深入理解Spark Core:组件与运行模式
需积分: 5 159 浏览量
更新于2024-07-06
收藏 5.15MB PDF 举报
"Spark Core是Apache Spark的核心组件,用于构建大数据分析的栈,支持与HDFS、S3、HBase、Cassandra等存储系统的集成,并能在Yarn、Mesos或独立模式下部署。Spark Core提供了RDD(弹性分布式数据集)基础,能够将数据转化为DAG(有向无环图),进而生成任务进行并行处理。此外,它还包括Shuffle过程、存储管理和交互式查询、实时数据处理以及批量数据分析等功能。社区对Spark进行了丰富的扩展,如Spark SQL、Spark Streaming、MLlib、GraphX、SparkR等,并有多个项目致力于在Spark上实现特定应用,如Hive on Spark、时间序列计算库等。各大公司如IBM、华为、Transwarp等也都在Spark基础上进行了优化和定制,以满足不同业务场景的需求。"
Apache Spark的Core组件是其核心,它提供了分布式计算的基础架构。Spark Core的主要职责包括任务调度、内存管理、错误恢复和与存储系统的交互。通过Spark Core,开发者可以构建高效的数据处理应用程序,尤其适合大规模数据的批处理和实时处理。
在Deploy模式方面,Spark Core支持多种部署方式,包括在YARN、Mesos集群管理系统上运行,以及独立的Standalone模式。这些部署选项使得Spark能够灵活地适应各种集群环境,提供资源管理和任务调度的功能。
RDD(弹性分布式数据集)是Spark Core的基础数据结构,它是不可变、分区的数据集合,能够在集群中的节点之间并行操作。RDD的创建可以通过从外部数据源加载或者通过现有RDD转换得到。RDD转换操作创建了一个DAG(有向无环图),这个图描述了数据处理的逻辑流程。DAG被分解为一系列Task,这些任务在工作节点上并行执行。
Shuffle是Spark中的一个重要阶段,它发生在RDD转换操作中,如join或reduceByKey,导致数据在节点间重新分布。这个过程通常涉及数据排序和网络传输,对于性能优化至关重要。
Spark Core的Storage子系统负责管理数据的存储级别,允许用户选择是否将数据持久化到磁盘,以及选择不同的缓存策略,如内存缓存或压缩。
Spark的交互式查询能力主要由Spark SQL提供,它允许用户使用SQL语法处理DataFrame和Dataset,极大地简化了大数据分析。Spark Streaming则处理实时数据流,支持微批处理模型,允许连续不断地处理流入的数据。
社区对Spark的贡献丰富了它的功能,比如MLlib提供了机器学习算法库,GraphX支持图计算,而SparkR则为R语言用户提供了Spark接口。此外,不同公司和项目如华为、Transwarp等在Spark基础上进行了优化,提升了SQL性能、增加了对特定数据源的支持,以及实现了更高级别的功能,如SQL事务和分析。
Spark Core作为Apache Spark的核心,是大数据处理的重要工具,它通过高效的分布式计算模型,支持多种部署方式,提供了丰富的数据处理和分析能力,且不断得到社区和企业的增强和定制,以满足不断发展的大数据需求。
© 2016 IBM Corporation
Deploy - Local
8
Spark Local模式:
--master = local[n]
val sc = new SparkContext("local", "SimpleApp")
Local vs Cluster mode:
1.
rdd.map(println)
rdd.collect().foreach(println)
rdd.take(100).foreach(println)
2.
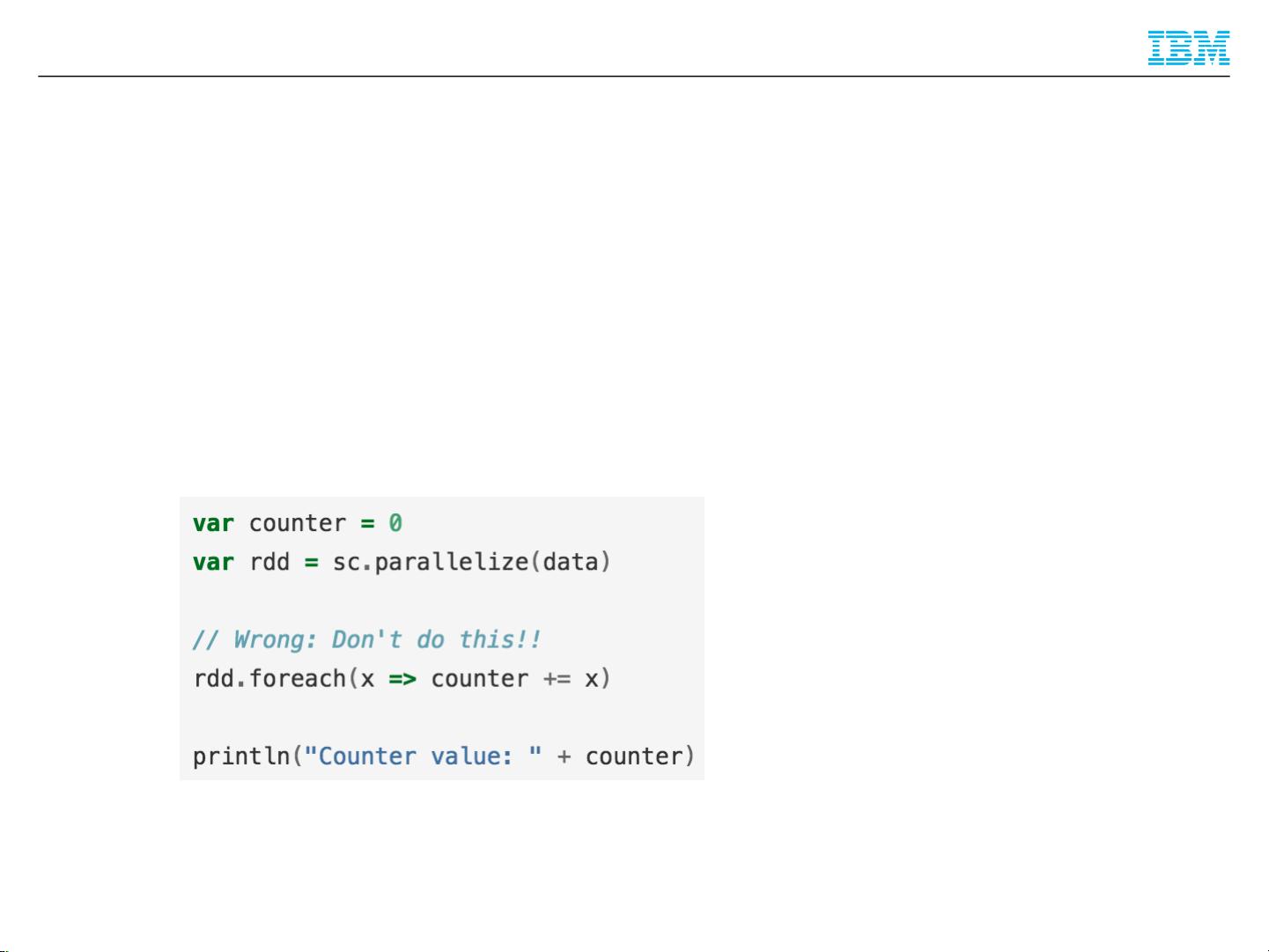
Closure(闭包):
The closure is those variables and methods which must be visible for the executor to
perform its computations on the RDD
This closure is serialized and sent to each executor.

剩余40页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-06-15 上传
2021-07-07 上传
2021-05-30 上传
116 浏览量
107 浏览量
106 浏览量

fzycool_2003
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索Eclipse下的SWT:跨平台GUI开发的解决方案
- 探索程序问题:echo、@、Goto等工具在垃圾信息中的应用与注意事项
- JasperReports终极指南:报表设计与开发
- 基于微分几何理论的混沌同步研究
- 微分几何驱动的飞机登机策略优化
- C# 将 DataTable 数据导出为 DBF 文件
- Eclipse教程:详解如何使用WTP开发Web服务
- GCC中文手册:Linux开发必备
- 揭秘嵌入式操作系统:必备知识点与应用优势
- PHP初学者指南:简易分页实现
- ExtJS2.0入门与实战教程:提升Web应用体验
- EasyJWeb:企业级Java Web开发框架解析
- 华为网络实验手册:打造计算机网络实战能力
- 理解IoC与Dependency Injection:控制反转与组件装配
- 主题重要性与专题搜索策略:魏本洁的研究
- Adobe Flex工作原理与首个应用开发简介
