Kettle在智能运维中的数据处理应用
需积分: 5 4 浏览量
更新于2024-08-05
收藏 1.42MB DOCX 举报
"Kettle应用文档提供了关于如何在智能运维平台上使用ETL工具Kettle进行数据清洗、汇总和处理的详细步骤。文档适用于开发工程师,旨在确保业务数据能正确流转并适应系统的数据需求。"
在智能运维环境中,Kettle作为一个强大的ETL(Extract, Transform, Load)工具,被用来处理业务数据,使其符合系统需求。Kettle以其灵活性和对多种数据库的良好支持,成为数据处理的理想选择。在具体应用中,以下是一套详细的使用流程:
1. **安装准备**:首先,需要下载Kettle的安装包,由于Kettle是基于Java开发的,因此在安装之前需确保系统已装有Java运行环境。安装JDK时,通常只需按照默认设置一步步进行。
2. **检查与启动**:安装JDK后,通过运行相关命令检查安装是否成功。接着,解压缩Kettle的安装包,这是一个免安装版本,直接启动即可。启动后的界面表明Kettle已经成功运行。
3. **创建转换业务**:在Kettle中,数据处理的核心是通过创建“转换”来实现。转换定义了数据从源到目标的路径,包括数据清洗和转换规则。这里,以处理氧气数据为例,我们需要创建一个新的转换。
4. **配置基础信息**:这一步包括设置数据库连接。Kettle支持多种数据库,可以方便地建立与不同数据库的链接,以便进行数据的读取和写入。
5. **数据处理**:在转换中,通过添加步骤(如“获取表数据”)来从元数据库中选择需要的数据。例如,可以从test_table表中抽取数据。对于实际项目,应根据业务数据库调整这些设置。
6. **字段映射与更新逻辑**:选择“插入更新”配置数据的插入和更新规则,并使用“编辑映射”来查看和设定字段间的对应关系,确保数据准确无误地更新到目标数据库。
7. **定时同步与作业设置**:Kettle还提供了定时同步功能,通过创建作业来安排转换的执行。保存作业配置,设定作业参数,然后指定作业执行的转换信息。
8. **作业启动与监控**:最后,启动作业并监控其执行情况,以确保数据处理过程按预期进行,没有错误或异常。
Kettle是实现业务数据自动化处理的关键工具,通过其丰富的功能和用户友好的界面,开发工程师能够高效地处理各种复杂的数据操作,满足智能运维平台的数据需求。在实际工作中,熟悉并掌握Kettle的各项操作,将极大地提高数据处理的效率和质量。
Kettle 应用文档
背景:
智能运维平台,目前阶段使用模拟发生器模拟标准数据,用于业务逻辑验证,正式应该
于业务中需要和具体的业务数据结合进行业务流转,为了能够使业务正常流转,需要把实
际的业务数据进行清洗,汇总,处理成系统可以“认识”的数据,需要通过 ETL 工具 Kettle
进行处理。
具体使用步骤:
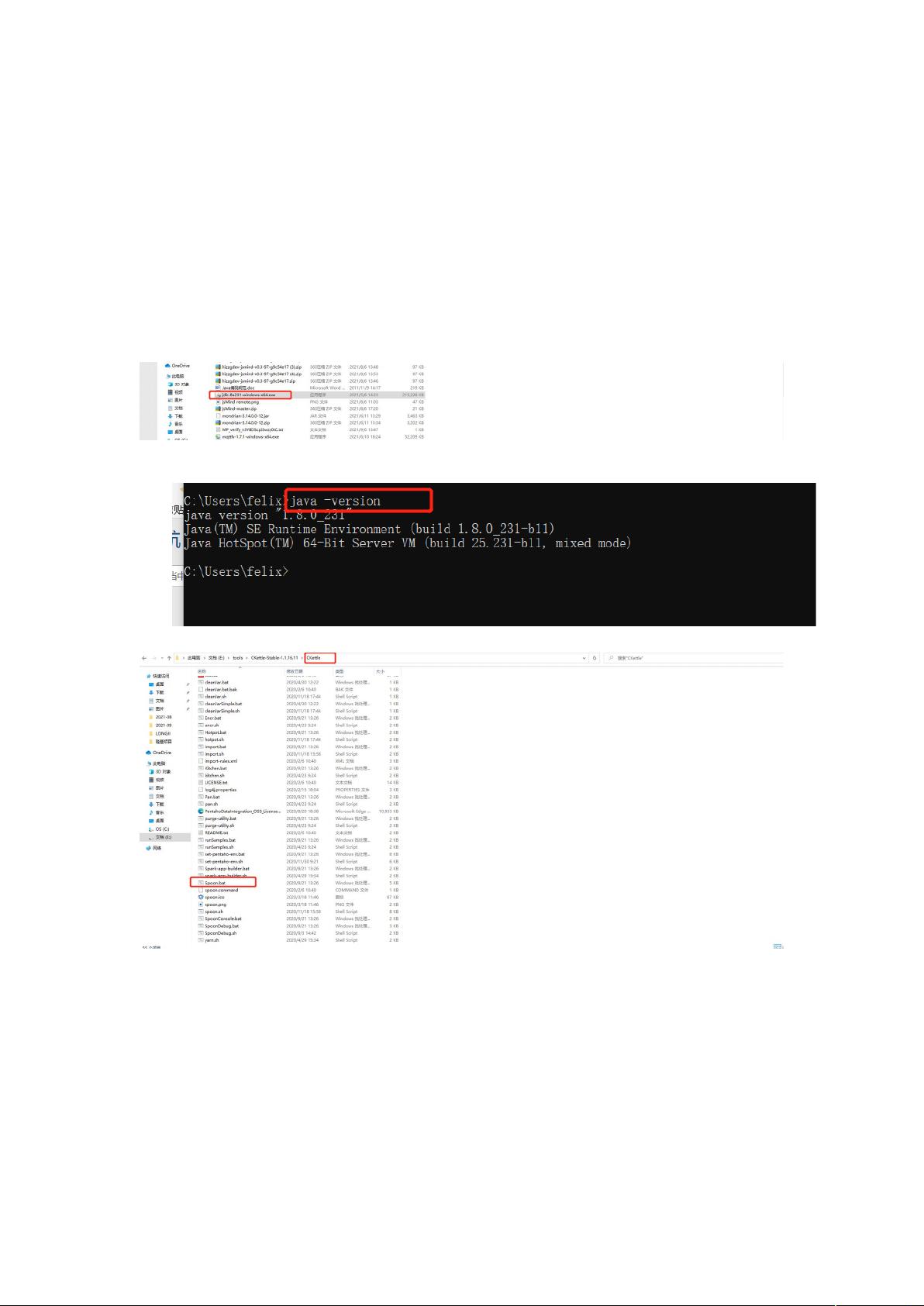
安装 kettle 工具,首先需要获取 kettle 的按照包,kettle 是纯 java 开发,使用需要安装
java 运行环境。
(1) 安装 java 运行环境,JDK 安装。具体点击安装,直接下一步到安装完成。
(2) 检查安装结果,出现截屏显示,表示安装成功
(3) 运行 kettle 软件工具(解压缩,免安装),点击启动
(4) 出现一下界面,kettle 启动正常
下载后可阅读完整内容,剩余7页未读,立即下载
138 浏览量
290 浏览量
766 浏览量
126 浏览量
696 浏览量
280 浏览量
152 浏览量
2021-11-18 上传
2022-01-04 上传









