明了类似的结果。
未标记基础数据
自我监督
预训练
图像 编码 器
丢失
标签丢失
分类器
支持数据
编码器
图像
剩余20页未读,继续阅读
2018-06-03 上传
2021-04-19 上传
2021-05-26 上传
2021-03-20 上传
2021-05-20 上传
2021-05-17 上传
2021-04-02 上传
2021-02-16 上传
2021-03-18 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
