文本分类详解:从CNN到BERT的深度学习方法
需积分: 10 111 浏览量
更新于2024-07-15
收藏 4.69MB PDF 举报
文本分类讲义是一份深入介绍自然语言处理(NLP)中一个重要任务的教程,主要集中在利用AI技术对文本进行自动分类。课程由讲师杨博设计,涵盖了卷积神经网络(Convolutional Neural Networks, CNN)、循环神经网络(Recurrent Neural Networks, RNN)等深度学习模型在文本分类中的应用。
首先,课程从文本分类的简介开始,指出它在NLP领域的广泛应用,如情感分析、领域识别和意图识别。这些任务的目标是在给定的预定义类别体系下,对文本进行分类,无论是短文本(如句子、标题或商品评论)还是长文本(如文章)。常见的例子包括新闻分类(如政治、体育等)、情感分析(正面或负面)、以及微博评论的评价类型(好评、中性或差评)。
接下来,文本分类的方法被分为三类:人工方法、机器学习方法和深度学习方法。人工方法依赖于规则匹配和专家系统,但准确性和效率有限;机器学习方法如朴素贝叶斯、支持向量机等结合特征工程,虽然简单但可能受限于特征选择;而深度学习则通过词向量表示(如Word2Vec、FastText)、卷积神经网络(如TextCNN)、循环神经网络(TextRNN)、双向循环神经网络(TextRCNN)、深度金字塔卷积网络(DPCNN)以及更先进的预训练模型BERT来进行特征学习,这些方法在处理复杂语义和上下文关联方面具有优势。
文本分类的流程分为两个主要步骤:预处理和特征提取。预处理阶段包括去除文本噪声、分词、去除停用词、纠正歧义和替换同义词,以提高模型的输入质量。特征提取部分则涉及词频统计、词性标注以及语法特征,这些有助于捕捉文本的局部和全局特征。
总结来说,文本分类讲义提供了一个全面的学习框架,涵盖了从基础概念到实际应用的深度学习模型,这对于理解和实践NLP中的文本分类任务非常有帮助。通过掌握这些技术,学生和从业者能够更好地应对各种文本分类问题,提升文本数据的自动化处理能力。
AI壹号堂
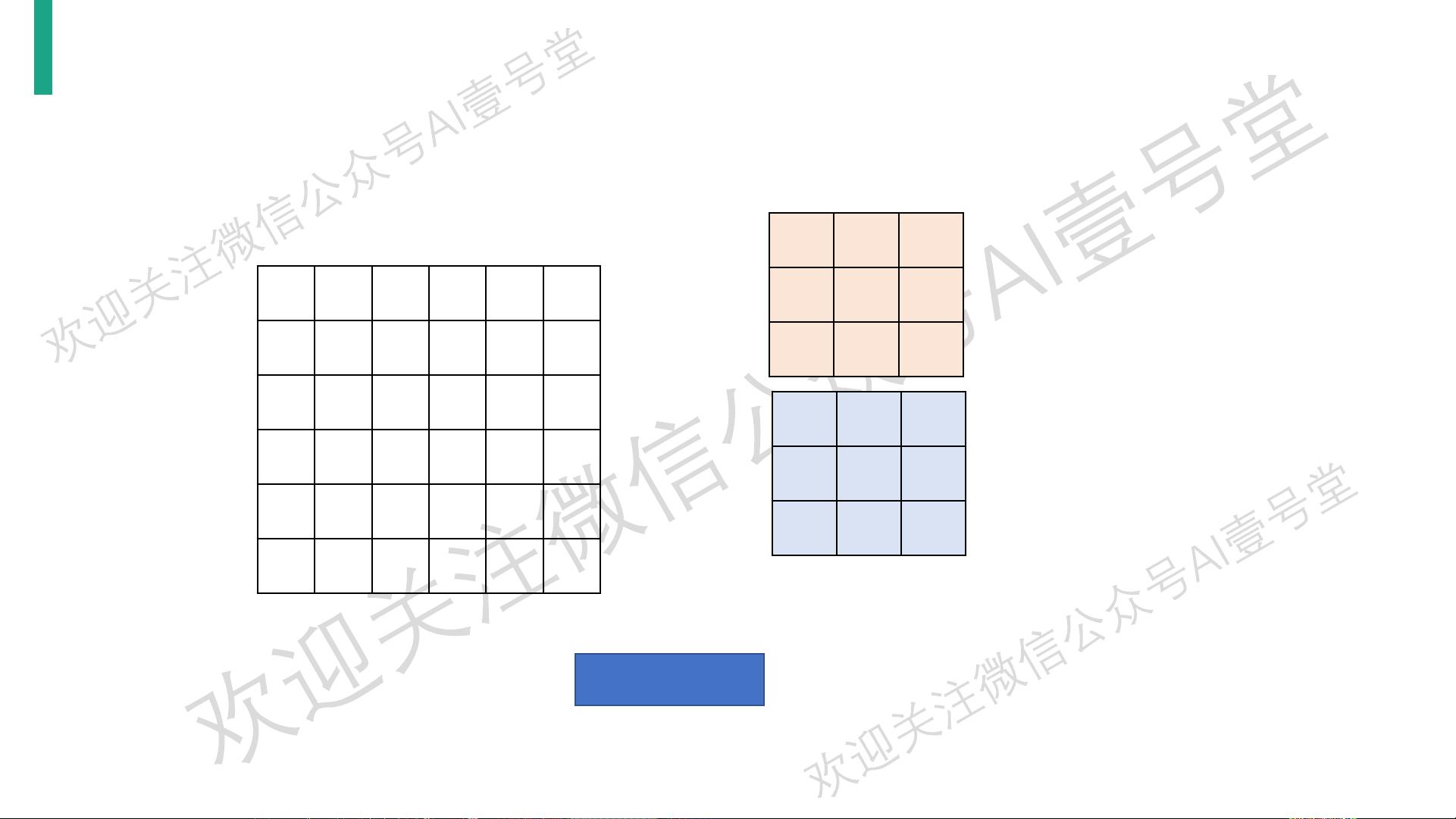
Convolution
Max Pooling
Convolution
Max Pooling
Flatten
可以
重复
多次
一些明显的特征远小于
整个图片
同样的特征可以出现在图
像不同的区域
二次采样不会改变图像
原本面貌
第一个特性
第二个特性
第三个特性
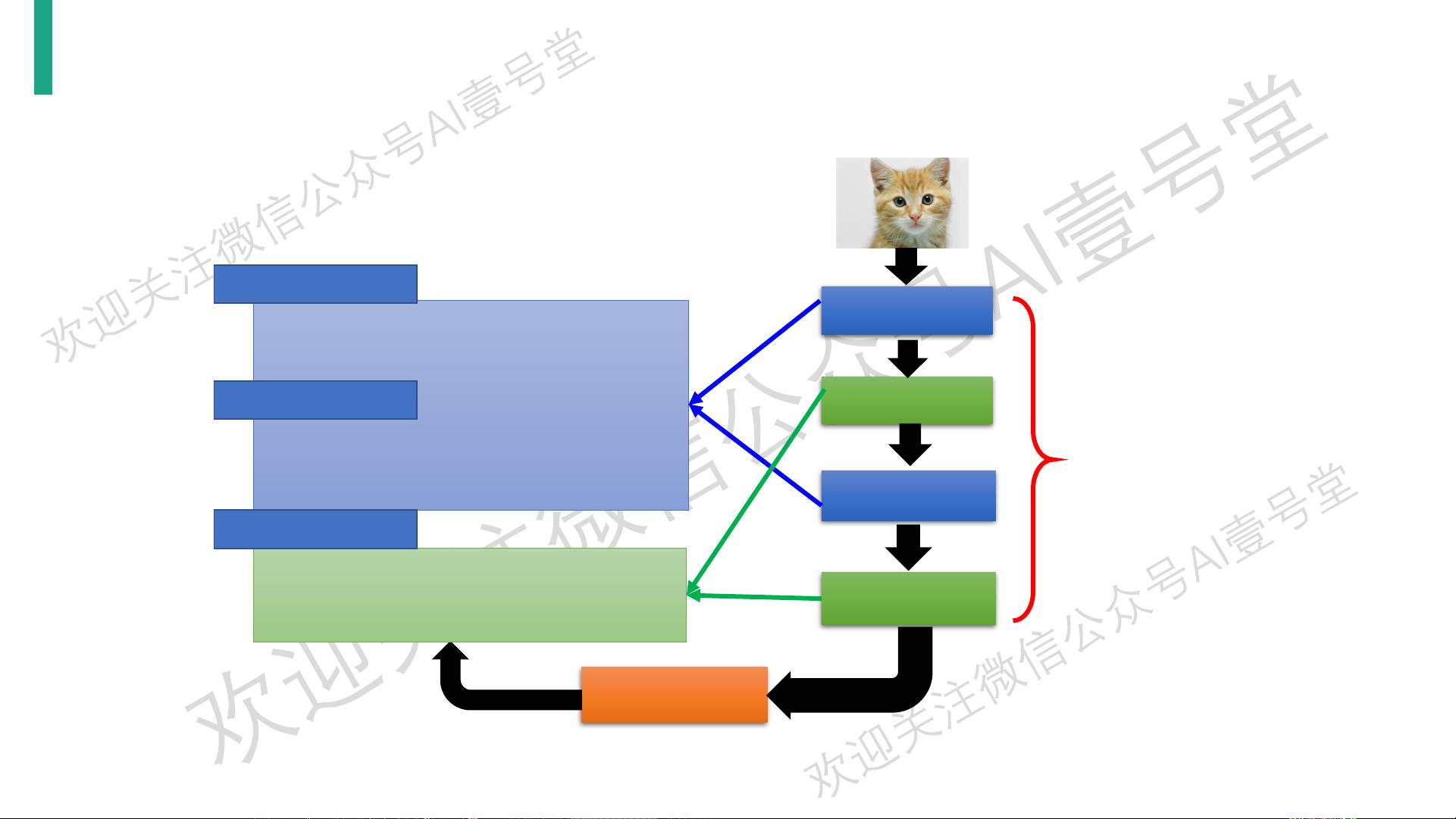
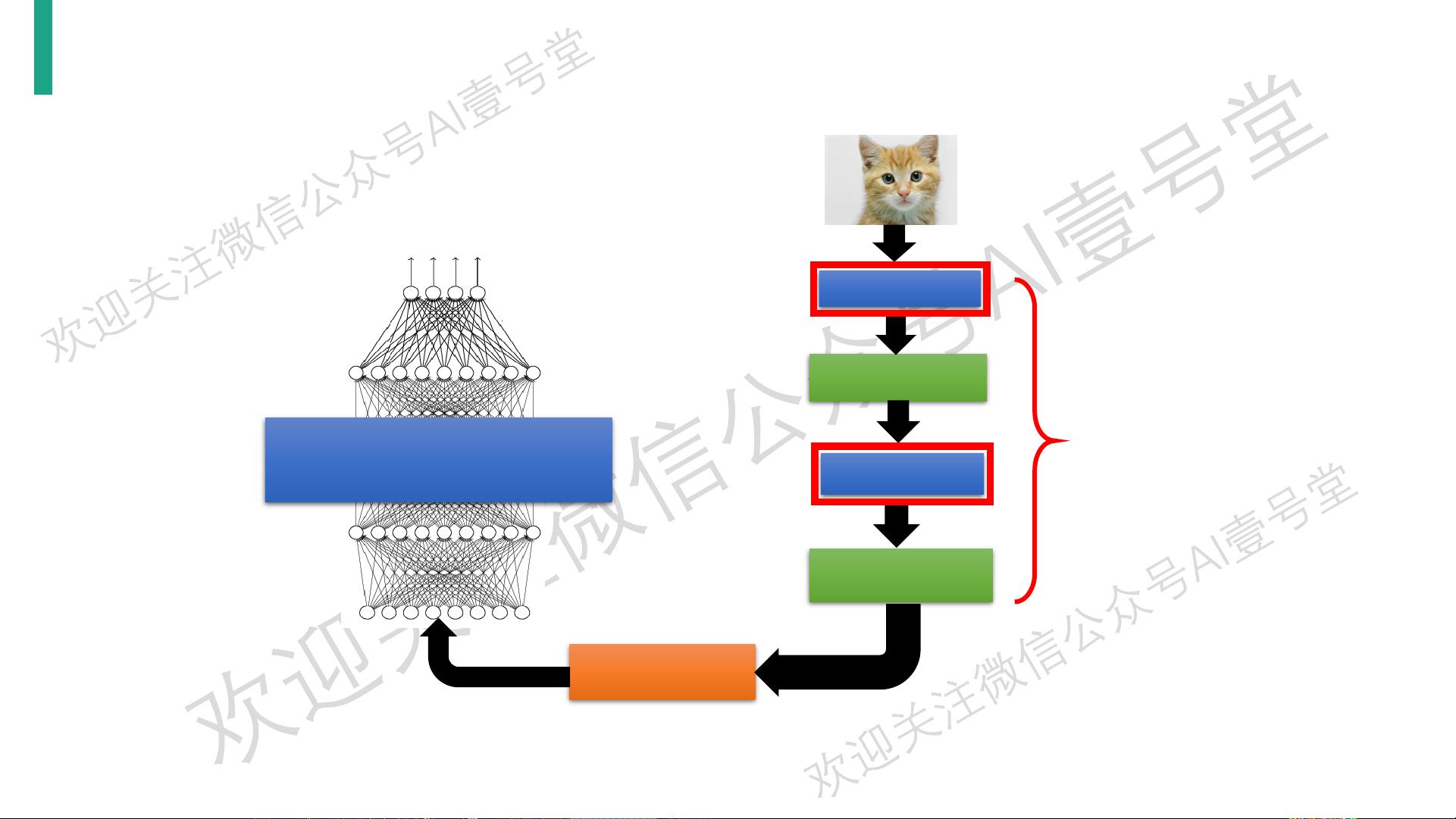
CNN整体流程
剩余68页未读,继续阅读
2021-03-11 上传
2024-01-31 上传
2023-02-14 上传
2021-09-19 上传
2019-10-26 上传
2021-10-12 上传
2021-11-14 上传
2021-08-17 上传

公子茗
- 粉丝: 13
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Moodle-Mobile-User-Tracking:USQ + ANU + Unisa
- 在线海报图片设计器、图片编辑器源码/仿照稿定设计源码
- dots:我的点文件的集合
- ImageComparison:比较两个图像并将其相似度评定为(0-100)
- doxdocgen:从VS Code中的源代码生成doxygen文档
- Vote-en-ligne
- c代码-Customer Credit
- mc_bid
- embedhttp:小型,灵活且安全的Java HTTP服务器,可以轻松地嵌入到应用程序中
- 美萍培训班管理系统标准版
- 阿祖雷波克
- ts-todo
- WAND-PIC:WAND-PIC
- FPSD:Arduino的五相步进驱动器
- huTools:参见主仓库@mdornseif
- analytics_webinar:7142015 Analytics网络研讨会的资料
