MySQL优化原理详解:逻辑架构与查询过程
37 浏览量
更新于2024-08-28
收藏 481KB PDF 举报
MySQL优化原理深入解析
MySQL的逻辑架构是理解数据库性能的关键。它主要分为三个层次:客户端层、服务层和存储引擎层。
1. 客户端层(Top Layer):
- 这一层并非MySQL的独特部分,包含了连接处理、授权认证、安全等通用功能。客户端与MySQL服务器进行交互时,首先建立连接,然后发送SQL语句请求。
- 客户端/服务端通信采用半双工协议,意味着发送和接收操作不能同时进行,这影响了大查询的处理,需要通过max_allowed_packet参数来限制单次数据包的大小。
2. 服务层(Middle Layer):
- MySQL的核心服务大部分集中在这一层,如查询解析、分析、优化等。这里的优化原理至关重要,因为优化器会根据查询的语法和表结构,选择最佳的执行计划以提高查询效率。
- 服务层还实现了跨存储引擎的功能,例如存储过程、触发器和视图,这些允许在不同的存储引擎之间共享逻辑和功能。
- API接口使得服务层与存储引擎交互,统一对外接口,隐藏了不同存储引擎的底层差异,提高了灵活性和可扩展性。
3. 存储引擎层(Bottom Layer):
- 这是数据存储和检索的核心区域,不同的存储引擎如InnoDB、MyISAM等各有优缺点,如InnoDB支持事务处理,而MyISAM则牺牲了事务性以换取更快的读取速度。
- 存储引擎层直接与磁盘打交道,决定了数据的物理布局和访问性能。
查询优化的核心在于遵循一些原则,帮助MySQL优化器按预期方式工作。理解查询过程,如先检查查询缓存、解析查询、选择合适的执行计划,以及如何处理大查询和结果分包,能显著提升数据库的响应速度。
查询缓存是优化的一部分,它可以存储已解析过的查询结果,加快后续相同查询的执行速度。然而,如果查询条件发生变化,缓存中的结果可能不再适用,这时缓存会被清空或失效,因此查询缓存并非总是理想解决方案,需根据实际情况权衡使用。
掌握MySQL的逻辑架构和优化原理,对于提升应用程序的性能和管理数据库资源具有重要意义,同时也需要开发者在实际开发中灵活运用这些原理,以适应不断变化的需求和优化挑战。
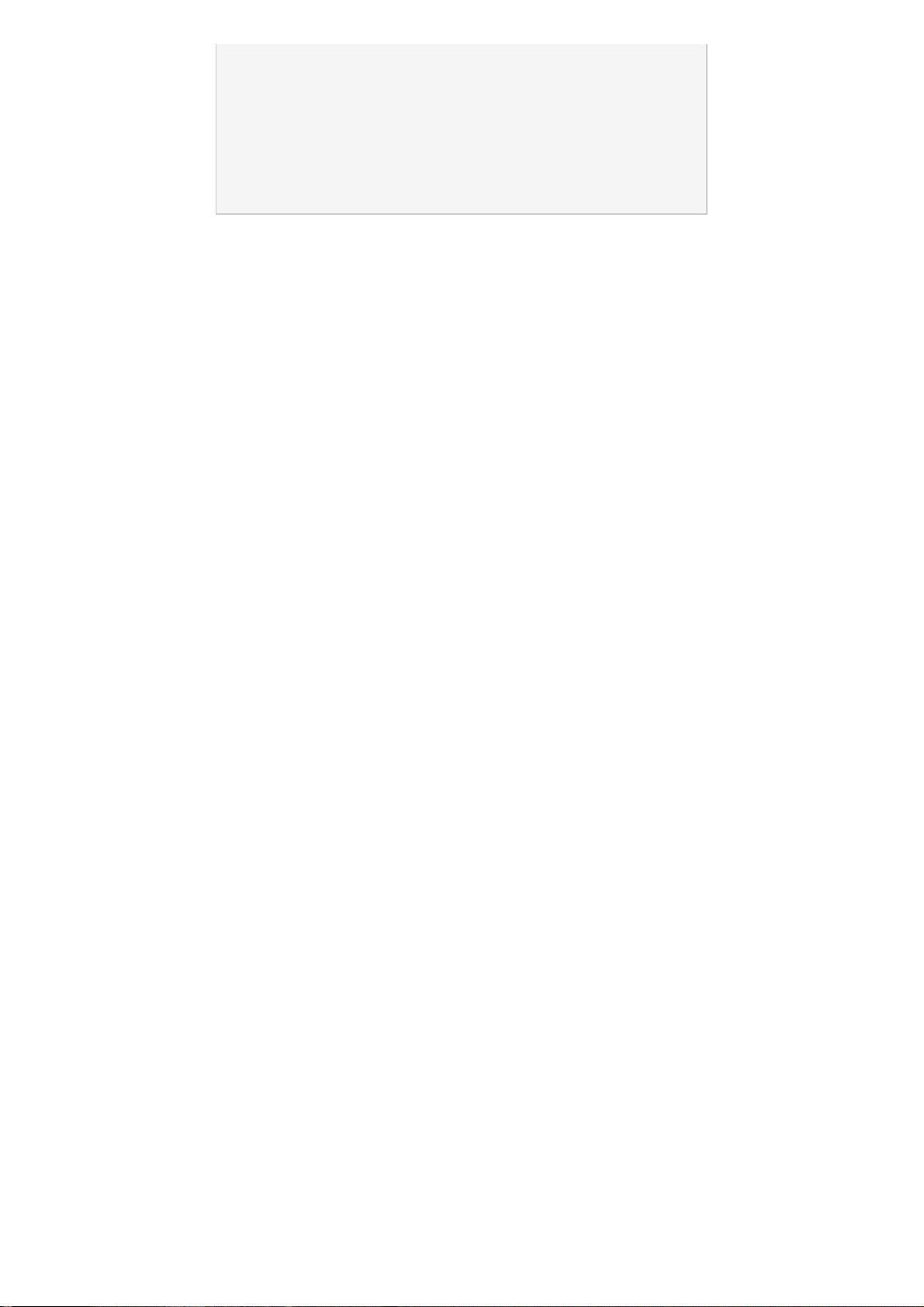
mysql> select * from t_message limit 10;
...省略结果集
mysql> show status like 'last_query_cost';
+-----------------+-------------+
| Variable_name | Value |
+-----------------+-------------+
| Last_query_cost | 6391.799000 |
+-----------------+-------------+
示例中的结果表示优化器认为大概需要做6391个数据页的随机查找才能完成上面的查询。这个结果是根据一些列的统计信息
计算得来的,这些统计信息包括:每张表或者索引的页面个数、索引的基数、索引和数据行的长度、索引的分布情况等等。
有非常多的原因会导致MySQL选择错误的执行计划,比如统计信息不准确、不会考虑不受其控制的操作成本(用户自定义函
数、存储过程)、MySQL认为的最优跟我们想的不一样(我们希望执行时间尽可能短,但MySQL值选择它认为成本小的,但
成本小并不意味着执行时间短)等等。
MySQL的查询优化器是一个非常复杂的部件,它使用了非常多的优化策略来生成一个最优的执行计划:
重新定义表的关联顺序(多张表关联查询时,并不一定按照SQL中指定的顺序进行,但有一些技巧可以指定关联顺序)
优化MIN()和MAX()函数(找某列的最小值,如果该列有索引,只需要查找B+Tree索引最左端,反之则可以找到最大值,具体
原理见下文)
提前终止查询(比如:使用Limit时,查找到满足数量的结果集后会立即终止查询)
优化排序(在老版本MySQL会使用两次传输排序,即先读取行指针和需要排序的字段在内存中对其排序,然后再根据排序结
果去读取数据行,而新版本采用的是单次传输排序,也就是一次读取所有的数据行,然后根据给定的列排序。对于I/O密集型
应用,效率会高很多)
随着MySQL的不断发展,优化器使用的优化策略也在不断的进化,这里仅仅介绍几个非常常用且容易理解的优化策略,其他
的优化策略,大家自行查阅吧。
查询执行引擎
在完成解析和优化阶段以后,MySQL会生成对应的执行计划,查询执行引擎根据执行计划给出的指令逐步执行得出结果。整
个执行过程的大部分操作均是通过调用存储引擎实现的接口来完成,这些接口被称为handler API。查询过程中的每一张表由
一个handler实例表示。实际上,MySQL在查询优化阶段就为每一张表创建了一个handler实例,优化器可以根据这些实例的接
口来获取表的相关信息,包括表的所有列名、索引统计信息等。存储引擎接口提供了非常丰富的功能,但其底层仅有几十个接
口,这些接口像搭积木一样完成了一次查询的大部分操作。
返回结果给客户端
查询执行的最后一个阶段就是将结果返回给客户端。即使查询不到数据,MySQL仍然会返回这个查询的相关信息,比如该查
询影响到的行数以及执行时间等等。
如果查询缓存被打开且这个查询可以被缓存,MySQL也会将结果存放到缓存中。
结果集返回客户端是一个增量且逐步返回的过程。有可能MySQL在生成第一条结果时,就开始向客户端逐步返回结果集了。
这样服务端就无须存储太多结果而消耗过多内存,也可以让客户端第一时间获得返回结果。需要注意的是,结果集中的每一行
都会以一个满足①中所描述的通信协议的数据包发送,再通过TCP协议进行传输,在传输过程中,可能对MySQL的数据包进
行缓存然后批量发送。
回头总结一下MySQL整个查询执行过程,总的来说分为6个步骤:
客户端向MySQL服务器发送一条查询请求
服务器首先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段
服务器进行SQL解析、预处理、再由优化器生成对应的执行计划
MySQL根据执行计划,调用存储引擎的API来执行查询
将结果返回给客户端,同时缓存查询结果
性能优化建议
看了这么多,你可能会期待给出一些优化手段,是的,下面会从3个不同方面给出一些优化建议。但请等等,还有一句忠告要
先送给你:不要听信你看到的关于优化的“绝对真理”,包括本文所讨论的内容,而应该是在实际的业务场景下通过测试来验证
你关于执行计划以及响应时间的假设。
剩余11页未读,继续阅读
点击了解资源详情
2024-11-27 上传
2024-11-27 上传
2024-11-27 上传
2024-11-27 上传
2024-11-27 上传
2024-11-27 上传
2024-11-27 上传

weixin_38746293
- 粉丝: 156
- 资源: 1041
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
