大规模分布式文件系统:Google File System的设计与应用
《Google文件系统》(The Google File System) 是一项由 Sanjay Ghemawat、Howard Gobioff 和 Shun-Tak Leung 在 Google 公司设计并实现的分布式文件系统,旨在支持大规模分布式数据密集型应用。该系统的核心理念在于提供在廉价商用硬件上实现的高可用性和性能,特别针对那些对存储需求大、客户端众多且对数据处理效率有高要求的应用场景。
与早期的分布式文件系统有相似的目标,但 Google File System 的设计更多是基于对当前及未来工作负载和技术环境的深刻理解。这其中包括对传统设计选择的重新评估以及对全新设计理念的探索。系统的创新之处在于它能够适应Google内部服务的数据生成、处理需求,以及科研和开发项目中对大型数据集的需求。例如,最大的集群已经部署了数千台机器上的数千个磁盘,提供了数百太字节的存储空间,同时被数百个客户端并发访问,这显示出其在规模扩展和吞吐量方面的强大能力。
论文详细介绍了为分布式应用程序设计的文件系统接口增强功能,探讨了包括数据复制策略、数据一致性模型、元数据管理、负载均衡、故障恢复等多个关键设计元素。通过对微基准测试和实际应用的性能测量,证明了Google File System 在提供高效、稳定服务的同时,也实现了性能优化和成本效益的平衡。
Google File System 的成功不仅体现在满足了Google内部的存储需求,还推动了分布式存储技术的发展,对云计算时代的数据管理和处理方式产生了深远影响。它的设计原则和实践经验为其他企业级分布式文件系统,如Hadoop的HDFS,提供了重要的参考和借鉴。The Google File System 是一个革命性的技术成果,标志着分布式存储系统进入了一个全新的阶段。
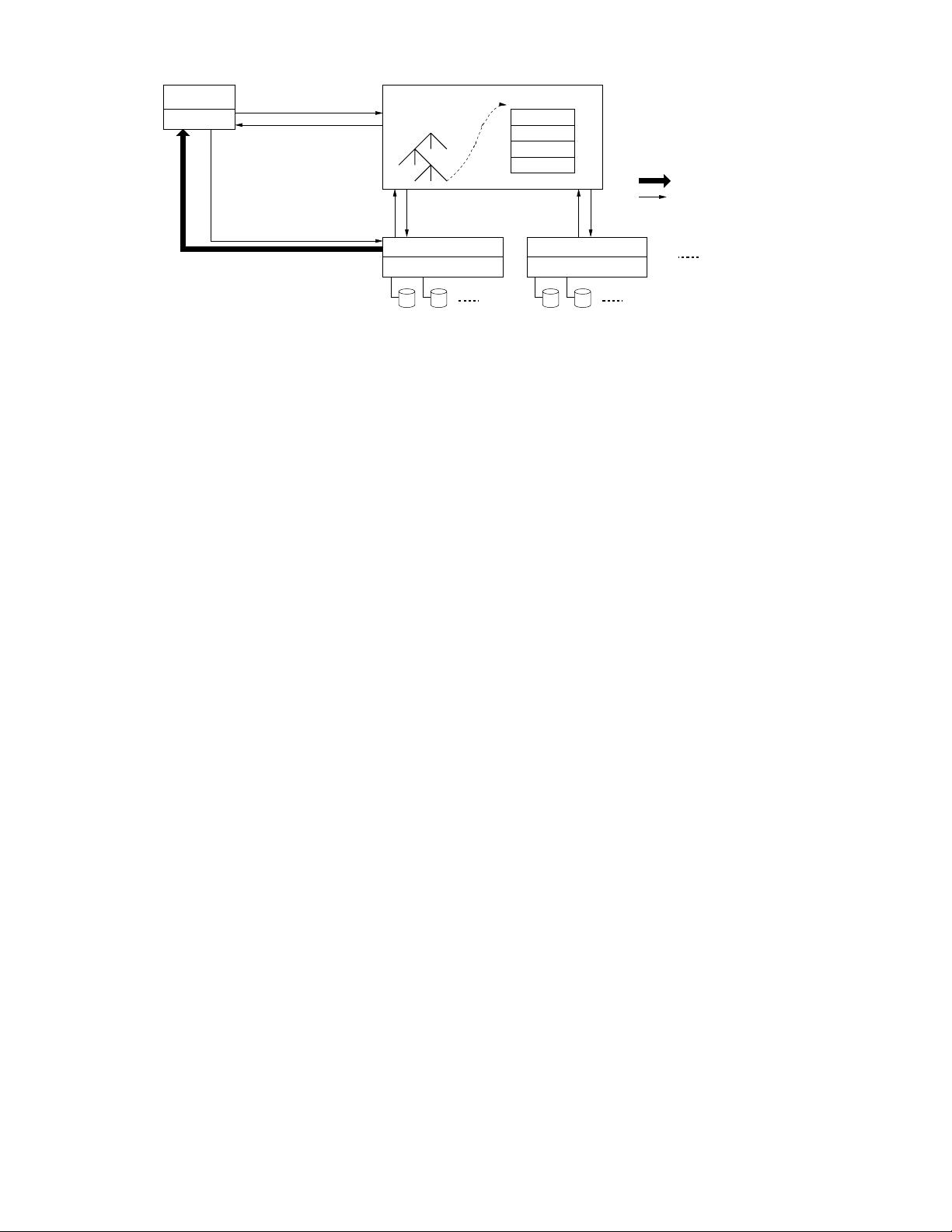
Legend:
Data messages
Control messages
Application
(file name, chunk index)
(chunk handle,
chunk locations)
GFS master
File namespace
/foo/bar
Instructions to chunkserver
Chunkserver state
GFS chunkserverGFS chunkserver
(chunk handle, byte range)
chunk data
chunk 2ef0
Linux file system Linux file system
GFS client
Figure 1: GFS Architecture
and replication decisions using global knowledge. However,
we must minimize its involvement in reads and writes so
that it does not become a bottleneck. Clients never read
and write file data through the master. Instead, a client asks
the master which chunkservers it should contact. It caches
this information for a limited time and interacts with the
chunkservers directly for many subsequent operations.
Let us explain the interactions for a simple read with refer-
ence to Figure 1. First, using the fixed chunk size, the client
translates the file name and byte offset specified by the ap-
plication into a chunk index within the file. Then, it sends
the master a request containing the file name and chunk
index. The master replies with the corresponding chunk
handle and locations of the replicas. The client caches this
information using the file name and chunk index as the key.
The client then sends a request to one of the replicas,
most likely the closest one. The request specifies the chunk
handle and a byte range within that chunk. Further reads
of the same chunk require no more client-master interaction
until the cached information expires or the file is reopened.
In fact, the client typically asks for multiple chunks in the
same request and the master can also include the informa-
tion for chunks immediately following those requested. This
extra information sidesteps several future client-master in-
teractions at practically no extra cost.
2.5 Chunk Size
Chunk size is one of the key design parameters. We have
chosen 64 MB, which is much larger than typical file sys-
tem block sizes. Each chunk replica is stored as a plain
Linux file on a chunkserver and is extended only as needed.
Lazy space allocation avoids wasting space due to internal
fragmentation, perhaps the greatest objection against such
a large chunk size.
A large chunk size offers several important advantages.
First, it reduces clients’ need to interact with the master
because reads and writes on the same chunk require only
one initial request to the master for chunk location informa-
tion. The reduction is especially significant for our work-
loads because applications mostly read and write large files
sequentially. Even for small random reads, the client can
comfortably cache all the chunk location information for a
multi-TB working set. Second, since on a large chunk, a
client is more likely to perform many operations on a given
chunk, it can reduce network overhead by keeping a persis-
tent TCP connection to the chunkserver over an extended
period of time. Third, it reduces the size of the metadata
stored on the master. This allows us to keep the metadata
in memory, which in turn brings other advantages that we
will discuss in Section 2.6.1.
On the other hand, a large chunk size, even with lazy space
allocation, has its disadvantages. A small file consists of a
small number of chunks, perhaps just one. The chunkservers
storing those chunks may become hot spots if many clients
are accessing the same file. In practice, hot spots have not
been a major issue because our applications mostly read
large multi-chunk files sequentially.
However, hot spots did develop when GFS was first used
by a batch-queue system: an executable was written to GFS
as a single-chunk file and then started on hundreds of ma-
chines at the same time. The few chunkservers storing this
executable were overloaded by hundreds of simultaneous re-
quests. We fixed this problem by storing such executables
with a higher replication factor and by making the batch-
queue system stagger application start times. A potential
long-term solution is to allow clients to read data from other
clients in such situations.
2.6 Metadata
The master stores three major types of metadata: the file
and chunk namespaces, the mapping from files to chunks,
and the locations of each chunk’s replicas. All metadata is
kept in the master’s memory. The first two types (names-
paces and file-to-chunk mapping) are also kept persistent by
logging mutations to an operation log stored on the mas-
ter’s local disk and replicated on remote machines. Using
a log allows us to update the master state simply, reliably,
and without risking inconsistencies in the event of a master
crash. The master does not store chunk location informa-
tion persistently. Instead, it asks each chunkserver about its
chunks at master startup and whenever a chunkserver joins
the cluster.
2.6.1 In-Memory Data Structures
Since metadata is stored in memory, master operations are
fast. Furthermore, it is easy and efficient for the master to
periodically scan through its entire state in the background.
This periodic scanning is used to implement chunk garbage
collection, re-replication in the presence of chunkserver fail-
ures, and chunk migration to balance load and disk space
31
剩余14页未读,继续阅读
2007-02-07 上传
125 浏览量
194 浏览量
146 浏览量
347 浏览量
119 浏览量

liushiyu_ss
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- AR0134摄像头寄存器配置及初始化流程
- PHP4Mono:Mono平台上PHP代码的编译解决方案
- 利用虚拟处理器提升Matlab 6.5集群计算性能
- KSAS学术博客:跨部门平台与多作者支持
- renovate-config:掌握JavaScript装修配置的工具
- 文件时间同步工具:如何保持文件时间不变
- Penelope:跨平台Web浏览器工具集成开源项目
- Beolabtoolbox V65:Matlab开发的并行执行工具包
- 个性化游戏光标:Сustom game cursors-crx插件功能介绍
- 编程分配:C语言自学成才年度回顾
- TQRichTextView:iPhone富文本视图控件源代码解析
- STM32数控稳压电源开发全资料分享
- depvault:跨语言的开源依赖管理器发布
- Superpowered Web Audio JS/WASM SDK:低延迟交互式音效开发
- 掌握1000句常用英语口语,提升国际化沟通能力
- 蓝点通用管理系统V20补丁安装与更新指南
