深度学习与卷积稀疏编码:斯坦福大学讲义
需积分: 9 10 浏览量
更新于2024-07-15
收藏 6.47MB PDF 举报
深度学习与卷积稀疏编码:斯坦福大学讲义
本讲义是斯坦福大学关于深度学习(Deep Learning)与卷积稀疏编码(Convolutional Neural Networks in View of Sparse Coding)的讲座材料,由Jeremias Sulam、Yaniv Romano和Michael Elad共同完成。该课程讨论了Breiman的“两个文化”理论背景下,深度学习在生成模型(Generativemodeling)中的应用。生成模型涵盖了多种概率分布,如高斯(Gauss)、Wiener、拉普拉斯(Laplace)和伯努利(Bernoulli)等,以及费希尔(Fisher)分布,它们强调模型如何通过预测(Predictivemodeling)来描述数据。
在深度学习的卷积神经网络(CNN)中,生成模型部分展示了通过多层处理过程(forward pass)对图像元素(如眼睛、脸、鼻子和边缘)的识别。这些网络设计旨在解决Breiman提出的两个文化之间的桥梁问题,即将统计学上的生成和预测模型相结合。深度网络之所以有效,是因为它们能处理复杂的、分层次的组成函数,避免了维度灾难(curse of dimensionality),得益于局部性特征(locality of constituent functions)。
该模型的另一个关键特性是权重和前向激活值(pre-activations)假设为独立同分布(i.i.d Gaussian),这有助于优化过程。此外,过参数化(overparameterization)被证明对于深度学习的优化是有益的,它允许模型在训练数据上表现良好,即使在有噪声的情况下也能实现有效的推理。
整体而言,本讲义深入探讨了卷积神经网络作为深度学习的一种形式,其在生成模型框架下的工作原理、优势以及如何利用稀疏编码来提升模型的效率和性能。理解这些概念对于研究者和从业者来说至关重要,因为它们为构建更高效、更具解释性的AI系统提供了基础。
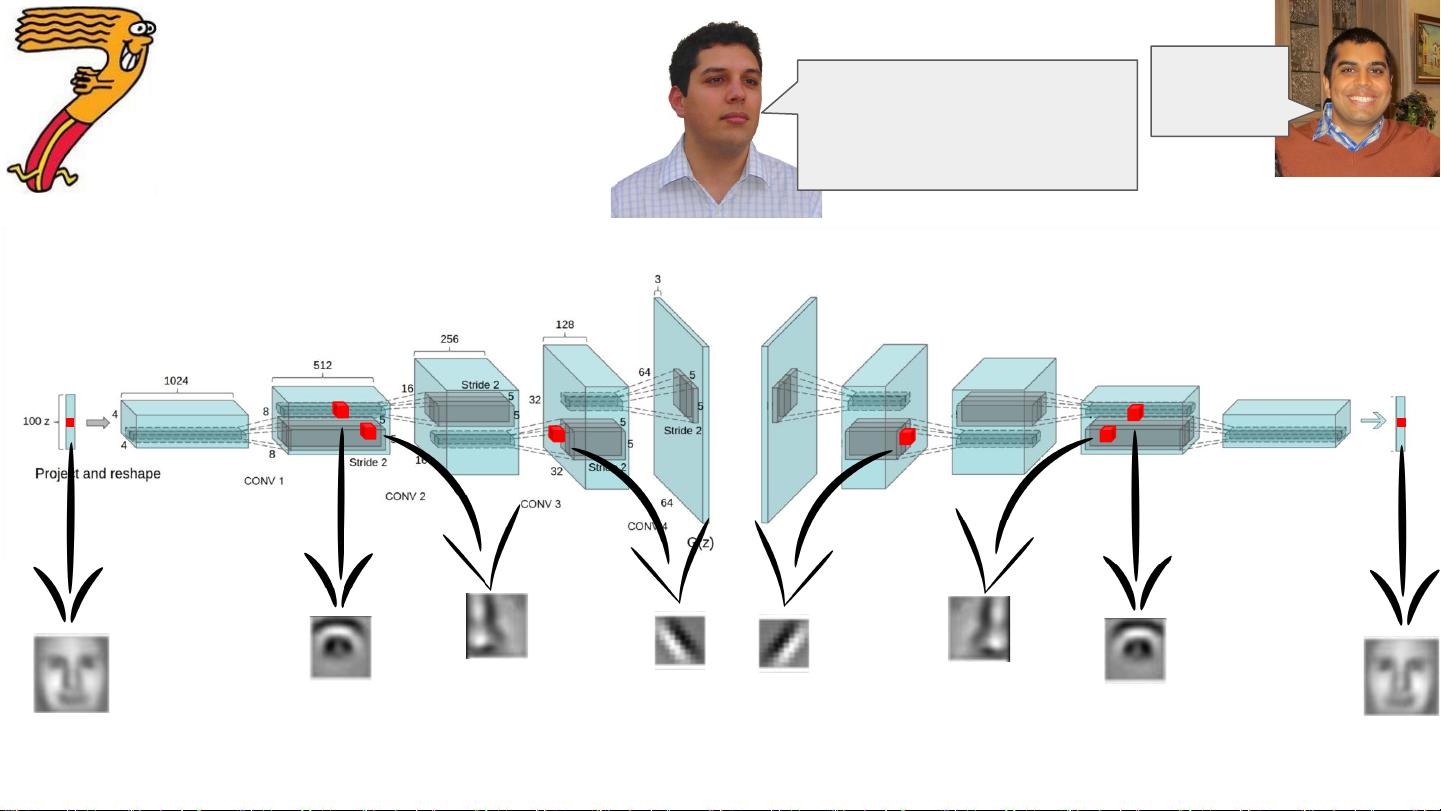
forward pass of CNN
eye
face
nose
edge
eye
face
nose
edge
generative model
Better training?
EM!
random features
k-means
matrix factorization

剩余69页未读,继续阅读
2009-03-13 上传
2022-01-13 上传
2022-01-05 上传
2021-08-11 上传
2022-01-13 上传
2022-01-13 上传
2022-07-14 上传
2021-09-17 上传

hzhdhz
- 粉丝: 1
- 资源: 35
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
