Python Selenium爬虫实战:拉勾网职位信息抓取
需积分: 0 64 浏览量
更新于2024-08-04
收藏 897KB DOCX 举报
"本文主要介绍了如何使用Python的Selenium库来爬取拉勾网的招聘信息。Selenium是一个功能强大的Web自动化测试工具,也可以用于网页数据的抓取,尤其适合处理JavaScript渲染的页面。"
在爬取拉勾网时,首先需要了解爬虫的基本流程,包括分析网页、解析数据和保存数据。对于拉勾网,由于其页面内容由JavaScript动态生成,传统的requests库可能无法直接获取完整信息,因此选择Selenium更加合适。
1. 分析网页
在分析网页阶段,我们需要了解网页的结构和交互逻辑。例如,拉勾网在打开时会有一个选择城市的步骤。使用Selenium,可以模拟用户行为,如选择“全国”城市。通过以下代码可以实现:
```python
from selenium import webdriver
driver = webdriver.Chrome() # 使用Chrome浏览器,需要提前安装对应驱动
driver.get('https://www.lagou.com/')
# 假设city_selector是选择城市元素的定位器
city_selector = driver.find_element_by_id('city_selector')
city_selector.click()
```
2. 解析数据
接着,我们需要找到搜索框并输入关键词。在浏览器中使用开发者工具(F12)定位到搜索框元素,然后通过XPath或CSS选择器提取。假设search_box是搜索框的定位器,我们可以这样操作:
```python
search_box = driver.find_element_by_xpath('//input[@class="search-keyword"]')
search_box.send_keys('运维工作') # 输入关键词
search_box.submit() # 提交表单,触发搜索
```
3. 点击搜索并处理反爬策略
搜索后,需要点击搜索结果页上的“搜索”按钮。同样,定位该元素并调用`.click()`方法。此外,为了避免被网站识别为爬虫,需要设置延迟以模拟人类操作:
```python
import time
search_button = driver.find_element_by_css_selector('.search-btn')
search_button.click()
time.sleep(2) # 设置2秒延迟
```
4. 网页数据的解析
在解析数据阶段,我们需要找到目标数据所在的HTML元素,如职位名称、公司名称等,然后提取所需信息。这通常涉及查找元素、提取文本或者属性值。例如,如果职位名称在类名为`job-item-title`的元素内,我们可以这样做:
```python
job_titles = driver.find_elements_by_css_selector('.job-item-title')
for title in job_titles:
print(title.text)
```
5. 保存数据
最后,将抓取到的数据保存到文件,如CSV或JSON格式,以便后续分析。这里可以使用pandas库:
```python
import pandas as pd
data = [{'title': title.text, 'company': company.text} for title, company in zip(job_titles, company_elements)]
df = pd.DataFrame(data)
df.to_csv('lagou_jobs.csv', index=False)
```
总结来说,使用Selenium爬取拉勾网的关键在于模拟用户交互,解析动态加载的内容,并处理可能的反爬策略。通过以上步骤,可以成功抓取并解析拉勾网的招聘信息。不过,实际操作时要注意遵守网站的robots.txt协议,尊重网站版权,避免对网站造成不必要的压力。
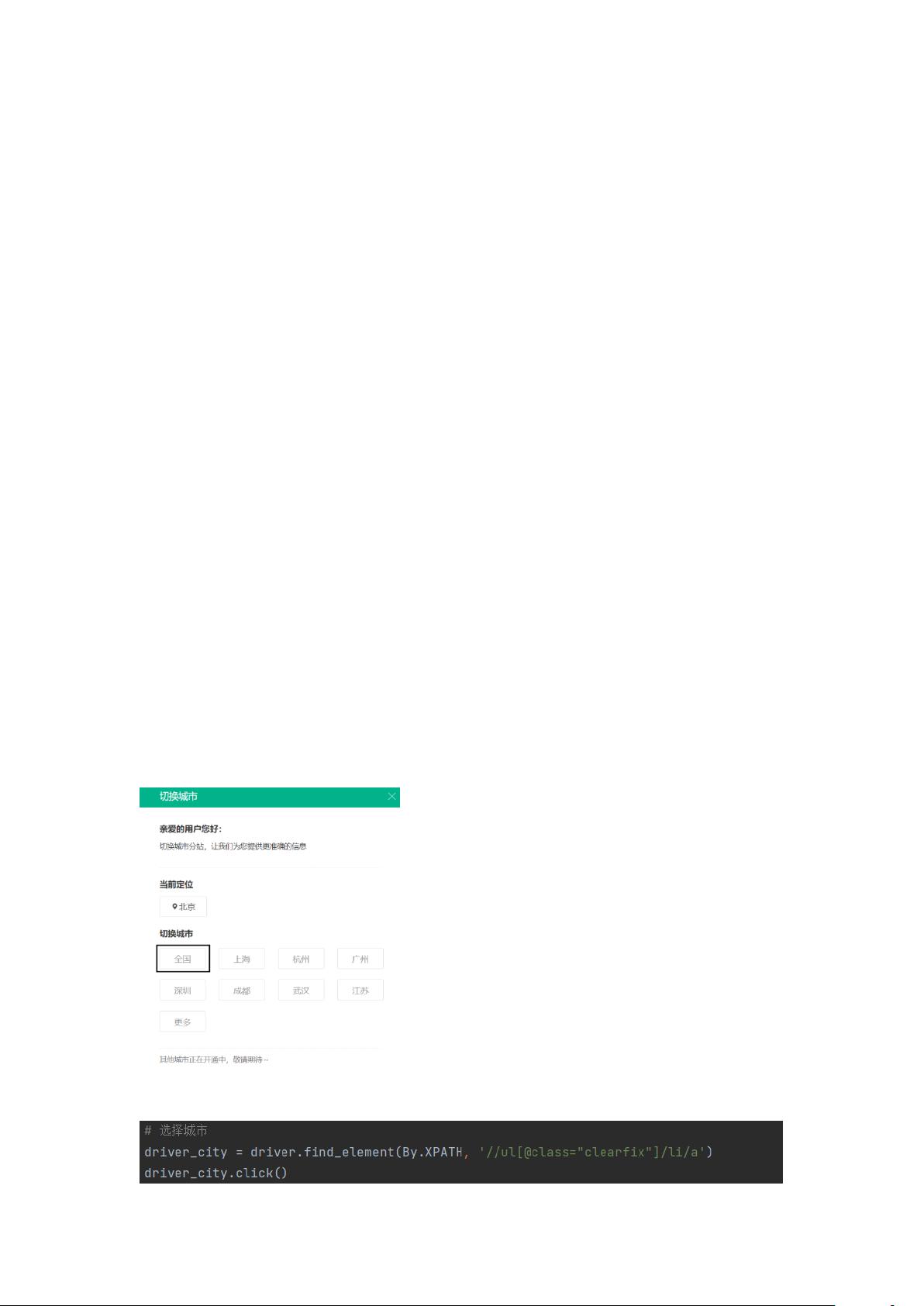
Selenium 爬取拉勾网的数据
爬虫三步骤:
一、分析网页;
二、解析数据;
三、保存数据。
一、登录拉钩招聘网址(https://www.lagou.com/)
(1)刚刚登录页面时候呢就会有一个选择城市的页面,这时就可以随便选择一个城市或者
直接暴力点击“×”,但是这个步骤呢并不是我们自己手动来操作的,而是把这个过程交给
程序来操作就可以,那又得如何操作呢?这个就会涉及到 python 爬虫技术里面的 selenium
模块。有人就会说直接使用 requests 模块爬取岂不是更好?是的,使用 requests 爬取这个网
站数据的话呢就需要有一点 js 逆向技术,因为这个网站是被 JavaScript 代码给渲染了,用
requests 模块对新手来说就会很难,小编选择 selenium 相对来说就会比较简单了,废话不多
说,直接上手。
这里呢我是选择的“全国”这个框框,用下面这行代码就可以解决了。
下载后可阅读完整内容,剩余8页未读,立即下载
2018-10-20 上传
2020-12-22 上传
2019-08-10 上传
2021-05-01 上传
2018-04-21 上传
2021-10-03 上传
2021-10-11 上传
2024-10-25 上传

一杯彬美式
- 粉丝: 147
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
