CSPN: 卷积空间传播网络提升深度估计精度与速度
94 浏览量
更新于2024-06-20
收藏 2.09MB PDF 举报
深度估计是计算机视觉领域的一个关键任务,特别是在增强现实、自动驾驶和机器人技术中,它涉及从单幅图像推断出每个像素与相机的距离。近年来,随着深度全卷积神经网络(FCN)的发展和大规模室内(如NYUv2[1])及室外(如KITTI[2])数据集的应用,深度估计的精度得到了显著提升。这些方法通常利用高级网络架构(如VGG[9]和ResNet[10])来捕捉全局场景布局和尺度,以及通过反卷积、跳跃连接或上采样等技术优化局部细节。
然而,尽管现有方法在整体性能上有所提高,但在个体像素的精度和结构一致性方面仍存在不足。例如,深度预测结果往往显得模糊,与图像中的结构(如物体边缘)不匹配(如图1所示)。为解决这个问题,Xinjing Cheng、Peng Wang和Ruigang Yang在他们的研究中提出了卷积空间传播网络(CSPN)[14]。
CSPN的核心思想是通过深度卷积神经网络(CNN)学习像素间的亲和关系,这是一种高效的空间传播模型,利用递归卷积操作在图像空间中进行信息传播。这种方法能够精细地调整深度估计,不仅提高了预测的清晰度,还能更好地适应图像结构。CSPN在两个深度估计任务上展现了其优势:一是优化现有深度估计技术(如SOTA)的输出质量,深度误差可减少超过30%,二是处理稀疏深度数据,通过深度样本嵌入传播过程,将其转化为密集深度图,这受到了LiDAR数据提供稀疏但准确深度测量的启发。
实验结果显示,CSPN在速度上也有所提升,相比于先前的SOTA方法,可以实现2至5倍的速度提升。CSPN的代码可在GitHub上的XinJCheng/CSPN项目中获取。这一创新方法展示了在深度估计领域的潜力,有望推动计算机视觉技术在实际应用中的进一步发展。
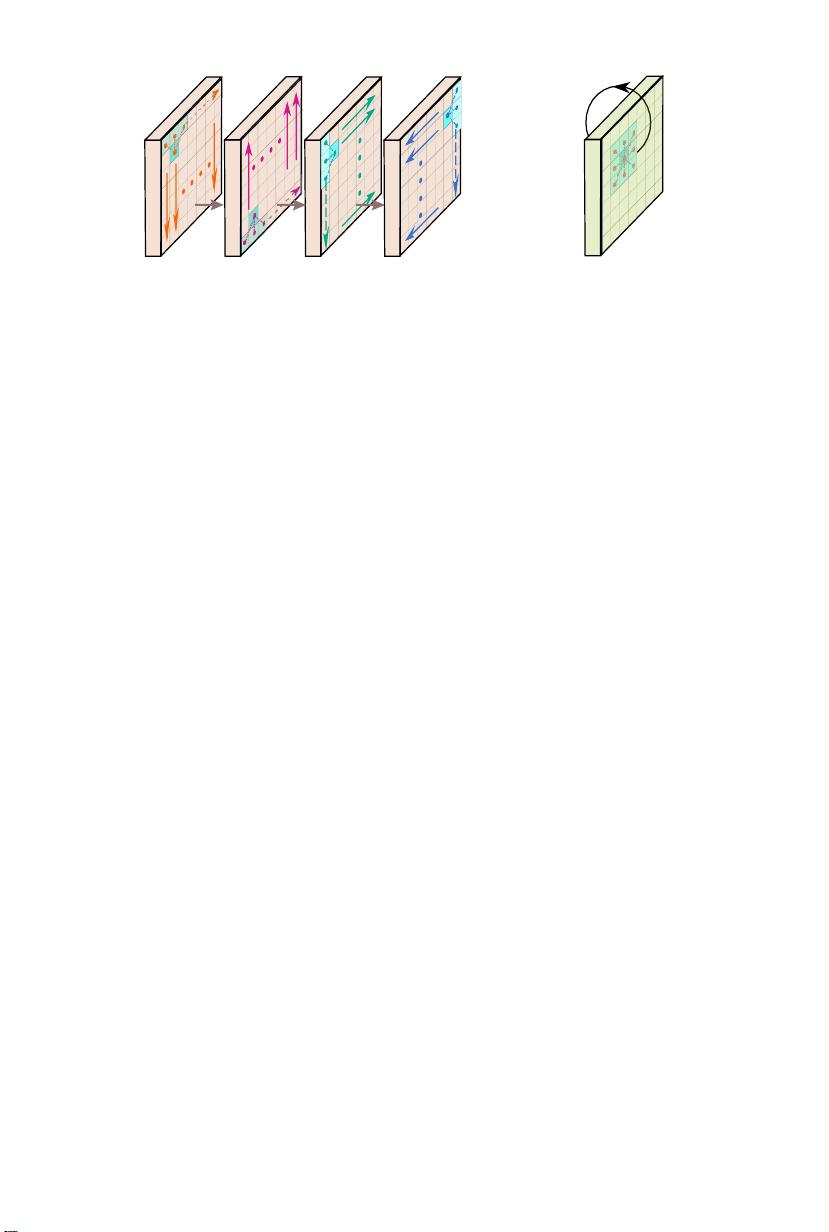
4
X. Cheng,P.Wang和R.杨
(a)
SPN
(
b
)
CSPN
图2:SPN[14]和CPSN中传播过程的比较。
解算器的频谱嵌入,它不能监督端到端的预测任务。Bertasius
等人。
[41]介绍了
一种随机游走网络,该网络优化了语义分割的像素亲和度然而,它们的亲和矩
阵需要来自真实稀疏像素对的额外监督,这限制了像素之间的潜在连接。Chen
等人。
[42]尝试对域变换的边缘图进行显式建模,以提高神经网络的输出。
与我们的方法最相关的工作是SPN[14],其中用于扩散的大型亲和矩阵的学
习然而,正如在SEC中提到的那样。1,深度增强通常需要局部上下文,可能没
有必要通过扫描整个图像来更新像素实验结果表明,我们提出的CSPN是更有效
的,并提供了更好的结果。
给定稀疏样本的深度估计。稀疏深度到密集深度估计的任务由于其在增强3D感
知方面的广泛应用而被引入机器人中[15]。与深度增强不同的是,所提供的深
度通常来自低成本LiDAR或一线激光传感器,从而仅在几百个像素中产生具有
有效深度的地图,如图所示1(f). 最近,Ma et al. [13]建议将稀疏深度图作为
基于ResNet [4]的深度预测器的额外输入,产生比仅使用图像输入的CNN深度输
出更好的结果。然而,输出结果仍然是模糊的,并且不满足我们在第2节中讨论
的深度要求。1. 在我们的情况下,我们直接将采样深度嵌入扩散过程中,其中
所有要求都得到了保持和保证。
其他一些作品直接将稀疏3D点转换为密集点,而无需图像输入[43,44,
45],而稀疏点的密度必须足够高以揭示场景结构,这在我们的场景中不可用。
3
我们的方法
我们将问题表述为各向异性扩散过程,扩散张量通过深度CNN直接从给定图像
中学习,这指导了输出的细化。
剩余18页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-09-19 上传
2021-09-25 上传
2021-09-19 上传
2021-09-20 上传
2021-09-25 上传
2021-09-19 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
