S7-200SMART间接寻址:冒泡排序子程序与库文件创建教程
版权申诉
在S7-200SMART PLC的编程中,间接寻址是一种高效的数据访问方式,它允许程序员通过一个间接的地址来操作内存中的数据,从而简化代码并提高效率。本文将详细介绍如何利用S7-200SMART PLC的间接寻址技术来实现冒泡排序算法,并将其封装成可重复调用的库文件。
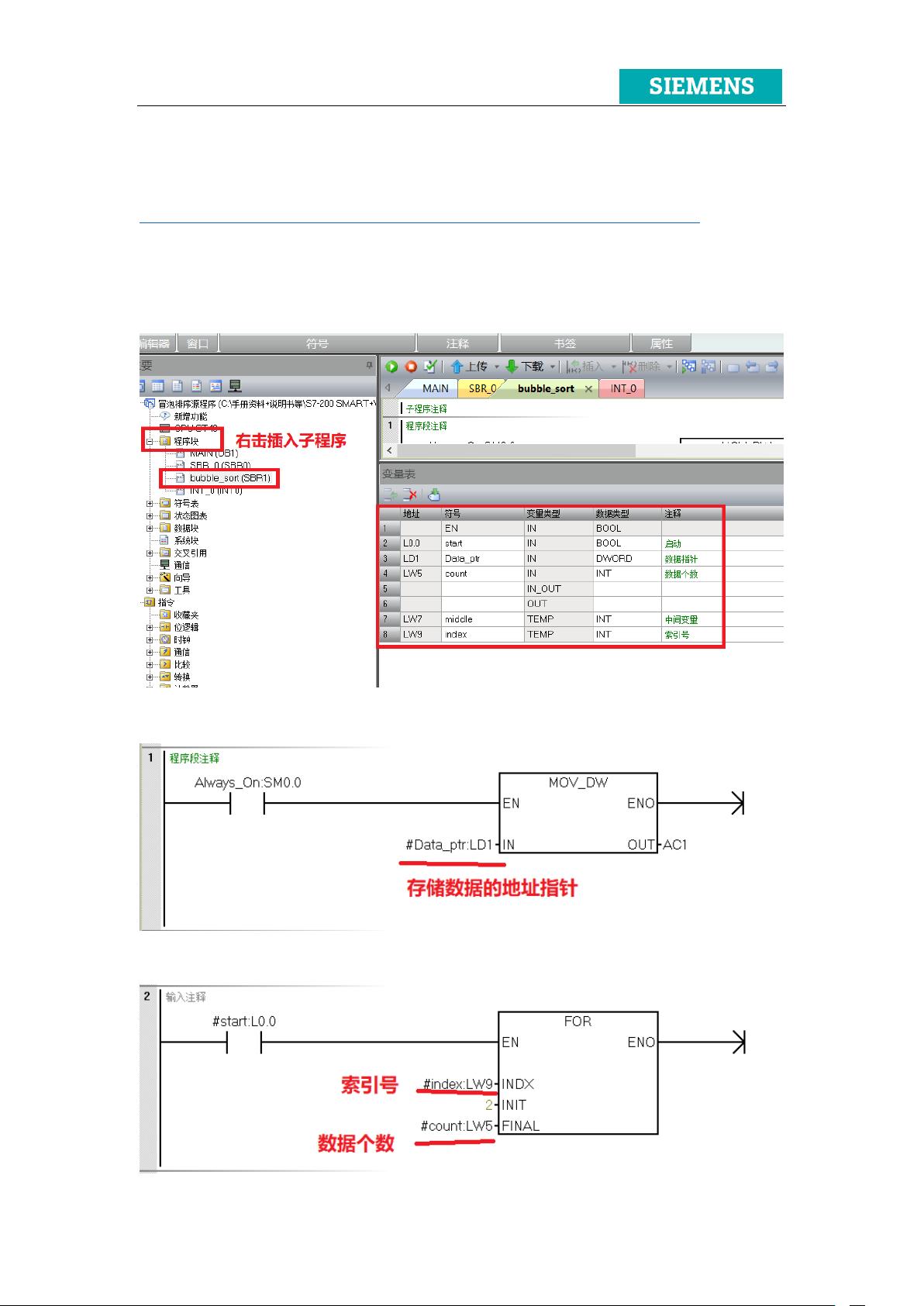
冒泡排序是一种简单的排序算法,通过反复交换相邻未按顺序排列的元素,逐步将最大或最小值“浮”到数组的一端。在S7-200SMART PLC中,实现冒泡排序的关键在于利用间接寻址来处理数组中的元素。首先,我们需要在程序块中创建一个名为bubble_sort的子程序,定义局部变量,如用于存储数据的指针AC1,以及计数器等。
在子程序中,使用FOR循环结构进行遍历。在每次迭代中,通过间接寻址获取存储数据的地址,然后与下一个地址的数据进行比较。如果当前数据大于下一个数据,就交换它们的位置。这个过程会重复进行,直到整个数组按照升序排列。排序完成后,指针地址会自动递增,进入下一轮循环。
为了能够重复调用这个子程序,我们需要将其制作成一个库文件。具体步骤如下:
1. 在项目中创建一个新的子程序,设置好必要的参数,如输入和输出的变量,包括存储数据指针Data_ptr和计数器count。
2. 创建库文件,输入库名和保存路径,然后将子程序添加到库中。
3. 在主程序OB1中,调用bubble_sort子程序,通过指定的管脚连接传递数据指针和数据个数。
4. 完成库文件的创建后,保存并复制库文件到预设的库文件夹。
5. 刷新库文件列表,确认库已成功加载到项目中。
通过这种方式,程序员可以轻松地在不同的程序块中调用这个冒泡排序库,实现对数据的快速排序,无需每次都重新编写相同的排序逻辑。这种设计极大地提高了编程效率,特别适合在需要多次排序操作的工业自动化控制环境中应用。间接寻址的优势在于减少了代码量,提高了程序的可维护性和灵活性。
下载后可阅读完整内容,剩余5页未读,立即下载
515 浏览量
2023-11-07 上传
1464 浏览量
194 浏览量
2196 浏览量
331 浏览量

AAA_自动化工程师
- 粉丝: 7142
- 资源: 3492
 我的内容管理
展开
我的内容管理
展开







最新资源
- 易语言冰雪战歌音乐盒
- Buddy:基于Leancloud无限制的班级管理系统(学生迫害系统)(:wrapped_gift:也是我可爱的英语老师Buddy的圣诞节礼物)
- highline:将 Markdown 文档中的 GitHub 链接转换为代码块
- BinaryRelationPropertyAnalyser
- docker-sample
- 易语言二行代码显示flash
- 作品答辩环境工程系绿色环保模板.rar
- pyfasttext:fastText的另一个Python绑定
- Tanji-crx插件
- ASP+ACCESS学生管理系统(源代码+LW).zip
- 易语言企达鼠标精灵
- 20210806-华创证券-食品饮料行业跟踪报告:餐饮标准化解决方案暨大消费论坛反馈,川调火热东风至,智慧餐厅初萌芽.rar
- weatherapp
- yii2-semantic-ui:Yii2 语义 UI 扩展
- One_Click_Boom-ocb:一键式解决方案,用于设置大数据处理环境。 Installl是所有bash文件所在的父目录。 只需在终端中通过命令“ chmod 777 *”向位于installl目录内的所有bash文件提供权限
- CLAT Guru-crx插件
