"Transformer详解:从Attention到NLP领域经典模型"
本课件是对论文“Attention is all you need”的导读与NLP领域经典模型Transformer的详解。通过介绍传统Seq2Seq模型及Attention,引入Transformer模型,并对其架构进行宏观微观的解读。然后详细介绍Transformer每一步的工作流程,最后给出Transformer在训练阶段的细节提要,以及推理阶段的解码策略等内容。
Seq2Seq模型是一种广泛应用于机器翻译、摘要生成等任务的神经网络模型。它由编码器和解码器两部分组成,通过编码器将输入序列编码成固定长度的向量,再通过解码器生成目标序列。而Attention机制则是一种用于提高神经网络对长距离依赖性建模能力的方法,它允许模型在生成每个目标词时,对输入序列中不同位置的信息赋予不同的注意力权重。
Transformer模型是一种基于自注意力机制的神经网络模型,它摒弃了传统的循环神经网络和卷积神经网络,完全由自注意力机制构成。Transformer模型的核心是多头注意力机制和前馈神经网络,它能够并行计算所有位置的输入表示,大大加速了模型的训练和推理过程。
在详细介绍了Transformer模型的架构之后,课件对Transformer每一步的工作流程进行了解读。首先是输入的嵌入表示,接着是位置编码的添加,然后是多头注意力机制的计算,再到前馈神经网络的处理,最后是残差连接和层归一化的操作。这些步骤共同构成了Transformer模型的核心计算流程,理解这些步骤对于深入理解Transformer模型至关重要。
在介绍了Transformer模型的工作原理之后,课件给出了Transformer在训练阶段的细节提要。这包括了损失函数的定义、参数的初始化、学习率的调度等内容。同时,课件还详细介绍了Transformer在推理阶段的解码策略,包括了贪婪解码、束搜索解码等常用方法。
总之,本课件通过对“Attention is all you need”论文的导读与NLP领域经典模型Transformer的详解,帮助学习者全面理解了Transformer模型的工作原理及其在训练和推理阶段的具体操作。对于从事自然语言处理和相关领域研究的同学和专业人士来说,本课件具有非常重要的参考价值。

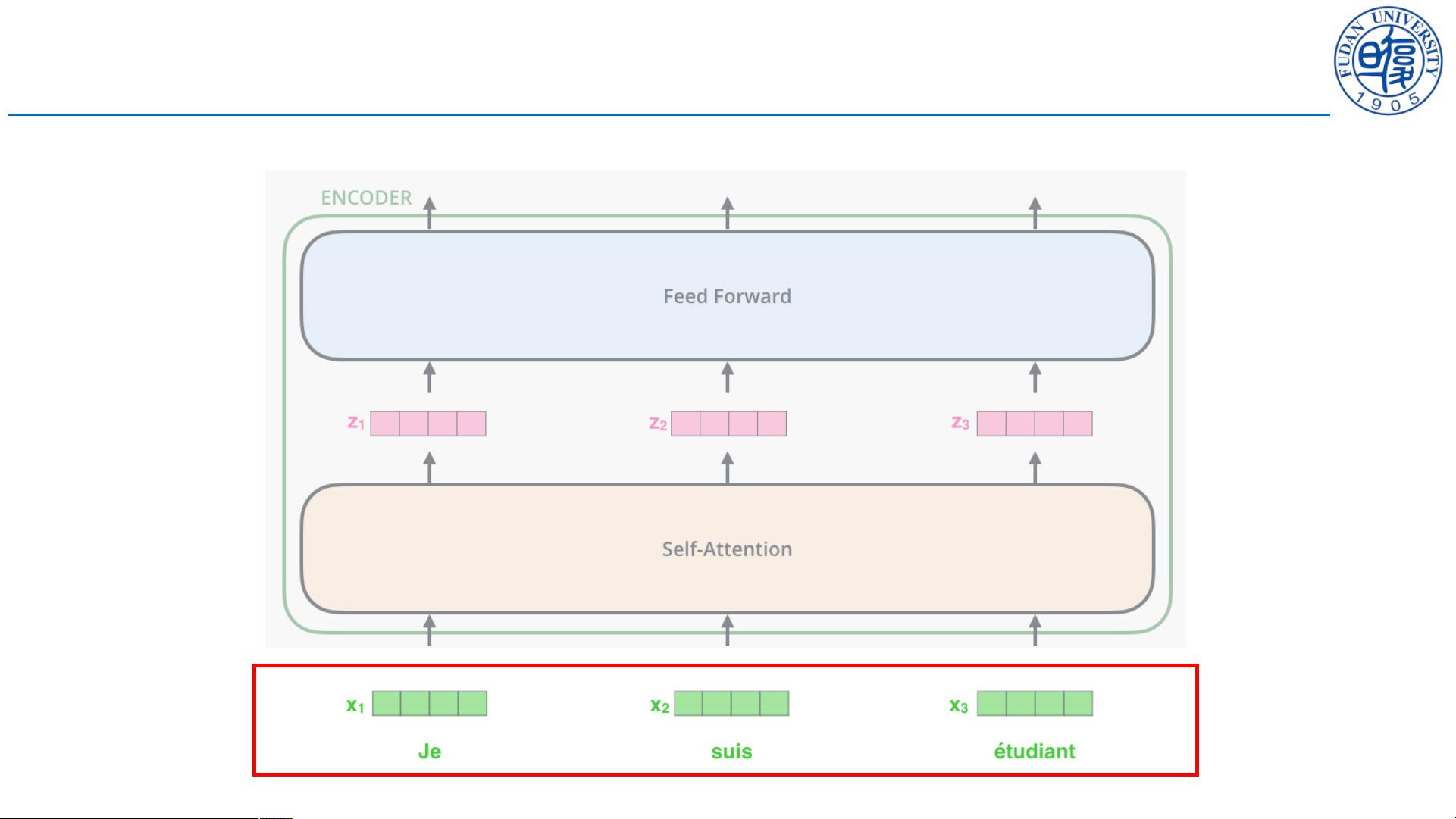
Transformer 架构
6
编码器
• 由N个block堆叠而成;
• 每个block有两层:
• Multi-Head Attention (Self-Attention)
+ Add (Residual Connection)
+ Norm (LayerNorm);
• Feed Forward
+ Add (Residual Connection)
+ Norm (LayerNorm);
• Block
1
~Block
N-1
的输出:输入到下个
Block;
• Block
N
的输出:输入到解码器的各层中。
解码器
• 由N个block堆叠而成;
• 每个block有三层:
• Masked Multi-Head Attention (Self-Attention)
+ Add (Residual Connection)
+ Norm (LayerNorm);
• Multi-Head Attention (Co-Attention)
+ Add (Residual Connection)
+ Norm (LayerNorm);
• Feed Forward
+ Add (Residual Connection)
+ Norm (LayerNorm);
• Block
1
~Block
N-1
的输出:输入到下个Block;
• Block
N
的输出:输入到后续的Linear层中。
剩余30页未读,继续阅读
2022-12-21 上传
2021-04-22 上传
2023-06-15 上传
2021-04-11 上传
2024-03-24 上传
2021-09-22 上传
2023-01-01 上传
2021-10-20 上传


_Meilinger_
- 粉丝: 815
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
