MARGIN算法:有效挖掘最大频繁子图
需积分: 14 75 浏览量
更新于2024-07-26
收藏 949KB PDF 举报
Maximal frequent subgraph mining 是一个在数据挖掘领域中处理复杂网络结构的重要问题,其核心挑战在于面对数量呈指数级增长的子图可能性。传统的频繁子图挖掘方法可能会面临搜索空间过大、效率低下的问题,因为所有可能的子图组合需要逐一评估其频繁性,这在大规模数据中几乎是无法承受的。
在这种背景下,MARGIN (Maximal Frequent Subgraph Mining)算法应运而生。MARGIN算法的关键在于它专注于寻找搜索空间中的"边界"节点,这些节点位于频繁子图和不频繁子图的分界线上。通过这种方式,算法可以有效地避免对所有潜在候选模式进行无谓的搜索,显著地减小了待考虑的子图集合,从而提高了搜索效率。
MARGIN算法的运作机制是沿着频繁与不频繁子图的边界移动,只探索那些有可能包含最大频繁子图的节点。它的正确性通过理论证明得以保障,这意味着算法不仅在理论上有效,而且在实际应用中能够产生可验证的结果。实验结果显示,MARGIN技术在效率和实用性上都表现出色,特别是在处理大量数据时,能够显著提升频繁子图挖掘任务的性能。
MARGIN算法的研究集中在数据库管理领域,特别是数据挖掘应用中的数据归纳和模式发现。它的主要术语包括图挖掘(Graph mining)和最大频繁子图挖掘(Maximal Frequent Subgraph Mining),这些都是理解算法背景和技术细节的关键。此外,该工作还涉及到了算法设计中的通用术语——算法(Algorithms)。
MARGIN算法为解决大规模频繁子图挖掘问题提供了一种创新且高效的解决方案,它通过优化搜索策略,减少了计算量,使得在实际场景中,如社交网络分析、生物网络研究等,能快速提取出具有代表性的频繁子图结构,这对于理解和分析复杂的网络关系具有重要意义。
10:8
•
L. T. Thomas et al.
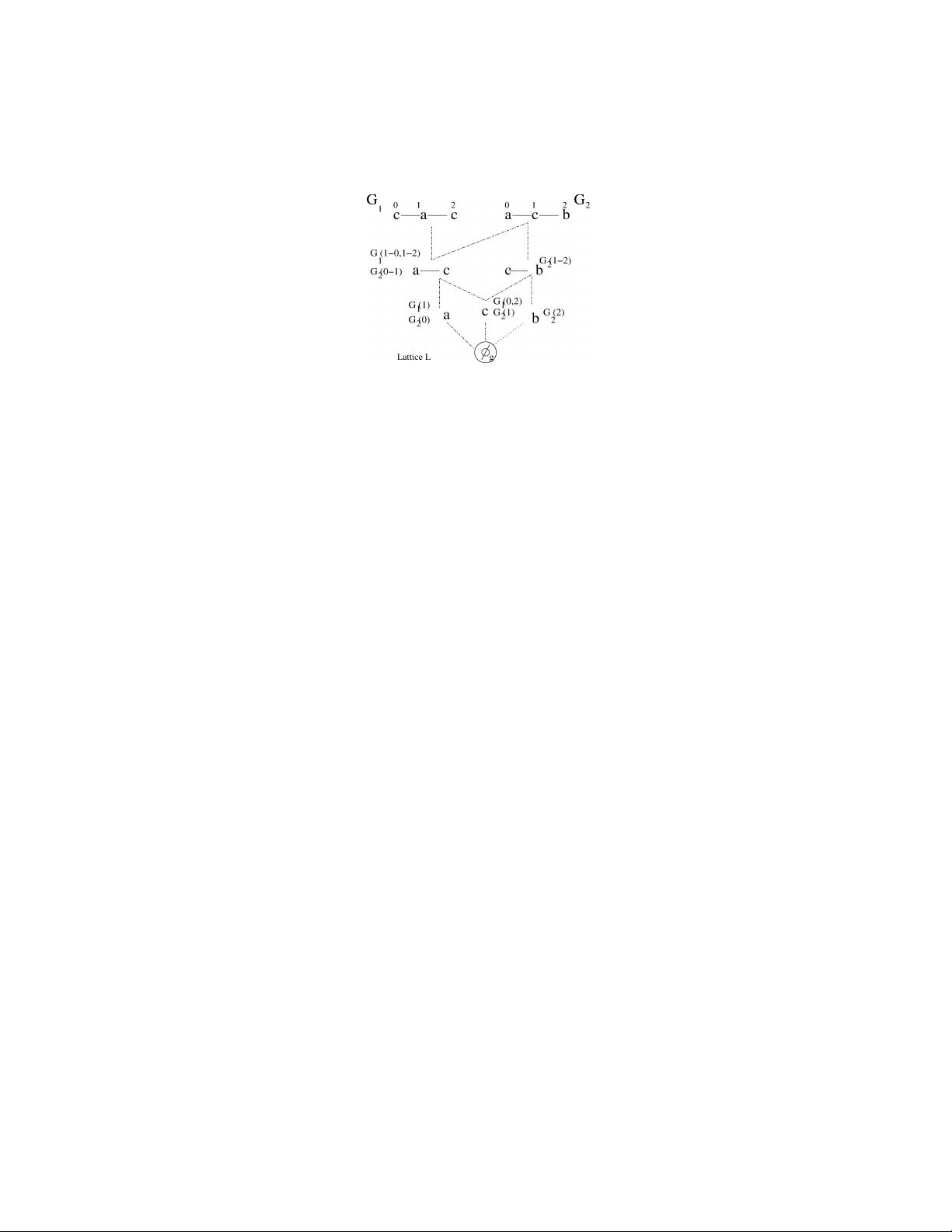
Fig. 4. Embedded model.
count of each node in the example lattice along with all the existing cuts in the
lattice L
1
and L
2
respectively.
Note that all isomorphic graphs of a graph g in the Lattice L
i
will thus have
the same support in D. However the subgraphs corresponding to the children
of each isomorphic form might be different. Also while one isomorphic form
of a subgraph might become a f (†)-node, the other might not. This is because
for one isomorphic form, all supergraphs might be frequent in a graph G
i
∈ D
while for another isomorphic form in G
j
∈ D there might exist an infrequent
supergraph making it a f (†)-node.
3.1 Lattice Representation Models
The lattice structure to the MARGIN algorithm can be represented using two
models, namely the replication model and the embedded model.
In the replication model (Figure 3), each subgraph g ⊂
graph
G
i
∈ D is repre-
sented exactly once in the lattice L
i
of G
i
as described in Section 3.
The embedded model is shown in Figure 4 for the graphs in Figure 2. In an
embedded model, the lattice L of the database D is common for all G
i
∈ D.All
isomorphic forms of any subgraph in D are represented using a single node in
the embedded model. Each node in the lattice L stores the information about
the occurrences of all of its isomorphic forms in the database. The bottommost
node corresponds to the empty graph φ
g
and the topmost nodes correspond to
the graphs in D. The graph a − c in Figure 2 has three isomorphic forms in
the database but will be represented exactly once along with the information
about its occurrence in G
1
at location 1 − 0and1− 2 and its occurrence in G
2
at location 0 − 1.
In the rest of the article, we proceed using the replication model unless
mentioned. With minor modifications the MARGIN algorithm can be applied
to the embedded model. A detailed discussion of the two models can be found
in Section 4.6.
4. THE MARGIN APPROACH
In 4.1, we provide the intuition behind the algorithm proposed to find the max-
imal frequent subgraphs. In Section 4.2, we present the MARGIN algorithm
ACM Transactions on Knowledge Discovery from Data, Vol. 4, No. 3, Article 10, Pub. date: October 2010.

剩余41页未读,继续阅读
114 浏览量
2020-01-03 上传
2019-10-24 上传
748 浏览量
2021-02-21 上传
129 浏览量
2021-05-30 上传
2021-02-06 上传

u010125929
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebDrive v16.00.4368: 简易易用的Windows风格FTP工具
- FirexKit:Python的FireX库组件
- Labview登录界面设计与主界面跳转实现指南
- ASP.NET JS引用管理器:解决重复问题
- HTML5 canvas绘图技术源代码下载
- 昆仑通态嵌入版ASD操舵仪软件应用解析
- JavaScript实现最小公倍数和最大公约数算法
- C++中实现XML操作类的方法与应用
- 设计编程工具集:材料重量快速计算指南
- Fancybox:Jquery图片轮播幻灯弹窗插件推荐
- Splunk Fitbit:全方位分析您的活动与睡眠数据
- Emoji表情编码资源及数据库查询实现
- JavaScript实现图片编辑:截取、旋转、缩放功能详解
- QNMS系统架构与应用实践
- 微软高薪面试题解析:通向世界500强的挑战
- 绿色全屏大气园林设计企业整站源码与多技术项目资源
