随机化快速排序算法详解
需积分: 0 58 浏览量
更新于2024-08-03
收藏 77KB DOCX 举报
"快速排序是一种高效且广泛应用的排序算法,由C.A.R. Hoare在1960年提出。其基本思想是采用分治策略,通过一趟排序将待排序序列划分为两个独立的部分,其中一部分的所有元素都比另一部分的所有元素小。然后对这两部分再分别进行快速排序,以此类推,直到整个序列有序。随机化快速排序是通过随机选取基准值来避免最坏情况,提高算法的平均性能。在Java中,快速排序通常包括选择基准值、分区和递归排序三个步骤。"
快速排序的主要步骤包括:
1. **选择基准值**:在原始算法中,一般选择数组的第一个元素作为基准值,但在随机化版本中,会随机选取一个元素作为基准。
2. **分区操作**(Partition):这个步骤是快速排序的核心,它将数组分为两部分,小于基准值的元素放在基准前面,大于基准值的放在基准后面。通过一系列比较和交换操作,最终确保基准值位于其最终位置,即所有小于它的元素在其左侧,所有大于它的元素在其右侧。
3. **递归排序**:对于分区后的两部分,分别进行快速排序。如果子数组只剩一个或零个元素,则排序结束;否则,重复上述过程。
在实际编码中,`partition`函数通常包含一个循环,比较每个元素与基准值,并根据比较结果交换元素的位置。随机化快速排序则在分区前添加一步,随机选择一个位置与基准位置交换,以避免最坏情况的发生。
快速排序的平均时间复杂度是O(nlogn),这得益于其高效的内部循环。最坏情况下,当输入数组已经部分排序或者基准值选取不当,可能导致每次划分只能减少一个元素,此时时间复杂度退化为O(n^2)。但随机化版本可以显著降低这种可能性。
空间复杂度方面,快速排序在递归过程中需要栈空间,因此空间复杂度为O(logn)。由于每次划分操作不需要额外的空间,快速排序在空间效率上相对较高。
Java实现中,通常会有一个名为`QuickSort`的类,包含`partition`方法以及递归调用的`quickSort`方法。`partition`方法用于执行分区操作,而`quickSort`方法负责递归调用,对子数组进行排序。提供的Java实例代码应该包含了这些功能,允许用户对数组进行快速排序。
快速排序广泛应用于各种场景,如数据处理、数据分析等,其高效性使得它成为许多编程语言的标准库中的默认排序算法。然而,对于特定类型的输入,例如大量重复元素的数组,其他算法如三向切分快速排序可能会有更优的表现。
随机化快速排序
一、概念及其介绍
快速排序由 C. A. R. Hoare 在 1960 年提出。
随机化快速排序基本思想:通过一趟排序将要排序的数据分割成独立的两部分,其中一部
分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进
行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
二、适用说明
快速排序是一种比较快速的排序算法,它的平均运行时间是 O(nlogn),之所以特别快是
由于非常精练和高度优化的内部循环,最坏的情形性能为 O(n^2)。像归并一样,快速排
序也是一种分治的递归算法。从空间性能上看,快速排序只需要一个元素的辅助空间,但
快速排序需要一个栈空间来实现递归,空间复杂度也为 O(logn)。
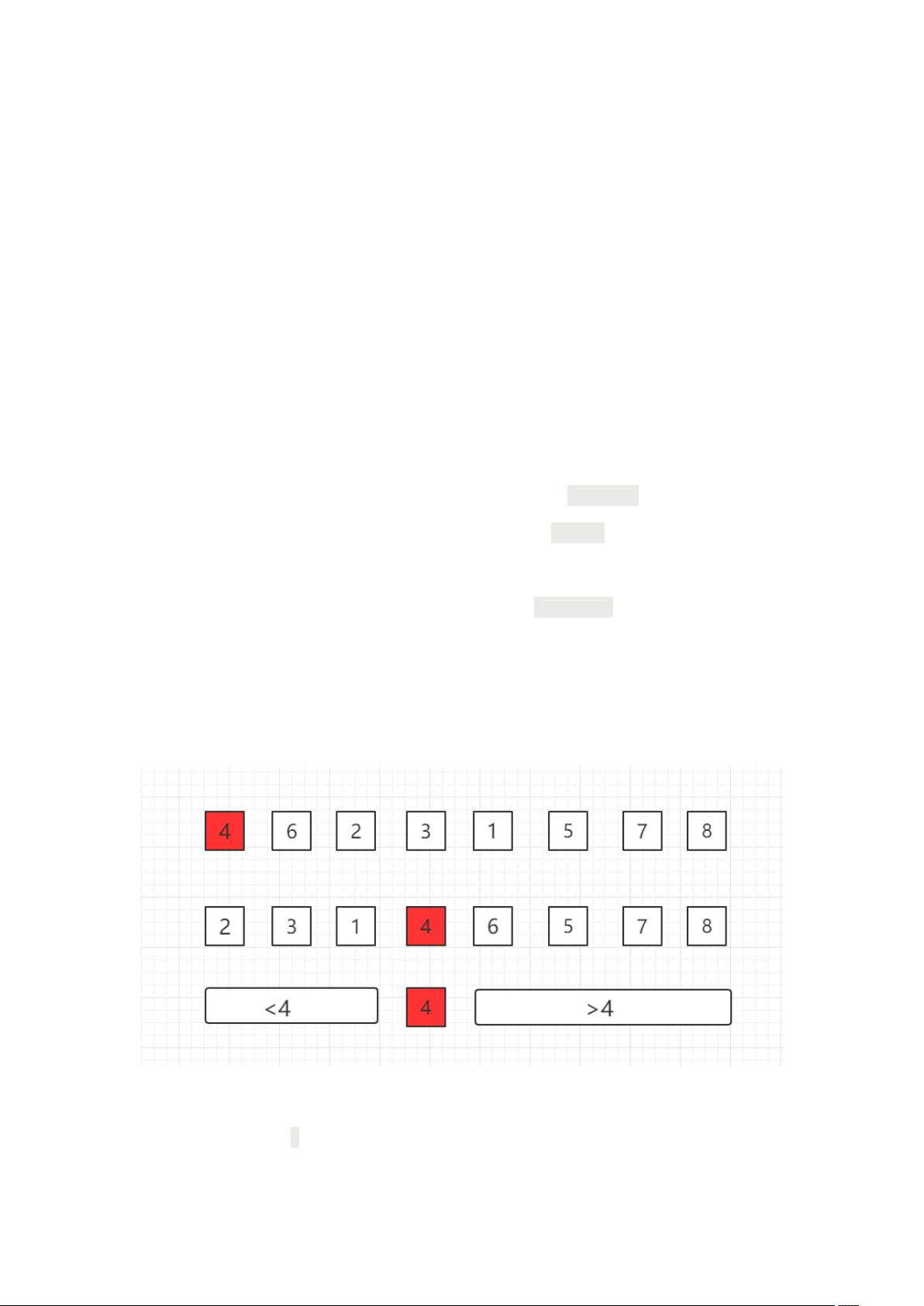
三、过程图示
在一个数组中选择一个基点,比如第一个位置的 4,然后把 4 挪到正确位置,使得之前的
子数组中数据小于 4,之后的子数组中数据大于 4,然后逐渐递归下去完成整个排序。
如何和把选定的基点数据挪到正确位置上,这是快速排序的核心,我们称为 Partition。
过程如下所示,其中 i 为当前遍历比较的元素位置:
下载后可阅读完整内容,剩余3页未读,立即下载
2023-12-04 上传
2022-11-12 上传
2022-07-11 上传
2022-11-24 上传
2023-12-07 上传
2021-11-23 上传
2020-04-16 上传
2022-07-11 上传
2022-06-11 上传

叫我Eric
- 粉丝: 2142
- 资源: 1546
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python库 | indy-plenum-dev-1.6.647.tar.gz
- 创业计划书-2008钢铁行业深度研究报告
- Meteor-Shenanigans:第一次玩Meteor.js
- Scandroid:适用于 Android 的免费扫描工具
- Amazon-Predictors:一组项目,可帮助您处理来自Amazon.com的各种数据集
- passport-challenge
- weixin071汽车预约维修系统+ssm(源码+部署说明+演示视频+源码介绍+lw).rar
- 土木工程毕业设计——【7层】5535平米框架行政指挥中心毕业设计(建筑、结构图、计算书、施组).zip
- python自动办公-02 批量生成PPT版荣誉证书.zip源码python项目实例源码打包下载
- 创业计划书-生猪生态养殖创业计划书
- SDRAM控制器,verilog语言编写
- oncapslock:一个 JavaScript 事件插件,用于检测用户何时使用 CAPS LOCK ON 打字
- Xenomai-GPIO-test:比较不同情况下嵌入式设备的中断延迟
- ASCStuff2018
- Dialog-Fragment-In-Android
- weixin021JAVA微信点餐小程序设计+ssm(源码+部署说明+演示视频+源码介绍+lw).rar
