使用Django与GAE构建智能网页抓取平台
104 浏览量
更新于2024-08-28
收藏 252KB PDF 举报
"本文主要介绍了如何使用Django与Google App Engine (GAE) Python后台来抓取多个网站的页面全文,构建一个智能的网络爬虫平台。该平台名为Moven,旨在过滤并提供优质的博客文章。文章详细描述了实现过程的三个阶段:Downloader、Analyser和Smart Crawler,并分享了一个实际的示例应用——l2zstory.appspot.com,该应用自动同步多个博客站点的内容。"
在构建Moven平台的过程中,首先遇到的是**Downloader阶段**。这一阶段的任务是对指定URL的网页进行下载,并将获取的内容传递给下个阶段。这通常涉及到HTTP请求库的使用,如Python的requests库,用于发送GET请求获取网页HTML内容。
第二阶段是**Analyser**。在这个阶段,我们需要对下载的内容进行处理,通常会使用正则表达式(RegularExpression)、XPath或BeautifulSoup/lxml等工具进行解析和筛选。这些工具可以帮助我们提取出所需的信息,如文章标题、内容、作者和日期等。BeautifulSoup和lxml是Python中常用的HTML和XML解析库,能够方便地遍历和解析文档结构。
第三阶段,也是最复杂的是**Smart Crawler**。在这个阶段,不仅要抓取网页链接,还需要有一个算法来判断抓取的文章是否优质。这可能涉及到文本分析、情感分析、关键词密度计算等自然语言处理技术。Scrapy框架可以用于快速构建爬虫结构,但实现智能判断则需要更高级的算法设计。
文章中提到的示例应用**l2zstory.appspot.com**使用了GAE Python后台,实现了全页面的HTML抓取,特别适用于那些不提供全文RSS或Atom Feed的网站。为了优化性能,内容菜单在客户端使用JavaScript动态生成,减少了服务器端的压力。然而,这导致了页面加载时间较长,因为需要实时抓取所有文章信息。未来计划加入数据存储部分,以提高加载速度。
在技术实现上,前端使用了**CSS**,尤其是简洁的Twitter的**Bootstrap.css**,提供了Grid System以实现响应式布局。同时,选择了**jQuery**作为JavaScript库,用于创建动态的目录系统和其他交互功能。通过这样的组合,可以构建出美观且功能丰富的前端界面。
使用Django与GAE Python后台结合,可以构建一个强大的网络爬虫系统,不仅可以抓取网页内容,还能通过智能分析提供高质量的文章推荐。通过实际应用的示例,我们可以看到这种技术在实现自动化信息聚合和处理中的潜力。
Using Django with GAE Python 后台抓取多个网站的页面全后台抓取多个网站的页面全
文文
一直想做个能帮我过滤出优质文章和博客的平台 给它取了个名 叫Moven。。 把实现它的过程分成了三个阶段:
1. Downloader: 对于指定的url的下载 并把获得的内容传递给Analyser--这是最简单的开始
2. Analyser: 对于接受到的内容,用Regular Expression 或是 XPath 或是 BeautifulSoup/lxml 进行过滤和简化--这部分也不
是太难
3. Smart Crawler: 去抓取优质文章的链接--这部分是最难的:
Crawler的话可以在Scrapy Framework的基础上快速的搭建
但是判断一个链接下的文章是不是优质 需要一个很复杂的算法
最近就先从Downloader 和 Analyser 开始: 最近搭了一个l2z story 并且还有一个 Z Life 和 Z Life@Sina 还有一个她的博客 做
为一个对Downloader 和 Analyser的练习 我就写了这个东西来监听以上四个站点 并且把它们的内容都同步到这个站上:
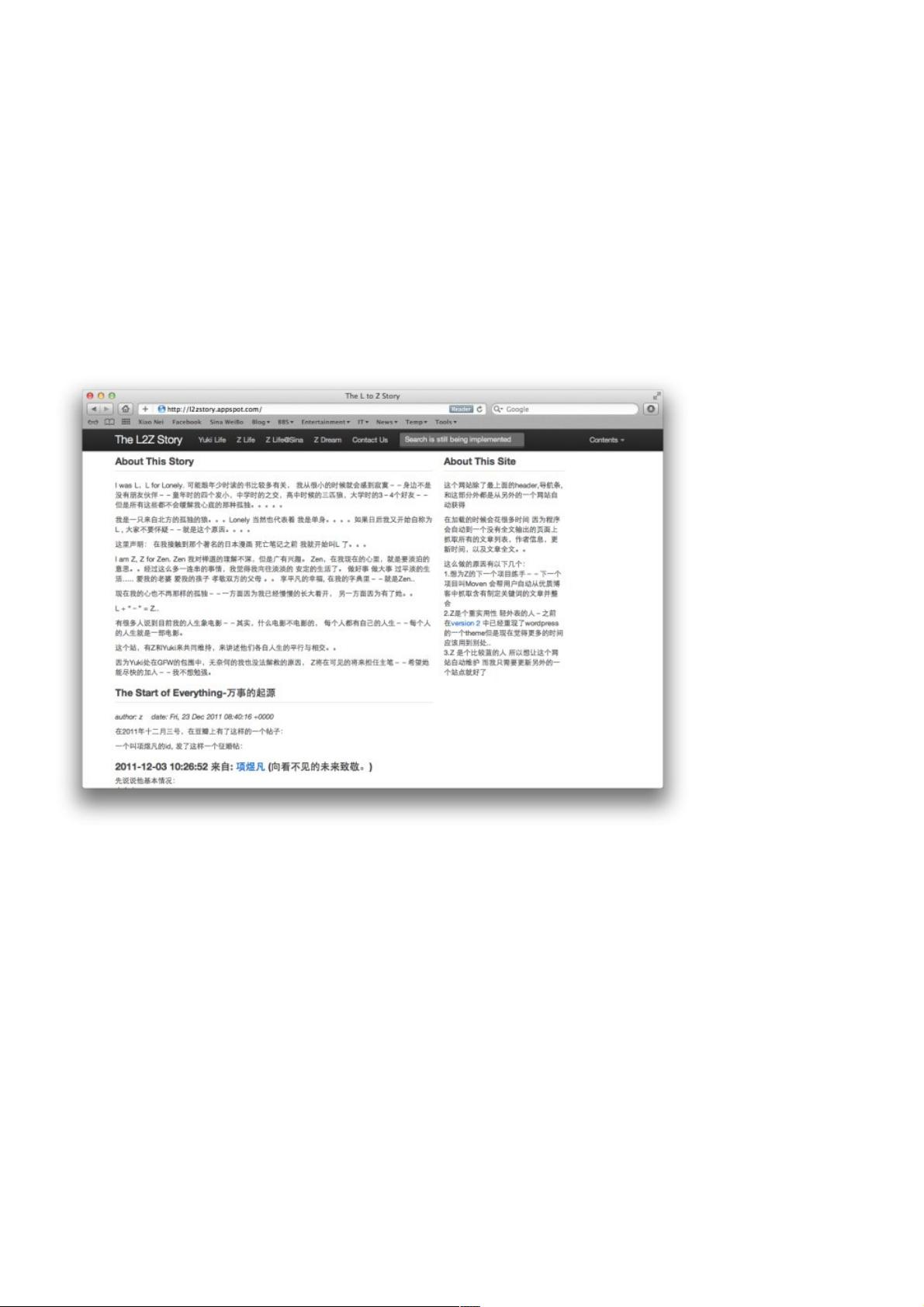
http://l2zstory.appspot.com
App 的特色的特色
这个站上除了最上面的黑色导航条 和 最右边的About This Site 部分外, 其他的内容都是从另外的站点上自动获得
原则上, 可以添加任何博客或者网站地址到这个东西。。。当然因为这个是L2Z Story..所以只收录了四个站点在里面
特点是: 只要站点的主人不停止更新, 这个东西就会一直存在下去---这就是懒人的力量
值得一提的是, Content 菜单是在客户端用JavaScript 自动生成的--这样就节约了服务器上的资源消耗
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-05-05 上传
2023-11-03 上传
2021-02-14 上传
2019-03-17 上传
2021-03-26 上传

weixin_38728624
- 粉丝: 4
- 资源: 881
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
