RNN与语言模型解析:cs224n课程笔记
需积分: 9 59 浏览量
更新于2024-07-18
收藏 1.62MB DOCX 举报
"cs224n学习笔记涵盖了Recurrent Neural Networks (RNN)和语言模型的深入讲解,包括RNN的训练技巧、梯度消失的推导、防止梯度爆炸的方法,以及在机器翻译中应用的五项改进。笔记还讨论了传统的n-gram语言模型,以及Bengio等人提出的基于词向量的深度学习模型。"
在计算机科学特别是自然语言处理领域,Recurrent Neural Networks (RNN)是一种广泛使用的神经网络结构,尤其适合处理序列数据,如文本。RNN的特点在于它们具有循环连接,允许信息在时间步之间传递,从而可以捕获序列中的长期依赖关系。然而,RNN在训练过程中面临一个问题,即梯度消失,这使得远距离的依赖关系难以学习。在本课程中,详细推导了梯度消失的现象,并通过Python代码进行了直观演示。为了解决这个问题,笔记中提到了梯度裁剪技术,这是一种有效防止梯度爆炸的方法。
语言模型是自然语言处理中的关键组件,它的任务是估算一个单词序列的概率。简单来说,语言模型可以评估一个句子是否在统计上是合理的。传统的n-gram模型是实现这一目标的常见方法,它基于马尔科夫假设,即当前单词的概率依赖于前面有限数量的单词。例如,BiGram模型考虑前一个单词,而TriGram模型则考虑前两个单词。随着n值增大,模型通常会更准确,但也会增加计算和存储成本,尤其是在大数据集上。
当数据不足或计算资源受限时,n-gram模型会遇到挑战。这时,平滑技术如Laplace平滑或Kneser-Ney平滑等被用来处理零频率问题。此外,Bengio等人提出的深度学习模型引入了词向量,用神经网络来捕捉上下文信息。该模型的网络架构包括输入层、隐藏层和输出层,其中隐藏层的激活函数通常是tanh,输出层通过softmax函数进行概率分布预测。这种模型能够学习到更复杂的上下文依赖,从而提高语言建模的性能。
cs224n的学习笔记提供了关于RNN和语言模型的宝贵洞察,不仅涵盖了基础理论,还涉及了实际应用中的挑战和解决方案,对于深入理解自然语言处理有极大的帮助。
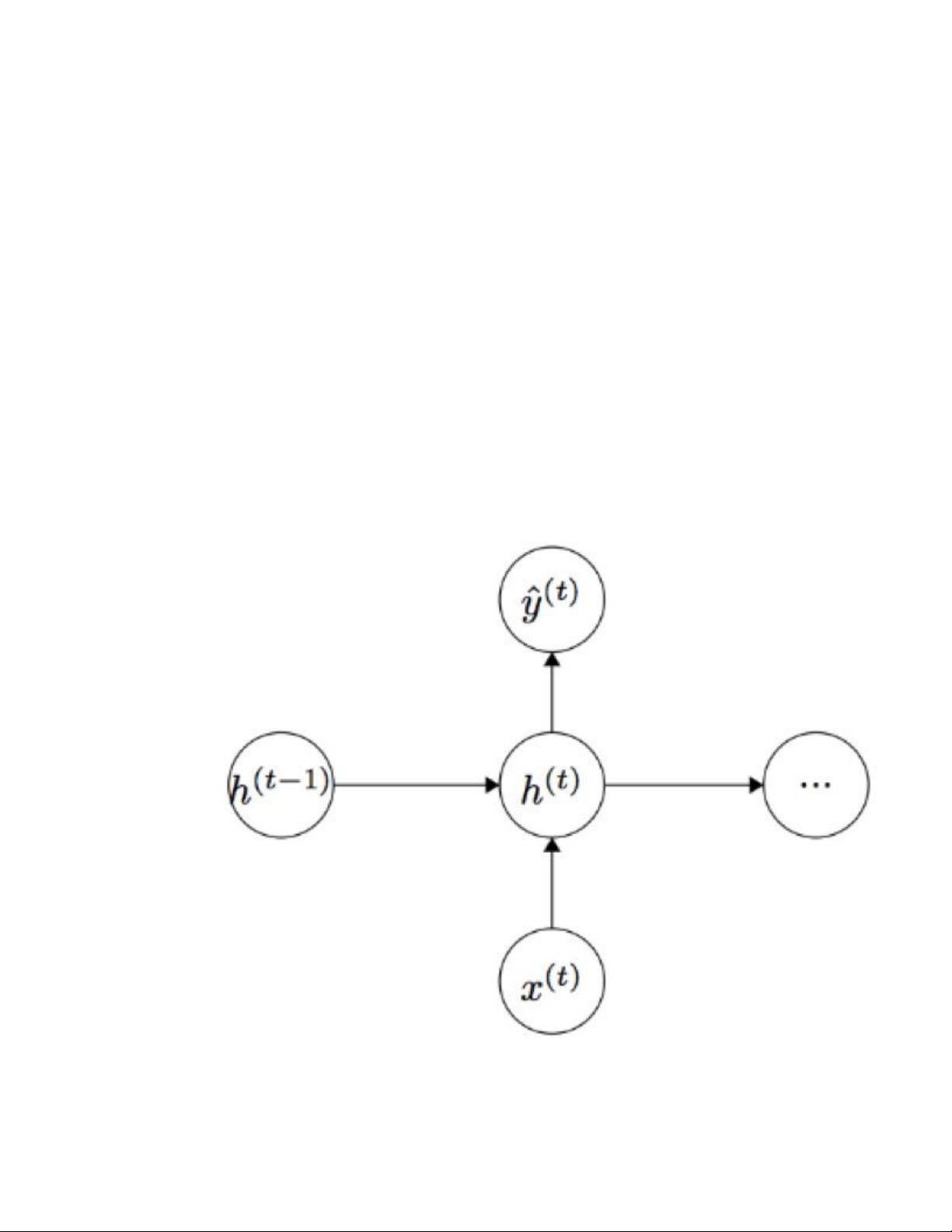
Whh∈RDh×DhWhh RDh×Dh∈ :用来 condition 前一个时间节点隐藏层特征表示
ht−1ht−1 的权值矩阵。
ht−1∈RDhht−1 RDh∈ : 前一个时间点 t−1t−1 的非线性激活函数的输出,
h0∈RDhh0 RDh∈ 是时间点 t=0t=0 时的隐藏层初始状态。
σ()σ(): 非线性激活函数(sigmoid)
y^t=softmax(W(S)ht)y^t=softmax(W(S)ht):在时刻 tt 时输出的整个词表 |V||
V| 上的概率分布,y^ty^t 是给定上文 ht−1ht−1 和最近的单词 x(t)x(t)预测的下一个单词。
其中 W(S)∈R|V|×DhW(S) R|V|×Dh∈ , y^∈R|V|y^ R|V|∈ 。
另外,这里的 W(hh)ht−1+W(hx)xtW(hh)ht−1+W(hx)xt 与拼接两个向量乘以权值
矩阵的拼接是一样的。
未 unroll 的网络:
剩余27页未读,继续阅读
2021-01-06 上传
2019-09-28 上传
2021-05-31 上传
2019-12-09 上传
2019-07-15 上传
2019-03-26 上传

yuxiaji
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
