K-均值聚类与Otsu法:叶片病害故障区域高效检测
需积分: 9 16 浏览量
更新于2024-09-08
1
收藏 379KB PDF 举报
在当前全球粮食危机日益加剧的背景下,农作物叶片疾病成为食品工业中的一大挑战。本文提出了一种高效的方法,利用k-means聚类和Otsu阈值分割技术来解决这一问题。k-means算法是一种无监督机器学习方法,其基本原理是将数据集划分为若干个相互独立且内部特征相似的簇,每个簇中心代表该簇数据的典型特征。
首先,研究者们通过图像处理和分割步骤,从叶片的简单图像中提取关键信息。k-means算法在这个过程中扮演了关键角色,它通过迭代的方式将像素点分配到最近的质心(簇中心),直至所有数据点都被分配至一个合适的簇。这一步骤有助于识别叶片图像中的不同区域,包括正常和可能存在问题的部分。
Otsu方法则用于二值化图像,它自动寻找最佳阈值,将图像分为前景(异常或病变区域)和背景(正常区域)。结合k-means的结果,这两个步骤协同工作,可以精确地定位叶片上的病变区域,这对于后续的诊断和治疗决策至关重要。
通过计算正常区域与故障区域的比例,研究者能够评估叶片病变的严重程度,并据此预测是否有可能完全恢复。这种方法的优势在于其相对简单易行,且无需人工标注大量数据,适用于大规模的叶片图像分析,有助于农业生产者及时发现并采取针对性措施,减少损失,保障食品安全和产量。
这项研究为农业领域提供了一个实用的工具,帮助优化农作物管理,特别是在应对叶片疾病方面,展示了信息技术在解决实际问题中的重要作用。未来的研究可能进一步探索更高级的聚类算法或深度学习模型,以提高检测准确性和自动化水平。
Fault Area Detection in Leaf Diseases using k-means
Clustering
Subhajit Maity
1
,Sujan Sarkar
2
,Avinaba Tapadar
3
,Ayan Dutta
4
,Sanket Biswas
5
,
Sayon Nayek
6
,Pritam Saha
7
1,2,3,4,6,7
Department of Electronics and Communication Engineering,
5
Department of Computer Science Engineering
Jalpaiguri Government Engineering College
Jalpaiguri, West Bengal, India
smaity.jgec18@gmail.com
1
,sujansa19997@gmail.com
2
, avinaba.bwn@gmail.com
3
, dutta.ayan1998@gmail.com
4
,
sanketbiswas1995@gmail.com
5
,sayon.bwn@gmail.com
6
, pritamsaha125@gmail.com
7
Abstract— With increasing population the crisis of food is
getting bigger day by day. In this time of crisis, the leaf disease of
crops is the biggest problem in the food industry. In this paper,
we have addressed that problem and proposed an efficient
method to detect leaf disease. Leaf diseases can be detected from
simple images of the leaves with the help of image processing and
segmentation. Using k-means clustering and Otsu’s method the
faulty region in a leaf is detected which helps to determine proper
course of action to be taken. Further the ratio of normal and
faulty region if calculated would be able to predict if the leaf can
be cured at all.
Keywords—k-means clustering, image segmentation,
unsupervised learning, leaf disease, fault area detection, Otsu’s
method, background clipping
I. INTRODUCTION
Based on some research, by 2100 earth’s estimated
population is 11.2 billion, and with this day to day growing
issue, there is an argent need to expand the production of food.
As there is there very few number of cultivated lands left, to
feed the whole world we have to produce food beyond our
limit. It is also observed that crops, of worth several billion
dollars are losses annually due to corps diseases. But the main
problem is production of food slows down by the influence of
diseases. At this moment it will be a necessary step to
minimize the loss and to secure the corps by using
technological support. In most cases pests and diseases are
found on the leaves or branches of the plant.
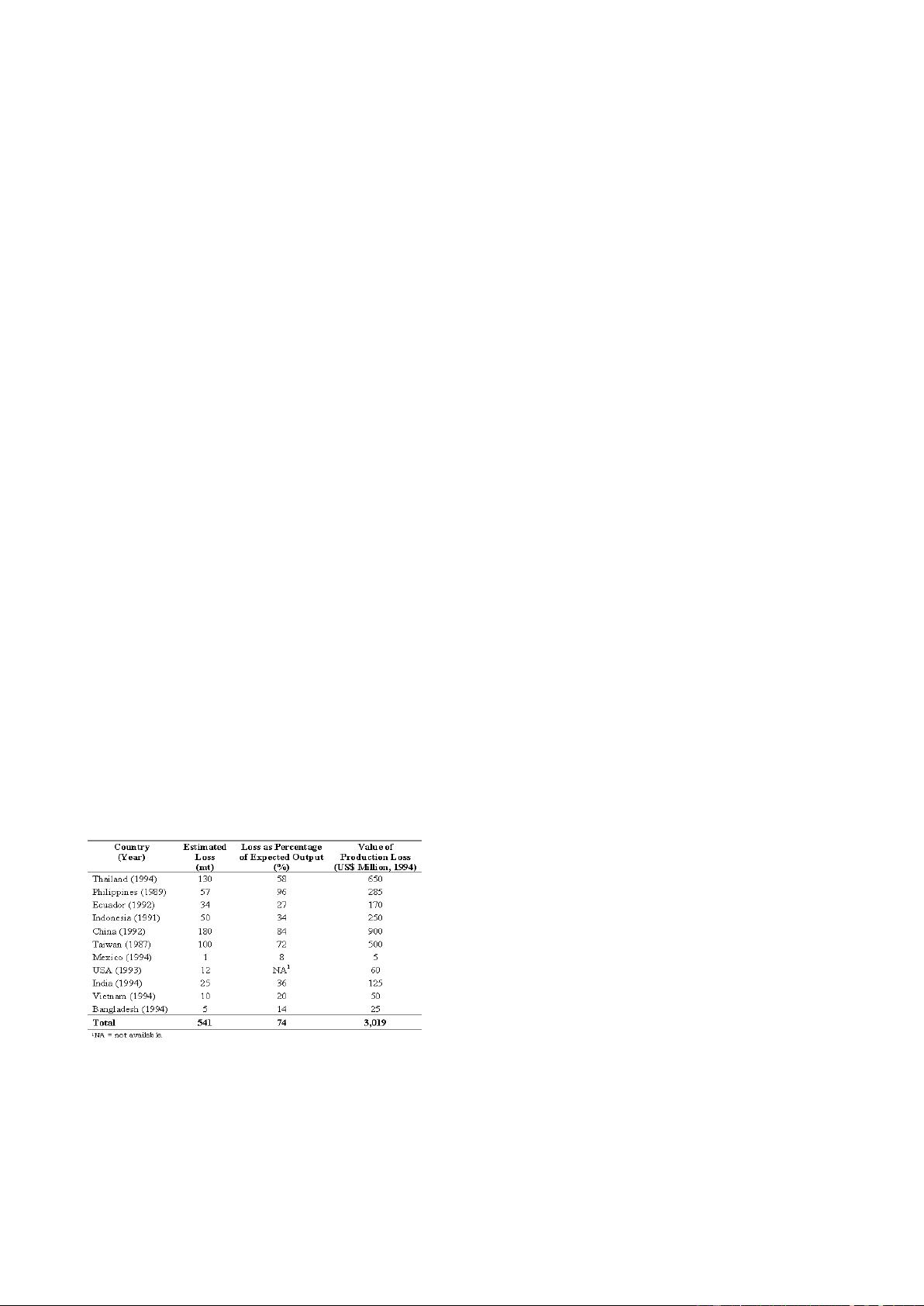
TABLE I . The Total loss of crop according to Food and Agriculture
Organization of the United Nations
Because of the compilation of visual patterns, enough
study is not done on these optically observed diseases, and for
that, the demand for more precise and sophisticated image
pattern discerning is increasing continuously. By using image
processing techniques, an image can be defined over two
dimensions (feasibly more), using that more precise image
pattern can be found, which plays an important role in crops
cultivation. There are a number of popular digital image
processing techniques are available like Hidden Markov
models, Image restoration, Anisotropic diffusion, Image
editing, Linear Filtering, Partial differential equations,
Independent Component analysis, Pixilation, Principal
Components Analysis, Wavelets, Self-organizing.
Classification of crop diseases using image
processing was researched by Ying[15].Ying said, “ Leaves
with marks must be carefully examined in order to carry out
intelligent diagnosis on the basis of image processing”.
Important methods of image processing :
• Image clipping: Based on marks , Classification of
leaves.
• Thresholding: Image segmentation into spot
background.
• Noise reduction: Noises are wiped out by medium
filter.
By experts, two different methods for the diagnosing of plant
diseases were put forward:
1. Graphical representation
2. Step by step descriptive methods
For the grading process of flue-cured tobacco leaves
image feature extraction is useful. In machine vision
techniques [16], automated investigation of flue-cured tobacco
leaves was mentioned. The above mentioned techniques were
used to solve the problems of feature extraction.
II. LITERATURE SURVEY
In 1979 and 1980 Punjab and Haryana, states of India, heavily
infected by a disease Xanthomonas oryzae, a bacterial disease
causes most destructive bacterial blight of rice which causes
almost 50% of worldwide annual yield loss[21,22].the
bacterial blight is most common disease on hybrid rice in
Zhejiang Province in China[23] reported by Cai and Zhong.
Another disease has been found in over 85
countries in the world, the name of the disease is called
Magnaporthe grisea (a fungal disease), It is capable of
destroying food which is enough to feed more than 60 million
people every year.
By image processing techniques and using neural
networks , pest damage in pip fruits can be detected, here
wavelets are used as a means by line detection, which was
下载后可阅读完整内容,剩余4页未读,立即下载
2019-03-03 上传
2017-09-02 上传
2022-06-26 上传
2023-06-30 上传
点击了解资源详情
点击了解资源详情
2023-07-29 上传
2024-03-24 上传
2023-03-20 上传

即将拥有六块腹肌的乐啊
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
