"Spark安装与使用指导:快速构建多应用的高性能大数据处理工具"
 已收录资源合集
已收录资源合集
需积分: 0 38 浏览量
更新于2024-01-17
收藏 1.34MB DOCX 举报
Spark是一个通用的并行计算框架,用于大数据量下的迭代式计算。它支持Java、Python和Scala的API,并且提供超过80种高级算法,使用户可以快速构建不同的应用。Spark的安装和使用指导如下:
在了解Spark之前,我们先要了解一些基本概念。在2003年和2004年,Google分别发表了Google文件系统(GFS)和MapReduce编程模型两篇开源文档。这两篇文档成为了许多项目的基础,其中包括Hadoop。Hadoop是一种典型的大数据批量处理架构,它通过HDFS存储静态数据,并通过MapReduce将计算逻辑分配到各个数据节点进行数据计算和价值发现。Hadoop后来建立了许多项目,形成了Hadoop生态圈。
而Spark是加州大学伯克利分校AMP实验室开源的类Hadoop MapReduce的通用并行框架,专门用于大数据量下的迭代式计算。与Hadoop配合使用,而不是取代Hadoop。Spark之所以比Hadoop的MapReduce框架更快,是因为Spark将数据存储在内存中,而不是磁盘中,因此可以更快地访问和处理数据。
现在我们来介绍一下Spark的安装和使用指导。为了安装Spark,您需要首先下载Spark的二进制分发版。可以在Spark的官方网站上找到最新的版本。下载完成后,解压缩文件至您选择的目录。
在Spark安装完成后,您需要设置一些环境变量以便系统可以找到Spark的可执行文件。将Spark的安装目录路径添加到PATH环境变量中,这样您就可以在任何位置运行Spark了。
接下来,您需要设置Spark的相关配置。Spark提供了一个名为`spark-defaults.conf`的配置文件,您可以根据自己的需求进行修改。在这个文件中,您可以设置Spark的内存限制、Master节点的URL等。
在配置完成后,您现在可以启动Spark集群。Spark的集群由一个Master节点和多个Worker节点组成。在Master节点上启动Spark时,您需要指定使用的资源管理器,例如Standalone、YARN或者Mesos。可以通过运行如下命令启动Spark:
```
./sbin/start-master.sh
./sbin/start-worker.sh <master-url>
```
接下来,您可以通过Spark的Web界面查看集群的状态和任务的运行情况。通过访问Master节点的URL,您可以在浏览器中打开Spark的Web界面。在这个界面上,您可以查看集群的资源使用情况、任务的执行情况等。
现在您已经安装完成并启动了Spark集群,可以开始使用Spark进行开发了。Spark提供了Java、Python和Scala的API供开发者使用。您可以选择您熟悉的语言进行开发。
在Spark的API中,有许多高级算法可以使用。这些算法包括机器学习算法、图计算算法等。使用这些算法,您可以快速构建出各种应用程序,例如推荐系统、社交网络分析等。
总而言之,Spark是一个易用且功能强大的大数据处理框架。它提供了丰富的API和高级算法,使用户可以快速构建不同的应用程序。通过充分利用内存来加速数据处理,Spark比Hadoop的MapReduce框架更快速和高效。希望通过本文的介绍,您对Spark的安装和使用有了更加深入的理解。
图二
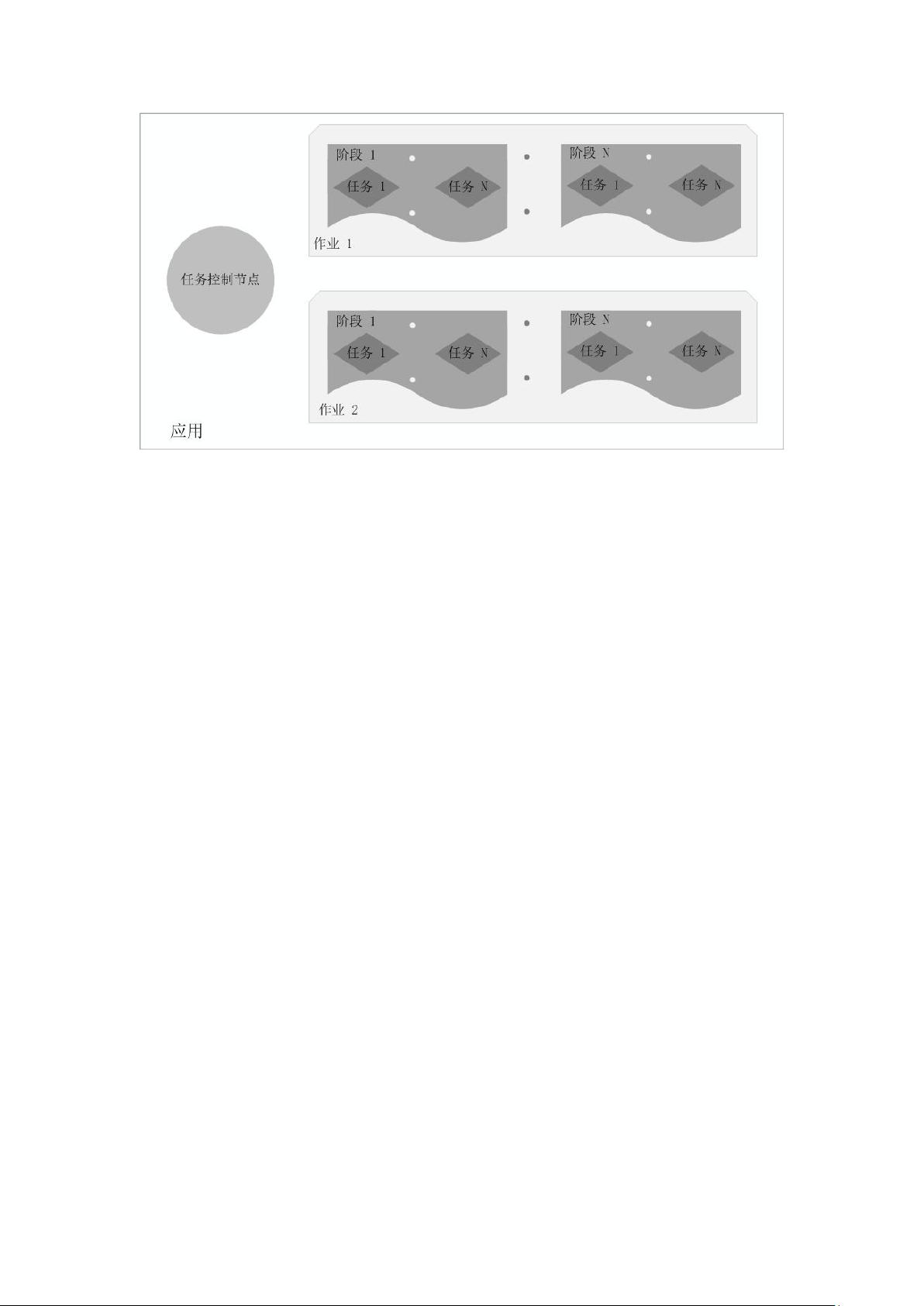
Spark 基本运行过程如图三:
(1)当一个 Spark 应用被提交时,首先需要为这个应用构建起基本的运行环
境,即由任务控制节点(Driver)创建一个 SparkContext,由 SparkContext
负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分
配和监控等。SparkContext 会向资源管理器注册并申请运行 Executor 的资
源;
(2)资源管理器为 Executor 分配资源,并启动 Executor 进程,Executor 运
行情况将随着“心跳”发送到资源管理器上;
(3)SparkContext 根据 RDD 的依赖关系构建 DAG 图,DAG 图提交给 DAG 调度器
(DAGScheduler)进行解析,将 DAG 图分解成多个“阶段”(每个阶段都是一个
任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交
给底层的任务调度器(TaskScheduler)进行处理;Executor 向 SparkContext
申请任务,任务调度器将任务分发给 Executor 运行,同时,SparkContext 将
应用程序代码发放给 Executor;
(4)任务在 Executor 上运行,把执行结果反馈给任务调度器,然后反馈给
DAG 调度器,运行完毕后写入数据并释放所有资源。
剩余17页未读,继续阅读
2017-10-17 上传
2015-01-19 上传
2023-06-08 上传
2024-04-13 上传
2023-07-27 上传

养生的控制人
- 粉丝: 23
- 资源: 333
 我的内容管理
展开
我的内容管理
展开







最新资源
- hibernate2安装手记.pdf
- 开源技术选型手册推荐
- 电脑超级技巧 很多的电脑问题迎刃而解
- C#完全手册 经典 权威
- Beginning Python 2ndEdition
- ISD2560中文芯片资料
- 操作数据库的通用类包含各种方法
- delphi函数参考手册
- Oracle语句优化53个规则详解(1)
- aaaaaaaaaaaaaaaaa
- Rapid GUI programming With Python And Qt
- ubuntu linux命令行简明教程
- c++ 标准库讲解,带给你一个全新的境界
- WebLogic 集群中SSL 配置说明
- OraclePL-SQL语言初级教程
- 将GridView列表当中的数据导成Excel
