优化多层网站系统响应时间的CTP调度策略
需积分: 5 8 浏览量
更新于2024-08-26
收藏 2.88MB PDF 举报
本文主要探讨了一种名为"CTP(Cloud Tier Placement)"的调度策略,针对多层网站系统中的响应时间波动问题提供解决方案。在云计算环境下,服务质量(QoS)和资源利用率的优化是核心关注点。然而,实际应用中,许多多层应用程序在资源使用高峰期经常面临响应时间的大幅度波动,这严重影响了用户体验。
CTP策略的提出旨在深入分析这种响应时间的细粒度变化,并设计一种有效的调度机制来平滑这些波动。作者团队,由来自山东大学和南洋理工大学的研究人员组成,包括Wenbin Zhang、Yuliang Shi、Lei Liu等人,共同研究了这一挑战。他们对响应时间的波动原因进行了细致的研究,特别关注了在提供高质量服务时可能引发的问题。
文章首先介绍了当前多层网站系统中响应时间波动的普遍现象,然后阐述了研究背景和意义,即需要一种能够动态调整资源分配,确保服务稳定性的策略。CTP策略采用了精细粒度的分析方法,通过实时监控系统性能,识别出响应时间波动的关键因素,如负载分布、服务器繁忙程度等。
策略的核心在于智能地将工作负载分布在不同的层级(云层或服务器层次),以平衡各层的负载,防止某一层过载导致响应时间剧增。通过动态调整服务实例的部署位置(即云 tier placement),CTP能够在高峰期分散流量,降低单个节点的压力,从而实现整体响应时间的平稳。
研究过程包括理论模型建立、实验设计以及对不同调度策略的对比分析。结果显示,CTP相较于传统调度方法在减少响应时间波动、提高系统稳定性方面表现显著,有助于提升多层网站系统的整体性能。
此外,文章还提到了研究的时间线,从2016年1月接收修订稿到5月接受并在线发表,展示了研究的严谨性和及时性。关键词包括“响应时间”、“波动”、“细粒度分析”和“调度政策”,这些都是理解CTP策略核心要素的关键术语。
CTP是一种创新的调度策略,对于优化多层网站系统的响应时间和资源利用率具有重要的实践价值。通过深入研究响应时间波动的原因和实施策略,CTP为云计算环境下的多层应用提供了更加稳健的服务保障。
200 W. Zhang et al. / Microprocessors and Microsystems 47 (2016) 198–208
Fig. 2. End-to-end response time distribution of the system in workload 140 0; the average CPU utilization of the bottleneck server is 90% in 10 minutes runtime experiments.
Fig 3 (b) and 3(c) show the average system response time
and throughput aggregated at 100 ms and 10 s time granularities
respectively. Fig 3 (b) shows both the system response time and
throughput present large fluctuation while such fluctuations are
highly blurred when 10 second (10 second or even longer control
interval is frequently used in automatic self-scaling systems [17,
18, 19, 20] ) time granularity is used ( Fig 3 (c)). The standard
deviations of throughput and response time in Fig 3 (b) are 10.46
and 194.08 respectively, at the same time the standard deviations
of them are 19.52 and 297.35 respectively in Fig 3 (c).
(2) Fine-Grained CPU Utilization Analysis: we analysis the CPU
utilization of each tier through fine-grained analysis. The
system CPU utilization may be low at a coarse time gran-
ularity, it fluctuates significantly if observed at a finer time
granularity. And we find the CPU utilization of DB tier is the
highest among these three tiers.
Fig 3 (d) shows the CPU utilization of every tie. In this result we
see that the CPU utilization of web-tier or app-tier is about 40%
and the maximum is not to 80% while such utilization of DB-tie is
about 80% and most of them have to 90%, even some has reached
to 100%. From Fig 3 (d) we can see that the MySQL CPU frequently
reaches 90% even 100% utilization if monitored at 1 s granularity
while such CPU saturation disappears if 10 s time granularity is
used in Fig 3 (e).
At the workload of 140 0 users, through fine-grained analysis we
find DB-tier is bottleneck tier, and we do deep analysis of tracing
requests to find the reason that causes large response time fluctu-
ations in section 3.2 .
3.2. Finding causes through tracing requests
In this section, we introduce our approach to logging, then di-
agnosing anomalous categories based on collected request data,
and identifying cause of large response time fluctuation eventually.
(1) Tracing Request Data : We do some modification on RUBiS
source program that we add a class. This class is mainly
responsible for collecting request data when a sampled re-
quest sent by client.
Table 1
Tracing log formats and examples.
UserSessionID PageID VistCount StartTime EndTime ResonseTime
UserSession274 15 4 31 :31.7 31 :32.0 301
UserSession300 5 3 31 :31.8 31 :31.8 59
The data structure of a tracing log is shown in Table 1 , which
contains six items. UserSessionID indicates the client who send re-
quest. PageID indicate the page which client visit. VistCount record
the times of this page is visited by this client from it enters the
system to leave, this filed will automatic add 1 when this page is
visited. StartTime records the time of the request is sent. EndTime
record the time of the request is responded. ResonseTime record the
request processing time.
UserSessionID should be unique for every client. A session is a
sequence of interactions for the same customer. For each customer
session, the client emulator opens a persistent HTTP connection to
the Web server and closes it at the end of the session. A client is
only one UserSessionID , but one client can send more than one re-
quests. There are 27 kinds of request in RUBiS, and one page refers
to one request, PageID is from 0 to 26. Different number of pageID
represents the different request.
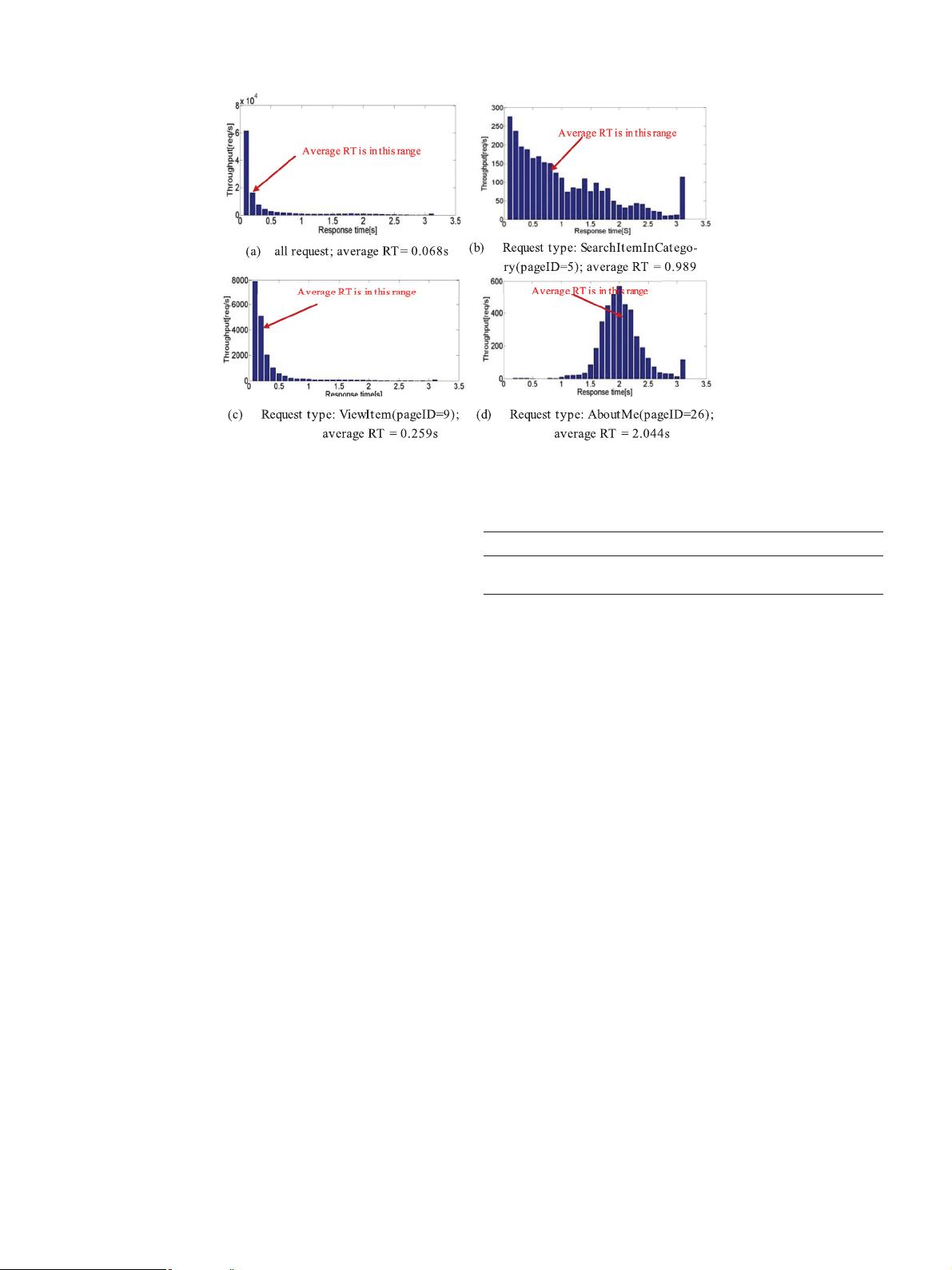
(2) Clustering Request Data to Diagnose Anomalous Categories: Af-
ter collect all data as described in Section 3.1 , we cluster
such data base on request-oriented way. The request with
the same PageID will be clustered into one category.
Definition 1. Request: for each query submitted to the DBMS we
assume it belongs to a specific query type Q
K
, where 1 ≤K ≤M and
M is the total number of query types. A request comprises zero or
more instances of each query type.
Definition 2. Request Type: the requests that are composed of the
same query type belong to one request type. In our experiment the
requests that own the same pageID belong to one request type.
Definition 3. Request Category: Let C be a set of request cate-
gories, a category C
j
is defined as a vector < T
Ij,
,…,T
Nj
> , where T
ij
denotes the response time of the ith request when sorting the re-
quest order by StartTime of the request type j, and 0 ≤ j ≤ 26.
剩余10页未读,继续阅读
2021-03-15 上传
2023-10-21 上传
2021-05-07 上传
2021-03-11 上传
2021-06-10 上传
2021-06-17 上传
2021-05-24 上传

weixin_38682279
- 粉丝: 9
- 资源: 889
 我的内容管理
展开
我的内容管理
展开







最新资源
- NIST REFPROP问题反馈与解决方案存储库
- 掌握LeetCode习题的系统开源答案
- ctop:实现汉字按首字母拼音分类排序的PHP工具
- 微信小程序课程学习——投资融资类产品说明
- Matlab犯罪模拟器开发:探索《当蛮力失败》犯罪惩罚模型
- Java网上招聘系统实战项目源码及部署教程
- OneSky APIPHP5库:PHP5.1及以上版本的API集成
- 实时监控MySQL导入进度的bash脚本技巧
- 使用MATLAB开发交流电压脉冲生成控制系统
- ESP32安全OTA更新:原生API与WebSocket加密传输
- Sonic-Sharp: 基于《刺猬索尼克》的开源C#游戏引擎
- Java文章发布系统源码及部署教程
- CQUPT Python课程代码资源完整分享
- 易语言实现获取目录尺寸的Scripting.FileSystemObject对象方法
- Excel宾果卡生成器:自定义和打印多张卡片
- 使用HALCON实现图像二维码自动读取与解码
